










检索增强生成(RAG)简介
Brief Introduction to Retrieval-Augmented Generation (RAG)
By Jackson@ML
世间先有大语言模型(Large Language Models, 即LLMs)或曰大规模语言模型,然后有检索增强生成(RAG)。
1. 什么是检索增强生成?
检索增强生成(Retrieval-Augmented Generation,即RAG) 是指对大型语言模型输出进行优化,使其能够在生成响应之前引用训练数据来源之外的权威知识库。
大型语言模型(LLM)用海量数据进行训练,使用数十亿个参数为回答问题、翻译语言和完成句子等任务生成原始输出。
在 LLM 本就强大的功能基础上,RAG 将其扩展为能访问特定领域或组织的内部知识库,所有这些都无需重新训练模型。这是一种经济高效地改进LLM 输出的方法,让它在各种情境下都能保持相关性、准确性和实用性。 - Amazon Web Service
2. 检索增强生成(RAG)体系架构
检索增强生成(RAG)是基于知识库的LLM,和针对企业的特定数据源(诸如企业文档,数据库和内部应用程序等)相结合的软件体系架构。
RAG能确保和提高LLM响应的准确性和相关性。
由于RAG使用向量数据库存储使用语义搜索检索的最新信息,连同其他有用信息一道,添加到Prompts的上下文窗口,助力大模型生成潜在的、最佳的和最新的响应。
当前市面流行的AI聊天机器人,以及Web应用程序,均利用Llama2和GPT等大语言模型,来生成满足用户提示词的响应。
凭借自身对自然语言的细微差别和生成能力的深入理解,大模型都成了RAG体系架构的基础。
以英伟达为例,下面是信息分块、向量化以及存储的架构。
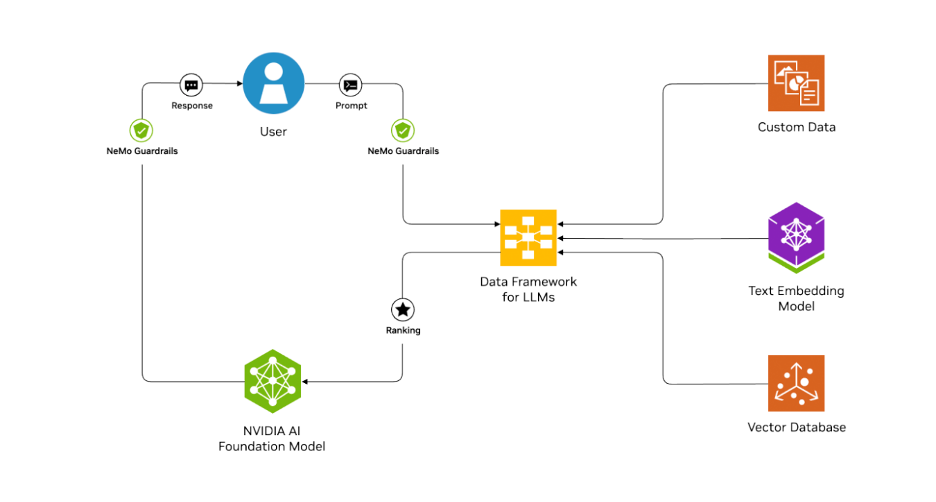
图1 来自于nvidia.cn
3. 向量数据库
向量数据库是 RAG 系统的核心,可以以数据块形式有效地存储特定业务的数据信息,每个数据块由嵌入模型产生的相应多维向量表示。存储在向量数据库中的数据块可以是文本、图形、图表、表格、视频或其他数据模式。
1) 向量数据库优势
这些数据库可以处理向量空间操作的复杂性和特异性,如余弦相似性,因此具备几个关键优势:
- 高效相似性搜索:能够快速搜索最接近查询向量的 top-K 向量,对语义搜索和推荐系统而言至关重要。
- 处理高维数据:随着数据中相关特征数量的增加,使用传统 SQL 数据库难以提供最快的性能。
- 可扩展性:向量数据库可以在多个 GPU 加速服务器上运行,以提供理想的数据摄取或相似性搜索性能。
- 实时处理:RAG 应用,如 AI 聊天机器人,依靠向量数据库提供最新的业务信息发送给 LLM,因此 LLM 能够更好地满足用户的查询。
- 增强的搜索相关性:通过理解语义关系,改善内容发现和用户体验,提供更相关的结果。
这些功能令向量数据库成为 RAG 不可或缺的一部分,支持涉及复杂数据的高效运维。
2) 向量检索机制
向量检索机制是RAG系统运行的坚实基础,支持快速高效检索特定的企业信息。
从使用嵌入模型对数据初始分块并转换为向量,到运用ANN搜索等算法从向量数据库中检索top-K匹配向量,要经历一系列复杂过程。这些算法通常需要GPU来加速。这种检索机制,对企业环境的大量数据集至关重要。
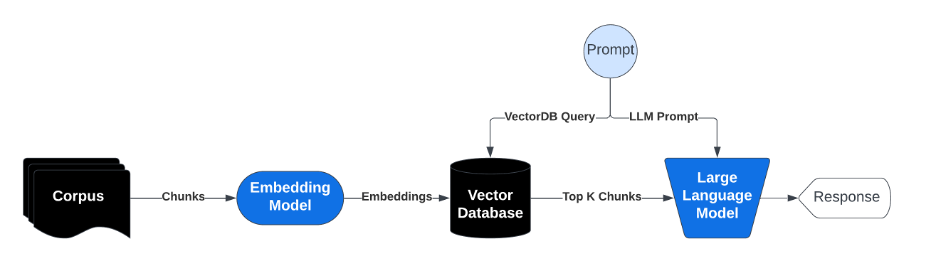
图2 来自于together.ai
4. 检索增强生成(RAG)的重要性
