






从刚开始最简单的神经元到如今各式各样的神经网络模型,神经网络发展至今已经过去80年了!没有特指的神经网络都叫人工神经网络,所以别迷糊,人工神经网络ANN不是一种特殊的类型,而是神经网络的统称。此外,神经网络按照网络信息流向可分为前馈神经网络(例如多层感知机)和反馈神经网络(例如循环神经网络),这也是两种类型神经网络的统称,而不是什么特殊的神经网络。
让我们从最开始的M-P模型开始来回溯神经网络的发展历程,回溯是为了体会思想的发展历程以期望从中找到规律。
一、1943年——M-P模型(两位大佬McCulloch和Pitts名字的首字母)
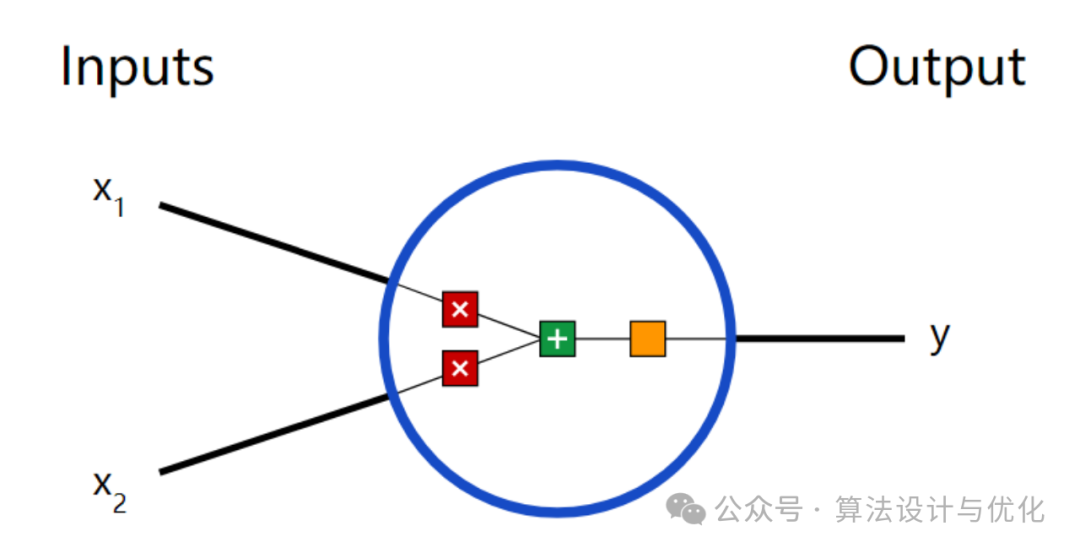
加权求和再加偏置,传入激活函数得到最终结果y。但M-P模型权重的值都是预先设置的,无法学习。1949年心理学家Hebb提出了Hebb学习规则,继此之后还有Delta学习规则,但这些规则都是针对单个神经元。
二、1957年——感知机(Perceptron)
感知机是一个二分类线性判别模型,更多内容可参考李航老师的《统计学习方法》,下图来源于本书。

三、1960年——自适应线性单元(Adaptive Linear Neuron, ADALINE)
