









文章目录
1. 论文总述
最近开始做基于深度学习的光流估计,本文的FlowNet应该是必须了解的,这是2015年的一篇文章,网络结构比较简单,就是基于类似语义分割的形式直接让网络输出dx dy;另外还有个大贡献,就是作者合成了一个经典的用来训练CNN的光流数据集: FlyingChairs,现在也仍然在用!!
由于工作以后,闲暇时间比较少,博客只能回家找时间写,所以就能省就省了。
有2篇博客针对FlowNet写的比较好,这里就不重复了,就只写我自己看论文时候的勾勾画画了,参考博客1,参考博客2
Optical flow estimation has not been among the tasks CNNs succeeded at. In
this paper we construct CNNs which are capable of solving
the optical flow estimation problem as a supervised learning
task. We propose and compare two architectures: a generic
architecture and another one including a layer that correlates feature vectors at different image locations. Since
existing ground truth data sets are not sufficiently large to
train a CNN, we generate a large synthetic Flying Chairs
dataset. We show that networks trained on this unrealistic
data still generalize very well to existing datasets such as
Sintel and KITTI, achieving competitive accuracy at frame
rates of 5 to 10 fps.
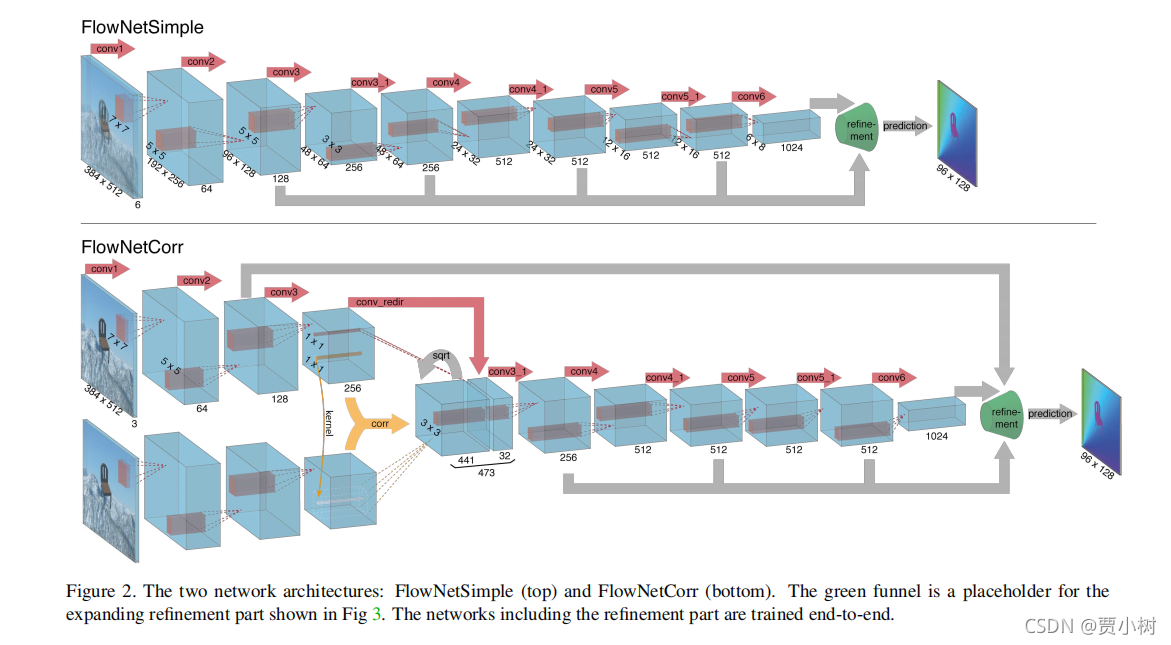
2. FlowNetS结构的背后原因
Since it was not clear whether this task could be solved
with a standard CNN architecture, we additionally developed an architecture with a correlation layer that explicitly
provides matching capabilities. This architecture is trained
end-to-end. The idea is to exploit the ability of convolutional networks to learn strong features at multiple levels of
scale and abstraction and to help it with finding the actual
correspondences based on these features. The layers on top
of the correlation layer learn how to predict flow from these
matches. Surprisingly, helping the network this way is not
necessary and even the raw network can learn to predict optical flow with competitive accuracy.
但是 FlowNet2 证明:这个相关层是必须的!
3. 相关层
However, given feature representations of two
images, how would the network find correspondences?

