







 超级会员免费看
超级会员免费看
官方教程(英文):
https://pytorch.org/docs/stable/quantization.htmlpytorch.org
官方教程(中文):
https://pytorch.apachecn.org/docs/1.4/88.htmlpytorch.apachecn.org
目前很多高精度的深度学习模型所需内存、计算量和能耗巨大,并不适合部署在一些低成本的嵌入式设备中,为了解决这个矛盾,模型压缩技术应运而生,其主要是通过减少原始模型参数的数量或比特数来实现对内存和计算需求的降低,从而进一步降低能耗。目前性能最稳定的就是INT8的模型量化技术,相对于原始模型的FP32计算相比,INT8量化可将模型大小减少 4 倍,并将内存带宽要求减少 4 倍,对 INT8 计算的硬件支持通常快 2 到 4 倍。 值得注意的是量化主要是一种加速前向推理的技术,并且绝大部分的量化算子仅支持前向传递。
注:目前PyTorch的量化工具仅支持1.3及以上版本。
应用范围
数据类型:
- weight的8 bit量化 :data_type = qint8,数据范围为[-128, 127]
- activation的8 bit量化:data_type = quint8,数据范围为[0, 255]
bias一般是不进行量化操作的,仍然保持float32的数据类型,还有一个需要提前说明的,weight在浮点模型训练收敛之后一般就已经固定住了,所以根据原始数据就可以直接量化,然而activation会因为每次输入数据的不同,导致数据范围每次都是不同的,所以针对这个问题,在量化过程中专门会有一个校准过程,即提前准备一个小的校准数据集,在测试这个校准数据集的时候会记录每一次的activation的数据范围,然后根据记录值确定一个固定的范围。
支持后端:
- 具有 AVX2 支持或更高版本的 x86 CPU:fbgemm
- ARM CPU:qnnpack
通过如下方式进行设置:
q_backend = "qnnpack" # qnnpack or fbgemm
torch.backends.quantized.engine = q_backend
qconfig = torch.quantization.get_default_qconfig(q_backend) 打印输出可得:
QConfig(activation=functools.partial(<class 'torch.quantization.observer.HistogramObserver'>, reduce_range=False),
weight=functools.partial(<class 'torch.quantization.observer.MinMaxObserver'>, dtype=torch.qint8, qscheme=torch.per_tensor_symmetric))可以看出qnnpack 的量化方式:activation量化的数据范围是通过记录每次运行数据的最大最小值的统计直方图导出的,weight为per-layer的对称量化,整型数据范围为[-128,127],直接用最后收敛的浮点数据的最大最小值作为范围进行量化,其他信息仅从这个打印信息暂时还得不到。
量化方法
- Post Training Dynamic Quantization:这是最简单的一种量化方法,Post Training指的是在浮点模型训练收敛之后进行量化操作,其中weight被提前量化,而activation在前向推理过程中被动态量化,即每次都要根据实际运算的浮点数据范围每一层计算一次scale和zero_point,然后进行量化;