与感知机不同的是,ADALINE采用了线性激活函数而非符号函数,这就可以做回归问题了,而不仅限于分类问题。
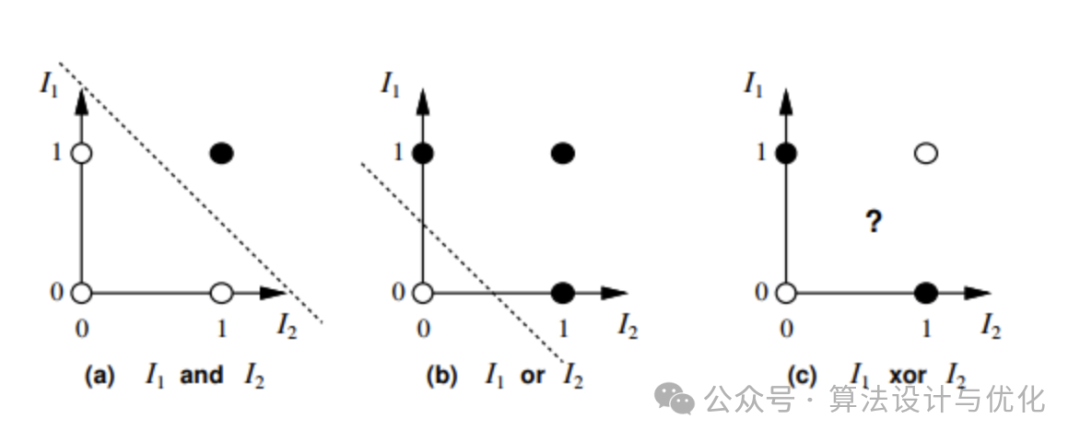
在1969年Minsky和 Papert证明了感知机功能有限,甚至无法解决简单的“异或”逻辑问题(即线性不可分,对应下图的c,a和b显然线性可分)。Minsky认为研究更深层的网络是没有价值的,由于他的学术地位和影响力,自此神经网络发展停滞,进入了“AI winter”。
四、1981年——自组织映射(Self-Organizing Maps,SOM)
在神经网络低潮时期也是出现了一些不错的研究,最著名的就是SOM了,先说一下竞争学习,这个竞争学习很有意思,成者为王败者为寇,谁赢了谁就是老大,可以调整权重,输的会被强侧抑制(唯我独兴,不允许其他神经元兴奋),不允许调整。SOM网络也叫Kohonen神经网络,如下图所示,分为输入层和竞争层。SOM网络没有那么霸道,离得近的调整小,离得远的调整大,而不是都不调整。
在此基础上,后面也是衍生出了结合竞争网络和监督学习的学习矢量量化(Learning Vector Quantization,LVQ)网络。更多内容请参考《人工神经网络理论设计及应用第二版》,需要pdf评论留言。