大语言模型(LLMs)是关键的人工智能技术,作为AI聊天机器人(例如:ChatGPT, Deepseek等)和自然语言处理(Natural Language Processing, 简称NLP)的应用程序提供支持。
其目的是,通过交叉引用权威知识库,能够创建在各种环境或上下文中顺利回答用户问题的机器人。但不幸的是,LLM技术的本质引入了不可预测性;另外,LLM引入的数据是静态的,并引入了其所掌握知识的截止日期。
这就带来了问题和挑战:
- 当没有提供答案时,会提供虚假信息;
- 但需要特定的当前响应时,可能提供通用(而非特定)或过时的信息;
- 由非权威来源创建响应;
- 基本术语混淆,不同的训练数据来源,使用相同的术语来探讨不同的事件,当然会产生不准确的响应。
产生这些问题的大模型,就类似于非常热心帮助别人但技术能力欠缺的工程师一样,会绝对自信回答一系列问题;但不凑巧的是,这种态度会对用户产生负面影响;久而久之,人类会放弃使用聊天机器人。
5. 解决LLM幻觉
企业级人工智能解决方案,往往面临重大挑战,那就是使用LLM会导致幻觉现象。幻觉,通俗地说就是由大模型响应后,看起来逻辑连贯且非常合理,但与事实不符或不准确,这不是人类所期望的结果。这样的问题会危及企业决策过程的准确性,也会降低人工智能驱动的洞察力的可靠性。
如果借助RAG,则可以在LLM提示的上下文窗口中,获得额外的指令和相关数据块,进行更完善的处理,以提供更明智的响应,从而减少错误信息,但RAG不能彻底消除幻觉。
仍然需要运用传统技术,以减少幻觉现象。企业部署应用程序,可能仍然需要使用安全护栏来减轻有害的用户交互。
6. 检索增强生成的主要步骤
RAG引入了信息检索组件,该组件利用用户prompt输入,首先会从新数据源提取信息;用户查询后相关信息均提供给LLM。
由已有的LLM将新知识及其训练数据创建更好的响应,以满足用户需要。以下是RAG的主要步骤:
1)创建外部数据
位于LLM原始训练数据集之外的数据,成为新数据;新数据可来自于多个数据源,诸如:关系型数据库,文档数据库,API等。
新数据可能以各种格式存在,例如:文本文件,数据库记录或长文本等。
另一种数据,由称为嵌入语言模型的AI技术将数据转换为数字表示形式,并存储在向量数据库中。其过程会创建生成式AI大模型能够理解的知识库。
2)检索相关信息
接下来,要执行相关性搜索。用户查询将转换为向量表示形式,并与向量数据库匹配。
例如,考虑一个可以回答组织特定专业问题的智能聊天机器人。如果员工搜索:“我本人如何休年假?”,系统将检索年假政策文件以及员工个人过去的休假记录。这些个性化的特定文件将被退回,因为它们与员工输入的内容高度相关。相关性是使用数学向量计算和表示法计算和建立的。
3)增强LLM提示
到了这一步,RAG模型通过在上下文中添加检索到的相关数据来增强用户prompts(即输入信息);这里,提示词工程会与LLM进行有效沟通。这部分增强提示允许大语言模型为用户查询生成准确的答案。
4)更新外部数据
外部数据虽然有用,但也面临可能过时。要维护当前信息以供检索,需异步更新文档,并更新文档的嵌入表示形式。可通过自动化实时流程或定期批处理,来执行此操作。
企业级应用程序如何运用RAG,以及RAG是否可以托管至云服务,从而减轻企业网络部署和应用开发的成本等,笔者将陆续推出相关技术文章。
*鸣谢:
- Amazon Web Service (AWS)
- Nvidia
- together.ai
敬请关注、收藏和点赞👍。
您的认可,我的动力!😃

















 2537
2537

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









