







梯度下降法是一种用于求解无约束最优化问题的迭代算法,广泛应用于机器学习和人工智能领域。它的基本思想是沿着函数梯度的反方向更新变量,以逐步接近函数的最小值点。下面我们将详细推导梯度下降法的公式。
1. 问题定义
假设我们有一个可微的凸函数 f : R n → R f:\mathbb{R}^n\to\mathbb{R} f:Rn→R,我们需要找一点个 x ∗ ∈ R x^*\in\mathbb{R} x∗∈R,使得 f ( x ∗ ) f(x^*) f(x∗)是 f f f的最小值。
2. 梯度的定义
函数
f
f
f 在点
x
x
x 的梯度是一个向量,记为
∇
f
(
x
)
\nabla f(x)
∇f(x),其第
i
i
i个分量是
f
f
f 关于
x
i
x_i
xi的偏导数:
∇
f
(
x
)
=
(
∂
f
∂
x
1
,
∂
f
∂
x
2
,
…
,
∂
f
∂
x
n
)
T
\nabla f(x) = \left( \frac{\partial f}{\partial x_1}, \frac{\partial f}{\partial x_2}, \ldots, \frac{\partial f}{\partial x_n} \right)^T
∇f(x)=(∂x1∂f,∂x2∂f,…,∂xn∂f)T
3. 梯度下降法的基本思想
梯度下降法的基本思想是:在每一步迭代中,从当前点
x
x
x 沿着梯度的反方向移动一步,以期望减少函数值。即:
x
k
+
1
=
x
k
−
α
k
∇
f
(
x
k
)
x_{k+1} = x_k - \alpha_k \nabla f(x_k)
xk+1=xk−αk∇f(xk)
其中,
α
k
>
0
\alpha_k > 0
αk>0 是第
k
k
k 步的步长(也称为学习率),它控制了在梯度方向上移动的距离。
4. 步长的选择
步长 α k \alpha_k αk 的选择对算法的收敛速度和效果有重要影响。常见的选择方法包括:
- 固定步长:在整个迭代过程中使用一个固定的步长 α \alpha α。
- 线搜索:在每一步迭代中,通过线搜索确定最优的步长 α k \alpha_k αk,使得 f ( x k − α k ∇ f ( x k ) ) f(x_k - \alpha_k \nabla f(x_k)) f(xk−αk∇f(xk)) 最小。
- 自适应步长:根据某种规则(如Armijo规则)动态调整步长。
5. 算法步骤
- 初始化:选择一个初始点 x 0 x_0 x0 和一个初始步长 α 0 \alpha_0 α0。
- 迭代:对于
k
=
0
,
1
,
2
,
…
k = 0, 1, 2, \ldots
k=0,1,2,…:
- 计算梯度 ∇ f ( x k ) \nabla f(x_k) ∇f(xk)。
- 选择步长 α k \alpha_k αk。
- 更新点 x k + 1 = x k − α k ∇ f ( x k ) x_{k+1} = x_k - \alpha_k \nabla f(x_k) xk+1=xk−αk∇f(xk)。
- 终止条件:当满足某个终止条件时(如梯度的模长小于某个阈值,或者达到最大迭代次数),停止迭代。
6.示例
- 类似于最小二乘法公式推导这篇文章,以拟合直线 f = w x + b f=wx+b f=wx+b来举例,不同的是本文采用梯度下降法来解决这个问题。
- 在线性回归中,使用样本数据对参数
w
,
b
w,b
w,b进行拟合时,需要定义一个损失函数用来衡量预测值
f
(
x
i
)
f(x_i)
f(xi)与真实值
y
i
y_i
yi的误差,而解决问题的方法就是使用梯度下降法来逐步缩小这个误差,损失函数如下:
L = 1 2 m ∑ i = 0 m − 1 ( f ( x i ) − y i ) 2 \mathcal{L} = \frac{1}{2m} \sum\limits_{i = 0}^{m-1} (f(x_i^{}) - y_i)^2 L=2m1i=0∑m−1(f(xi)−yi)2 - 计算梯度,对于损失函数求偏导
∂ L ∂ w = 1 m ∑ i = 0 m − 1 ( f ( x i ) − y i ) x i ∂ L ∂ b = 1 m ∑ i = 0 m − 1 ( f ( x i ) − y i ) \begin{align} \frac{\partial \mathcal{L}}{\partial w} &= \frac{1}{m} \sum\limits_{i = 0}^{m-1} (f(x_i) - y_i)x_i \newline \frac{\partial \mathcal{L}}{\partial b} &= \frac{1}{m} \sum\limits_{i = 0}^{m-1} (f(x_i) - y_i) \\ \end{align} ∂w∂L∂b∂L=m1i=0∑m−1(f(xi)−yi)xi=m1i=0∑m−1(f(xi)−yi) - 参数
w
,
b
w,b
w,b在梯度的反方向上更新,采用固定学习率
α
\alpha
α:
w = w − α ∂ L ∂ w b = b − α ∂ L ∂ b \begin{align*} \newline w &= w - \alpha \frac{\partial \mathcal{L}}{\partial w} \newline b &= b - \alpha \frac{\partial \mathcal{L}}{\partial b} \newline \end{align*} wb=w−α∂w∂L=b−α∂b∂L - 过程代码如下:
