







1、softmax损失函数
它是一个多分类问题,预测结果在[0-1]之间

import torch
import torch.nn.functional as F
def auto_softmax(x):
x_exp = torch.exp(x)
return x_exp / torch.sum(x_exp, dim=1, keepdim=True)
def true_softmax(x):
# dim=1表示对每个样本在所有特征上进行softmax操作,而dim=0表示对每个特征在所有样本上进行softmax操作
output = F.softmax(x, dim=1)
return output
demo = torch.tensor([[1., 4, 8, 6], [5., 2., -1., 3.]])
out01 = auto_softmax(demo)
out02 = true_softmax(demo)
print(out01)
print(out02)
2、分类任务
在深度学习中,损失函数是用来衡量模型参数的质量函数,衡量的方式是比较网络输出和真实输出的差异,损失函数在不同的文献中名称是不一样的,主要有以下几种命名方式:损失函数、代价函数、目标函数和误差函数。损失函数在分类问题中,分为多分类任务和二分类任务的损失函数;在回归问题中,分为MAE损失、MSE损失和smooth L1损失。

2.1、多分类任务
在多分类任务中通常使用softmax激活函数将logits转换为概率的形式,所以多分类的交叉熵损失也叫做softmax损失,计算方法是:



import torch
import torch.nn as nn
import torch.nn.functional as F
"""
多分类交叉熵损失函数加上softmax后可以转化为PyTorch中的nn.CrossEntropyLoss()函数的公式。
"""
def auto_cross(output, target):
# 对模型输出进行softmax归一化
output = F.softmax(output, dim=1)
# 计算交叉熵损失
loss = -torch.sum(target * torch.log(output), dim=1) # 每行损失
# 对每个样本的损失取平均
loss = torch.mean(loss)
return loss
def true_cross1(y_pred, y_true):
# 使用交叉熵损失函数计算损失
criterion = nn.CrossEntropyLoss(reduction='mean')
loss = criterion(y_pred, torch.argmax(y_true, dim=1))
return loss
def true_cross2(y_pred, y_true):
criterion = nn.CrossEntropyLoss()
loss = criterion(y_pred, y_true)
return loss
# 假设有3个样本,每个样本有4个类别
y_pred = torch.tensor([[0.121, 0.434, 0.2, 0.3343],
[0.3, 0.342, 0.6, 0.123],
[5, 2, -1, 3]])
y_true1 = torch.tensor([[0, 1, 0, 0],
[1, 0, 0, 0],
[0, 0, 0, 1]])
y_true2 = torch.tensor([1, 0, 3])
# 【1】
loss1 = true_cross1(y_pred, y_true1)
print(loss1)
# 【2】
loss2 = true_cross2(y_pred, y_true2)
print(loss2)
# 【3】
loss3 = auto_cross(y_pred, y_true1)
print(loss3)
2.2、二分类任务
在二分类任务中通常使用sigmoid激活函数,二分类的交叉熵损失函数如下:

探究下公式怎么得来的,如下图所示:

多样本的二分类交叉熵损失函数公式:
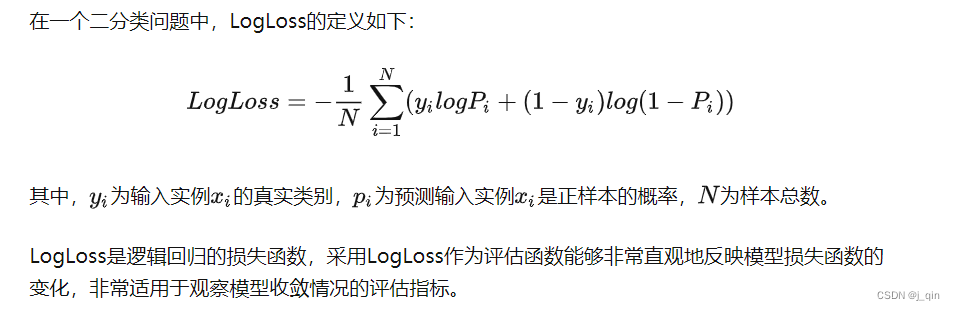
多样本的二分类交叉熵损失函数代码:
import numpy as np
from sklearn.metrics import log_loss
import numpy as np
def binary_cross_entropy(y_true, y_pred):
epsilon = 1e-15
y_pred = np.clip(y_pred, epsilon, 1 - epsilon) # 限制概率值的范围,避免log(0)的情况
return -np.mean(y_true * np.log(y_pred) + (1 - y_true) * np.log(1 - y_pred))
# 方式一:
y_true = np.array([0, 1, 1, 0])
y_pred = np.array([0.1, 0.9, 0.8, 0.3])
loss = log_loss(y_true, y_pred)
print("Binary Log Loss:", loss)
# 方式二:
loss = binary_cross_entropy(y_true, y_pred)
print("Binary Cross-Entropy Loss:", loss)
3、回归任务
在回归任务中有三种损失函数
3.1、MAE损失
MAE损失图像中可知,最大的问题是梯度在0点不平滑,导致会跳过极小值。

3.2、MSE损失
MSE损失图像中可知,当预测值和目标值相差很大时,梯度容易爆炸。

3.3、smooth L1损失
该损失是上述两种的结合,在图像中L1是MAE损失,L2是MSE损失。从图形中可以看出,该函数其实就是一个分段函数,在[-1,1]之间实际上就是L2损失,这样就解决了L1不光滑的问题。在[-1,1]区间外就是L1损失,这样就解决了离群点梯度爆炸的问题。通常在目标检测中使用该损失函数。
















 1921
1921











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