- Post Training Static Quantization:第一种不是很常见,一般说的Post Training Quantization指的其实是这种静态的方法,而且这种方法是最常用的,其中weight跟上述一样也是被提前量化好的,然后activation也会基于之前校准过程中记录下的固定的scale和zero_point进行量化,整个过程不存在量化参数(scale和zero_point)的再计算;
- Quantization Aware Training:对于一些模型在浮点训练+量化过程中精度损失比较严重的情况,就需要进行量化感知训练,即在训练过程中模拟量化过程,数据虽然都是表示为float32,但实际的值的间隔却会受到量化参数的限制。
至于为什么不在一开始训练的时候就模拟量化操作是因为8bit精度不够容易导致模型无法收敛,甚至直接使用16bit进行from scrach的量化训练都极其容易导致无法收敛,不过目前已经有了一些tricks去缓解这个问题,但不在本文讨论之列。
量化流程
以最常用的Post Training (Static) Quantization为例:
- 准备模型:准备一个训练收敛了的浮点模型,用QuantStub和DeQuantstub模块指定需要进行量化的位置;
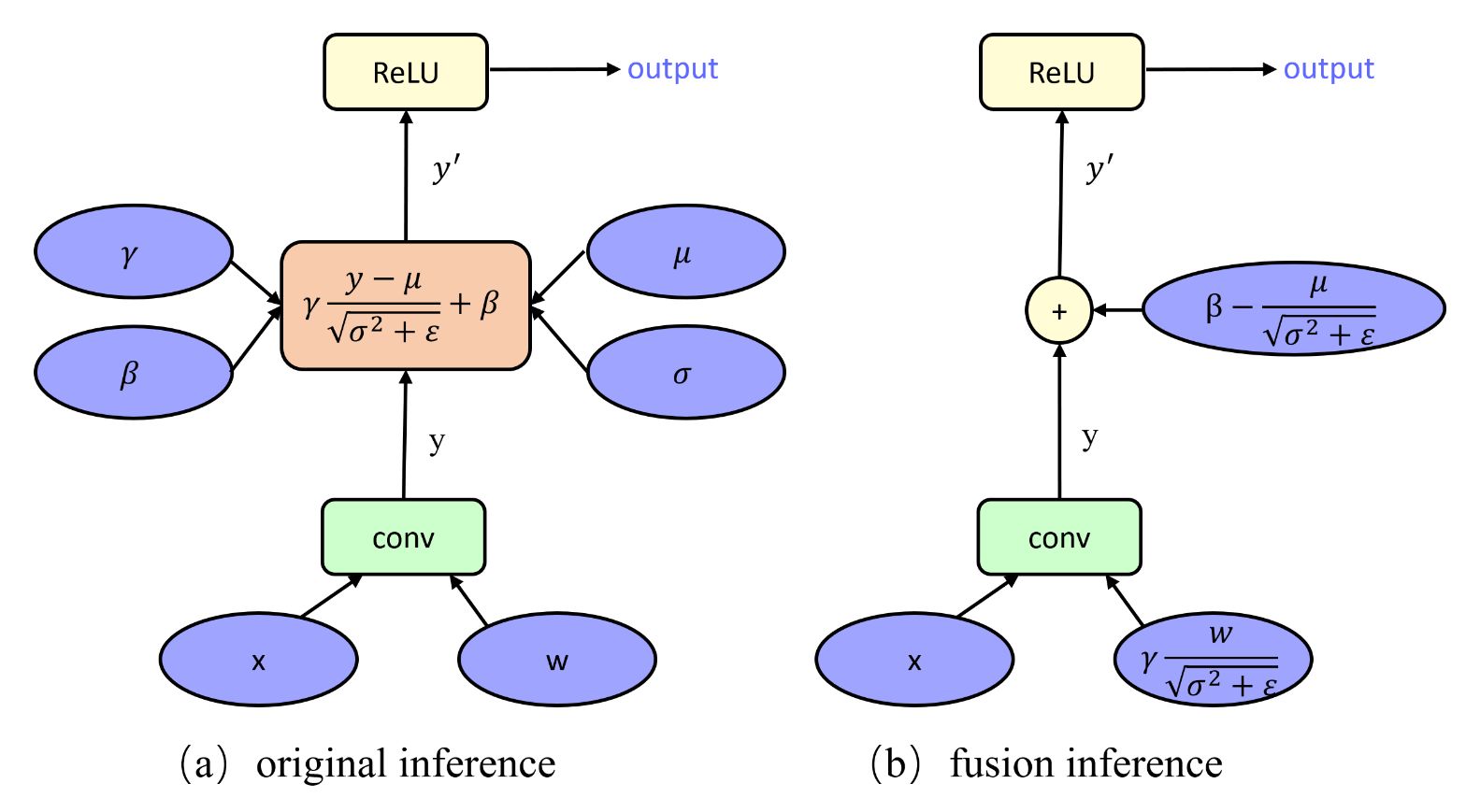
2. 模块融合:将一些相邻模块进行融合以提高计算效率,比如conv+relu或者conv+batch normalization+relu,最常提到的BN融合指的是conv+bn通过计算公式将bn的参数融入到weight中,并生成一个bias;
3. 确定量化方案:这一步需要指定量化的后端(qnnpack/fbgemm/None),量化的方法(per-layer/per-channel,对称/非对称),activation校准的策略(最大最小/移动平均/L2Norm(这个不太清楚,是类似TensorRT的校准方式吗???));
4. activation校准:利用torch.quantization.prepare() 插入将在校准期间观察激活张量的模块,然后将校准数据集灌入模型,利用校准策略得到每层activation的scale和zero_point并存储;
5. 模型转换:使用 torch.quantization.convert()函数对整个模型进行量化的转换。 这其中包括:它量化权重,计算并存储要在每个激活张量中使用的scale和zero_point,替换关键运算符的量化实现;
量化工具
- torch.quantization:最基础的量化库,里面包含模型直接转换函数torch.quantization.quantize,量化训练函数torch.quantization.quantize_qat,准备校准函数torch.quantization.prepare等一系列工具
- quantize_per_tensor():per-ayer量化,需要手动指定scale, zero_point和数据类型dtype;
- quantize_per_channel():per-channel量化,除了需要指定上述三个参数之外,还需要额外指定执行per-channel量化的维度;
- torch.nn.intrinsic.quantized:提供了很多已经融合好的模块,如ConvBn2d,ConvBnReLU2d,直接对这些模型进行量化
- 其余的如torch.nn.quantized,torch.nn.quantized.functional......