import numpy as np
import matplotlib.pyplot as plt
def compute_prediction(x, w, b):
m = len(x)
f_wb = np.zeros(m)
for i in range(m):
f_wb[i] = w * x[i] + b
return f_wb
def compute_loss(x, y, w, b):
m = x.shape[0]
cost_sum = 0
f_wb = compute_prediction(x, w, b)
for i in range(m):
cost = (f_wb[i] - y[i]) ** 2
cost_sum += cost
total = (cost_sum / (2 * m))
return total
def compute_gradient(x, y, w, b):
m = x.shape[0]
dl_dw = 0
dl_db = 0
for i in range(m):
f_wb = w * x[i] + b
dl_dw_i = (f_wb - y[i])*x[i]
dl_db_i = f_wb - y[i]
dl_dw += dl_dw_i
dl_db += dl_db_i
dl_dw = dl_dw / m
dl_db = dl_db / m
return dl_dw, dl_db
def gradient_descent(x, y, w, b, alpha, num_iter):
w_new = w
b_new = b
for i in range(num_iter):
dl_dw, dl_db = compute_gradient(x, y, w_new, b_new)
w_new = w_new - alpha * dl_dw
b_new = b_new - alpha * dl_db
loss = compue_loss(x, y, w_new, b_new)
if i % 100 == 0:
print(f"iteration {i}, loss = {loss}, w_new = {w_new}, b_new = {b_new}")
return w_new, b_new
if __name__ == '__main__':
plt.rcParams['font.family'] = ['SimHei']
x = np.array([1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0])
y = np.array([1.5, 2.6, 3.7, 4.1, 5.1, 6.2, 7.9])
w = 0
b = 0
iterations = 3000
alpha = 0.02
w_new, b_new = gradient_descent(x, y, w, b, alpha, iterations)
print(f"w_new = {w_new}, b_new = {b_new}")
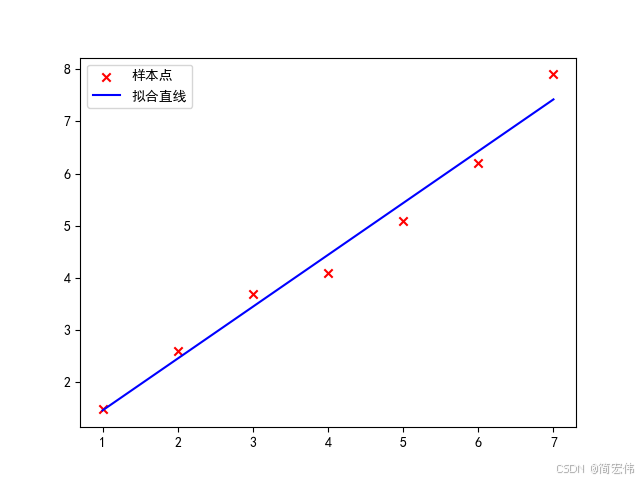
plt.scatter(x, y, marker='x', c='r', label='样本点')
_y = w_new * x + b_new
plt.plot(x, _y, c='b', label='拟合直线')
plt.legend()
plt.show()
- 执行过程
iteration 0, loss = 4.083270897959183, w_new = 0.4348571428571429, b_new = 0.08885714285714286
iteration 100, loss = 0.045664329045427686, w_new = 1.0284820572555182, b_new = 0.2950160966273745
iteration 200, loss = 0.04399190943292208, w_new = 1.0170929790163885, b_new = 0.35141414029427887
iteration 300, loss = 0.04321788689124178, w_new = 1.0093449229474887, b_new = 0.389782056936218
iteration 400, loss = 0.0428596568809325, w_new = 1.0040738754064713, b_new = 0.41588397345192607
iteration 500, loss = 0.04269386230341597, w_new = 1.0004879511523623, b_new = 0.4336412588461576
iteration 600, loss = 0.04261712992158636, w_new = 0.9980484260568011, b_new = 0.44572164322645447
iteration 700, loss = 0.042581616948186136, w_new = 0.9963888029665887, b_new = 0.4539399988779966
iteration 800, loss = 0.042565180976179944, w_new = 0.9952597517399471, b_new = 0.4595309939563808