相关层:两个image patch相互卷积,并没有可以训练的卷积核,即没有参数。
4. Variational refinement(变分优化)

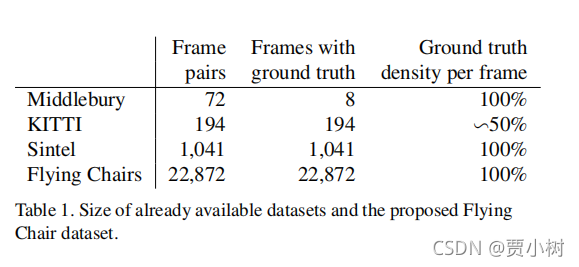
5. 数据集介绍
首先说明一点:光流估计数据集很难做,对设备要求很高,因为光流估计的GT是两帧图像对应像素的dx dy,手工标注都很难!!!
但是训练CNN又需要大量的数据,所以作者自己合成了一个数据集,对某一帧图像进行变换(参数已知),然后得到第二帧图像,同时光流GT也可以直接得到,完美!就是可能和真实数据集还是有点区别。
1)Middlebury数据集
用于训练的图片对只有8对,从图片对中提取出的,用于训练光流的 ground truth 用四种不同的技术生成,位移很小,通常小于10个像素。
2)Kitti数据集
有194个用于训练的图片对,但只有一种特殊的动作类型,并且位移很大,视频使用一个摄像头和 ground truth 由3D激光扫描器得出,远距离的物体,如天空没法被捕捉,导致他的光流 ground truth 比较稀疏。
3)Mpi sintel数据集
是从人工生成的动画sintel中提取训练需要的光流 ground truth,是目前最大的数据集,每一个版本都包含1041个可一用来训练的图片对,提供的gt十分密集,大幅度,小幅度的运动都包含。
sintel数据集包括两种版本:
sintel final:包括运动模糊和一些环境氛围特效,如雾等。
sintel clean:没有上述final的特效。
4)Flying Chairs数据集
用于训练大规模的cnns,sintel的dataset依然不够大,所以作者他们自己弄出来一个flying chairs数据集。

如图 所示,这一数据集背景是来自flickr的图片,剪切成四分之一,用512*384作为背景,前景是生成的3d椅子模型,从这些模型中去掉一些相似的椅子模型,留下809种椅子,每一种有62个视角。
为了产生运动信息,产生第一张图片的时候会随机产生一个位移变量,与背景图片与椅子位移相关, 再通过这种位移变量产生第二个图片和光流。每一个图像对的这些变量,包括,椅子的类型,数量,大小,和产生的位置都是随机的,位移向量也是随机的产生的。(随机变换出的displacement 的直方图和sintel是比较像的!!)
尽管flying-chair数据集已经很大,但是为了避免过拟合,而采用了data Augmentation 的方法,让数据扩大,样式变多,不单调,防止分类变得严格。
5)Flying Things3D 数据集

在 FlowNet2.0 中,又生成并引入了另外一个数据集 Flying Things3D ,如图 8 所示,由一堆会飞的三维图形组成,更加接近于现实,有22000对图像。
如下:
6. 光流可视化
光流的输出是dx dy,为了更好的与GT对比,需要将其可视化,其实是2通道的光流map转到hsv 进行可视化,具体看下面参考博客的介绍:
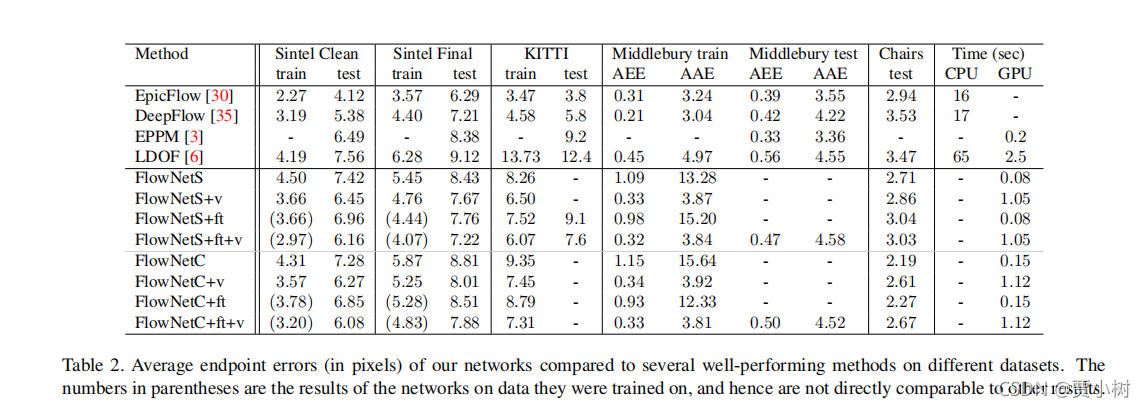
7. 模型指标对比
参考文献(重要!)
3. 图像处理中的全局优化技术(Global optimization techniques in image processing and computer vision) (三)(主要是介绍变分优化)
4. 光流Optical Flow介绍与OpenCV实现(光流可视化的C++代码)














 8522
8522











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