Quantization-Aware Training相关模块
- torch.nn.qat:支持全连接和二维卷积操作;
- torch.nn.intrinsic.qat:对融合好的层进行量化训练;
- torch.nn.qat:可以实现在float32数据中模仿量化的操作,即量化+反量化折腾一下;
总结
以上这些工具感觉是不同团队做的,有点冗余和混乱,使用上不是很(非常不)友好,限制很多,而且整套量化过程手动部分比较多,每换一个模型都需要事先对模型的细节了解非常清楚,包括需要进行融合模块的名字。然而实际生产过程需要的是一套可以针对特定硬件平台自动进行量化,并且结合相应的深度学习编译器进行优化,最终部署到移动端/嵌入式设备中,在保证精度要求的前提下有加速效果(最好能达到实时)。之前因为组里的项目需要也自己写了一套自动的量化工程,当时的计划是只需要给我提供pth文件我就能给你量化后的pth

然而在实际研究和coding过程中发现了各种问题,比如
- pth在没有model类定义的情况下是无法单独load的,即使是torch.save的完整模型,这个和TensorFlow的pb文件还不一样,之前TensorFlow用的多,所以不太了解这部分,夸下了只需要pth文件的海口;
- BN的自动融合很难cover所有的模型,因为不从底层计算图上进行conv层和bn层的融合都需要去自动识别两个模块,然后将两层参数进行融合计算,原始conv层变成一个有bias的conv层,bn层变成identity(不能完全去掉),因为编程方式的不同,所以这种自动识别十分困难,我目前实现的只能覆盖pytorchcv这个库里面的模型(欢迎尝试)
https://github.com/Ironteen/Batch-Normalization-fusiongithub.com
我尝试添加适应不同方式,但是发现很难做到,Captain Jack大佬对这个有一些比较好的理解
Captain Jack:MergeBN && Quantization PyTorch 官方解决方案zhuanlan.zhihu.com
- 很难自动去做qat,即量化感知训练,我自己写了一个Conv+BN融合的层,并加入了模仿量化的操作,暂时命名为Conv_Bn_Quant,但是给我一个官方预训练好的pth和模型类定义文件,我需要对每个模块做个name的映射才能将原始参数load进我写好的Conv_Bn_Quant中,这一步基本上就要非常了解这个模型的名字细节然后手动写了(说好的智能呢,怎么还停留在人工的阶段);
总的来说,模型的8bit量化在学术研究上剩余空间已经不多了,因为一些模型在per-layer无法达到很好结果时,per-channel往往可以解决这个问题,当硬件不支持per-channel操作时,用qat训练一下量化模型就行,所以目前再去研究如何提升量化后的精度就很难了,但在实际工程部署上面发现实现问题比较多,很难做一套完全自动化的流程,实现绝大多数模型的快速部署。
我根据查阅的资料和自己阅读过的论文,觉得以下方向还可以继续进行研究(肯定不全面而且理解上存在一定误区,希望大佬多多指点):
- 8bit的from scracth训练,这样就可以实现训练加速,前段时间研读了商汤的一篇相关论文,很有意思;
- full-quantized method,去掉中间大量的quantize和de-quantize操作,bias也进行量化,这样不可避免会丧失一定的灵活性(研究一下add这块怎么对scale进行对齐就能感受到),但整个过程中没有float32参与了,硬件运行是更高效的,尤其对于FPGA这种对float不是很友好的硬件;
- 将乘除法用移位来代替,在保证精度的前提下进一步提升硬件运行效率;这个论文目前比较多,之前在ICCV2019的poster现场看到不少;
- 无需提供数据或只需极少量数据就能对每一层的activation进行校准,这一步对精度影响还是蛮大的,但是对于一些比较隐私的数据(如医学),提供数据还是比较难的,所以如果能够从模型本身获取得到activation相关的信息然后进行校准是很有意义的,前段时间看过CVPR一篇论文就是解决这个问题,立意很好;
ZeroQ: A Novel Zero Shot Quantization Frameworkarxiv.org
- 模型量化向其他任务上的迁移,如目标检测,语义分割,人体位姿检测,NLP任务,如何在不进行量化训练的前提下保持较高精度(可以实现快速部署);














 2333
2333











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