iteration 900, loss = 0.042557574145494485, w_new = 0.9944916516334235, b_new = 0.46333458037827735
iteration 1000, loss = 0.04255405358260628, w_new = 0.9939691086701637, b_new = 0.4659221823106715
iteration 1100, loss = 0.042552424209801445, w_new = 0.9936136196575556, b_new = 0.4676825429329474
iteration 1200, loss = 0.042551670110010785, w_new = 0.9933717784177523, b_new = 0.4688801264876919
iteration 1300, loss = 0.04255132110056829, w_new = 0.9932072524178053, b_new = 0.4696948495350295
iteration 1400, loss = 0.04255115957341695, w_new = 0.9930953244245458, b_new = 0.4702491103556911
iteration 1500, loss = 0.04255108481606821, w_new = 0.9930191791607023, b_new = 0.4706261772108932
iteration 1600, loss = 0.0425510502171717, w_new = 0.9929673770954908, b_new = 0.47088269798232785
iteration 1700, loss = 0.042551034204249084, w_new = 0.9929321358496834, b_new = 0.471057210552896
iteration 1800, loss = 0.042551026793212446, w_new = 0.9929081610254951, b_new = 0.47117593246814665
iteration 1900, loss = 0.04255102336326615, w_new = 0.9928918508133643, b_new = 0.47125669967657685
iteration 2000, loss = 0.04255102177583213, w_new = 0.992880754881329, b_new = 0.4713116460775329
iteration 2100, loss = 0.04255102104114237, w_new = 0.9928732062543251, b_new = 0.4713490264332082
iteration 2200, loss = 0.04255102070111606, w_new = 0.9928680708795352, b_new = 0.4713744565062632
iteration 2300, loss = 0.04255102054374656, w_new = 0.9928645772542416, b_new = 0.47139175673264894
iteration 2400, loss = 0.0425510204709134, w_new = 0.992862200520665, b_new = 0.4714035261771313
iteration 2500, loss = 0.04255102043720508, w_new = 0.9928605836150096, b_new = 0.47141153299856486
iteration 2600, loss = 0.04255102042160434, w_new = 0.992859483624702, b_new = 0.47141698008568605
iteration 2700, loss = 0.042551020414384015, w_new = 0.9928587352949075, b_new = 0.47142068577068896
iteration 2800, loss = 0.04255102041104237, w_new = 0.9928582262018023, b_new = 0.47142320676971744
iteration 2900, loss = 0.0425510204094958, w_new = 0.9928578798628064, b_new = 0.47142492181999723
w_new = 0.9928576461815167, b_new = 0.4714260789959605 - 运行效果如下:
总结
梯度下降法是一种简单而有效的最优化算法,通过沿着梯度的反方向更新变量,逐步接近函数的最小值点。它的成功依赖于合适的步长选择和函数的性质。在实际应用中,梯度下降法被广泛用于训练机器学习模型,如线性回归、逻辑回归和神经网络等。

















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









