







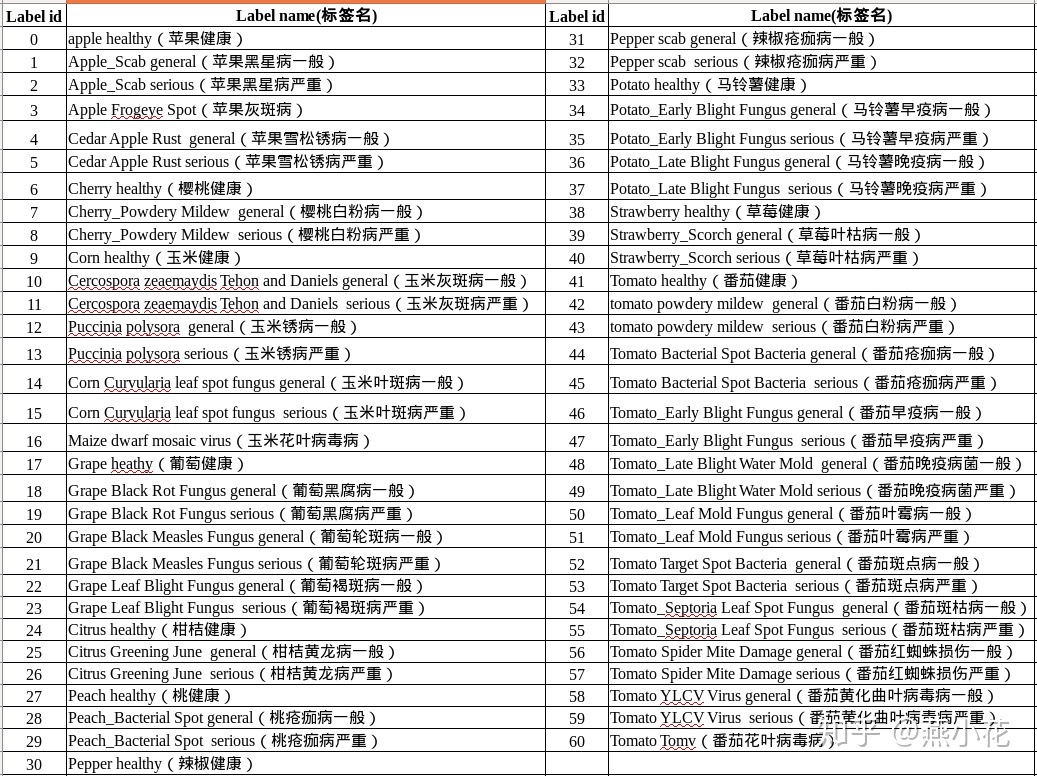
最近看论文发现有使用植物病害程度来做实验的,查了一下,这个数据集是AI challenger在2018年的一个比赛,是将plant village的数据集,根据不同的病害程度来划分种类。
AI challenger病害程度数据集,开始我没有找到每个标签的信息,就自己分文件夹,对照plant village数据集来自己打的标签(因为有些图片的命名和原plant village数据集的命名是一样的,所以能够直接搜文件名看再哪个文件夹里),自己总结了一圈下来,又再网上找到了一个标签信息表,但是发现其中有些信息是错误的!也就是比赛数据的种类就分错了,虽然这个对分类是没什么影响的,但是如果用这个数据集做叶片分类的话就有影响了呀~下面说一下哪里错误
首先说一下知乎上的信息:
2018ai_challenger之农作物病害检测比赛总结 - 燕小花的文章 - 知乎 2018ai_challenger之农作物病害检测比赛总结 - 知乎
先来说下数据集的大概情况,官方前后总共发布了两次比赛数据集.第一次数据集有很多图像存在标签交叉的情况(即相同的图像存在不同的标签,特别是病害程度一般和严重存在交叉情况),训练图像总数为32768张,验证图像总数为4992张,测试集A图像总数为4959张;因为比赛社区很多人反馈数据交叉的现象,官方在比赛的又发布了第二次比赛数据,第二次发布的数据是对存在标签交叉部分的进行更新,训练图像总数为31718张,验证图像总数为4540张,测试集A图像总数为4514张,测试集B图像总数为4513张.
作者:燕小花
链接:https://zhuanlan.zhihu.com/p/50178745
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
我下载的数据集是第一次和第二次的数据集都有。整理第一次数据集的时候我还纳闷呢,为啥有几个类是重复的数据。后来第二个数据集把重复的去掉了。也就是标签44,45的训练集测试集都变成了一张图(44,45和标签52,53重复!)
但是第二次数据集依然没有解决三个问题:1、就是标签33,详细信息上说它是马铃薯健康叶,但其实是大豆的健康叶。而原数据集其实是有马铃薯健康叶的(不知道为什么会犯这种错误)2、标签42,43是南瓜的白粉病,却被归类到番茄的白粉病!3、标签16说是玉米花叶病,但是图片是玉米的健康叶片,不同的是16里的图片属于plant village数据集,是实验室采集图,而9是在田里采集的图,而且有的还虚焦了很模糊。
以上就是我对AI challenger这个病害数据集的质疑了~有没有同样有疑惑的小伙伴呢?
下面对数据集的下载地址,和对数据集的整理代码进行说明。
数据集在AI Challenger 2018 农作物病害细粒度分类-----Pytorch 深度学习实战_1只小包子的博客-CSDN博客这个博主的文末给出了百度云网盘,有训练集验证集和测试集,测试集没有标签,所以自己实验用的话只能使用训练集和验证集了。
根据python操作json文件、创建文件夹、复制文件的相关博客,写了本文的代码来处理数据,参考博客分别是:
python数据分析之json文件:python数据分析之json文件_带你去网吧里偷耳机的博客-CSDN博客
python创建文件和文件夹:python创建文件和文件夹_凶残的小兵的博客-CSDN博客_python创建文件夹
Python文件名匹配,文件复制:Python文件名匹配,文件复制_YDQN的博客-CSDN博客
以训练集文件夹为例,先说一下目录结构
——ai_challenger_pdr2018_trainingset_20181023
————AgriculturalDisease_trainingset
——————images
——————AgriculturalDisease_train_annotations
在AgriculturalDisease_trainingset文件夹下创建一个新的class文件夹和一个demo.py文件
——ai_challenger_pdr2018_trainingset_20181023
————AgriculturalDisease_trainingset
——————images
——————AgriculturalDisease_train_annotations
——————class
——————demo.py
下面在demo.py文件中写入一下代码运行:
import json
import os
import shutil
def mkdir(path):
folder = os.path.exists(path)
if not folder: #判断是否存在文件夹如果不存在则创建为文件夹
os.makedirs(path) #makedirs 创建文件时如果路径不存在会创建这个路径
#print("--- new folder... ---")
# print("--- OK ---")
#else:
#print("--- There is this folder! ---")
source_dir='./images/'
img=os.listdir(source_dir) #得到文件夹下所有文件名称
with open("AgriculturalDisease_train_annotations.json",'r') as load_f:
load_dict = json.load(load_f)
#print(load_dict)
for pop_dict in load_dict:
path="./class/"+str(pop_dict['disease_class'])
mkdir("./class/"+str(pop_dict['disease_class'])) #根据类别创建文件夹
#print(path)
for fileNum in img:
if not os.path.isdir(fileNum): #判断是否是文件夹,不是文件夹才打开
if fileNum == pop_dict['image_id']:
print(fileNum) #打印出文件名
imgname= os.path.join(source_dir,fileNum)
shutil.copy(source_dir+fileNum,path) #复制蹄片到class文件夹

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









