










分位数(Quantile),亦称分位点,是指将一个随机变量的概率分布范围分为几个等份的数值点,常用的有中位数(即二分位数)、四分位数、百分位数等。
任意一个累计分布函数 F ( x ) F(x) F(x) ,满足 F ( x ^ ) = σ , σ ∈ ( 0 , 1 ) F(\hat{x}) = \sigma, \sigma\in (0,1) F(x^)=σ,σ∈(0,1) 的 x ^ \hat{x} x^,称为分布 F F F 的分位数。
σ \sigma σ 的含义是该分布中小于 x ^ \hat{x} x^的数占比为 σ \sigma σ,即 P ( x < x ^ ) = σ P(x<\hat{x}) = \sigma P(x<x^)=σ。
给定一个平稳时间序列,我们通常为考虑回归出它的均值。但在更一般的情况下,我们希望回归出样本对应分布的分位点,因为分位点更能反映出分布的性质。
下面用一个例子来说明:
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
gauss = [np.random.randn() for _ in range(100)]
plt.plot(gauss)
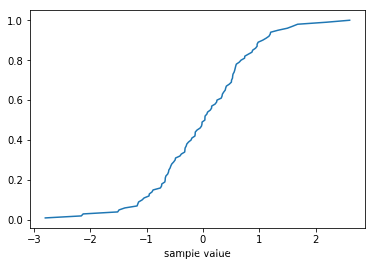
可以直接画出经验概率分布函数
from statsmodels.distributions.empirical_distribution import ECDF
cdf = ECDF(gauss)
plt.plot(cdf.x, cdf.y, label = "statmodels")
plt.xlabel('sample value')
在概率分布函数上找分位点太容易了,在纵轴上确定
σ
\sigma
σ,回到横轴上找
x
^
\hat{x}
x^
基于梯度下降的分位点回归
在一般的时间序列预测问题中,我们通常是用一个函数取拟合序列,通常学习到的函数是对真实样本均值的估计。
有没有办法让学习函数去逼近真实样本的分位点呢?
只需要使用如下损失函数:
L
(
y
,
y
^
)
=
σ
max
(
y
−
y
^
,
0
)
+
(
1
−
σ
)
max
(
y
^
−
y
,
0
)
L(y,\hat{y}) = \sigma\max (y-\hat{y},0) + (1-\sigma)\max(\hat{y}-y,0)
L(y,y^)=σmax(y−y^,0)+(1−σ)max(y^−y,0)
∂
L
(
y
,
y
^
)
∂
y
^
=
−
σ
I
(
y
−
y
^
)
+
(
1
−
σ
)
I
(
y
^
−
y
)
\frac{\partial L(y,\hat{y})}{\partial \hat{y}} = -\sigma\mathbb{I(y-\hat{y})} + (1-\sigma)\mathbb{I(\hat{y}-y)}
∂y^∂L(y,y^)=−σI(y−y^)+(1−σ)I(y^−y)
其中
y
^
\hat{y}
y^ 是输出,
y
y
y 为目标值。
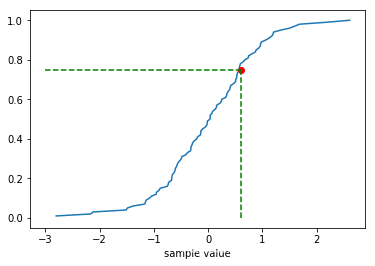
rho = 0.75
def grad(rho, z, ze):
return -rho if ze <= z else 1-rho
ze = 0
lr = 0.1
for z in gauss:
ze -= lr*grad(rho, z, ze)
cdf = ECDF(gauss)
plt.plot(cdf.x, cdf.y, label = "statmodels")
plt.plot(ze, rho, 'ro')
plt.plot([-3, ze],[rho, rho],'g--')
plt.plot([ze, ze],[0, rho],'g--')
plt.xlabel('sample value')
rho = 0.1
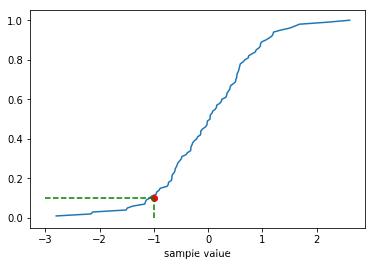
可以看出,提出下降法很好地找到了序列的分位点,和直接用概率分布函数的结果一致。


















 1005
1005

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