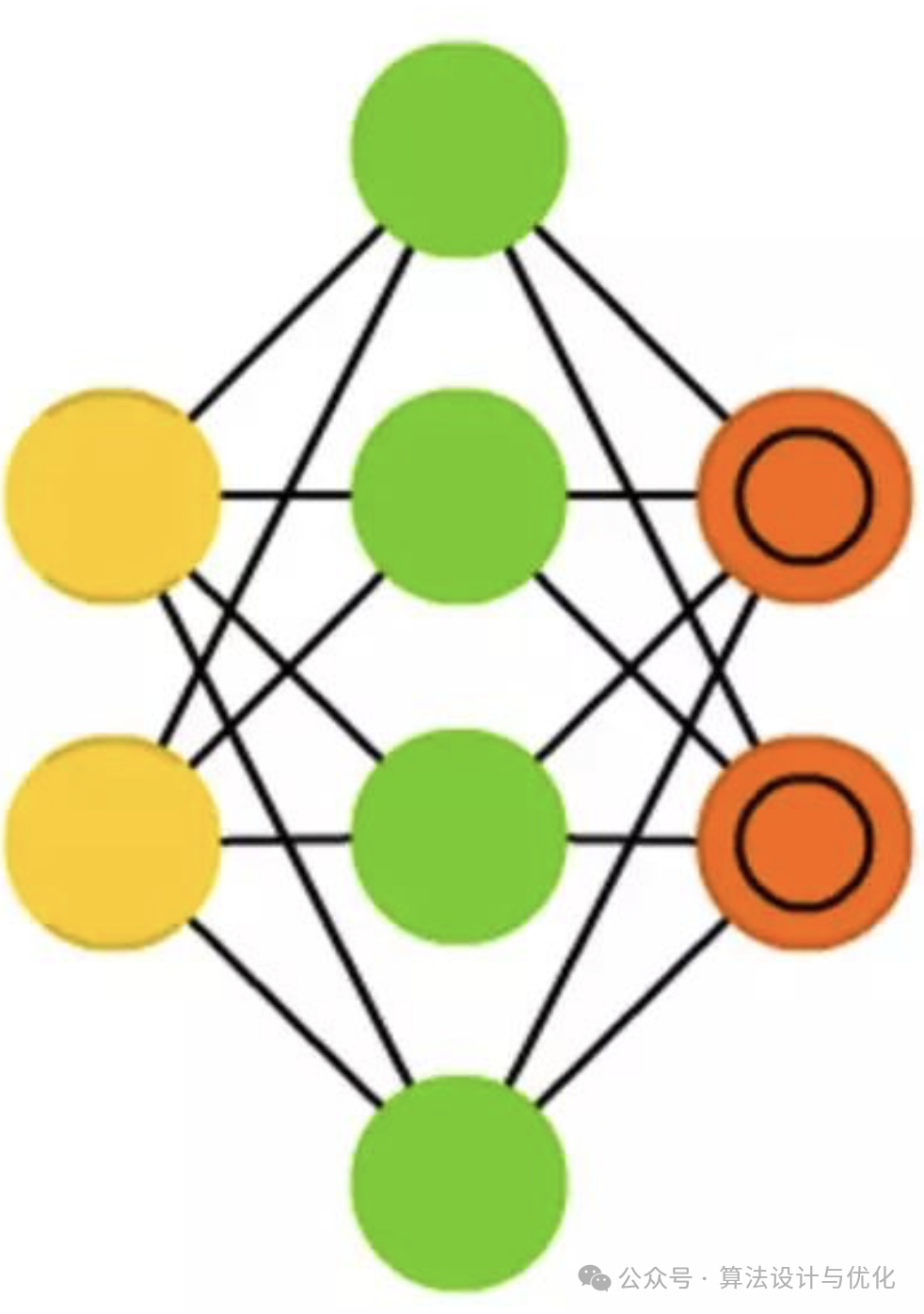
五、1982年——Hopfield神经网络(HNN)
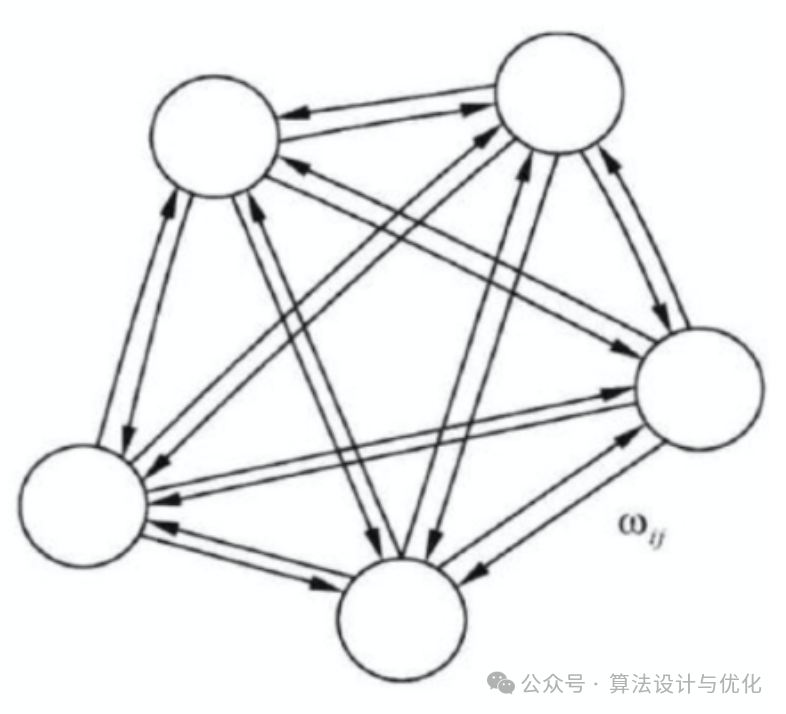
1982年,Hopfield提出了离散的Hopfield神经网络DHNN,使得神经网络再次进入了蓬勃发展时期。HNN中所有神经元都相互连接,形成一个对称的权重矩阵,自己和自己相连权重为0,如下图所示。通过最小化能量函数使得网络趋于稳定状态。
在此之后,Hopfield又提出了连续的Hopfield神经网络CHNN,与DHNN不同的是CHNN采用了连续函数如S型函数而非符号函数。更多内容请参考https://hagan.okstate.edu/NNDesign.pdf。
六、1983年——波尔兹曼机(Boltzmann Machine,BM)
BM是一种随机生成型神经网络,我们沿用HNN的网络图,BM和HNN的区别就在于划分了隐单元和可见单元,如下图所示。可见单元用于输入数据或输出数据,隐单元用于挖掘数据分布,学习潜在关系。
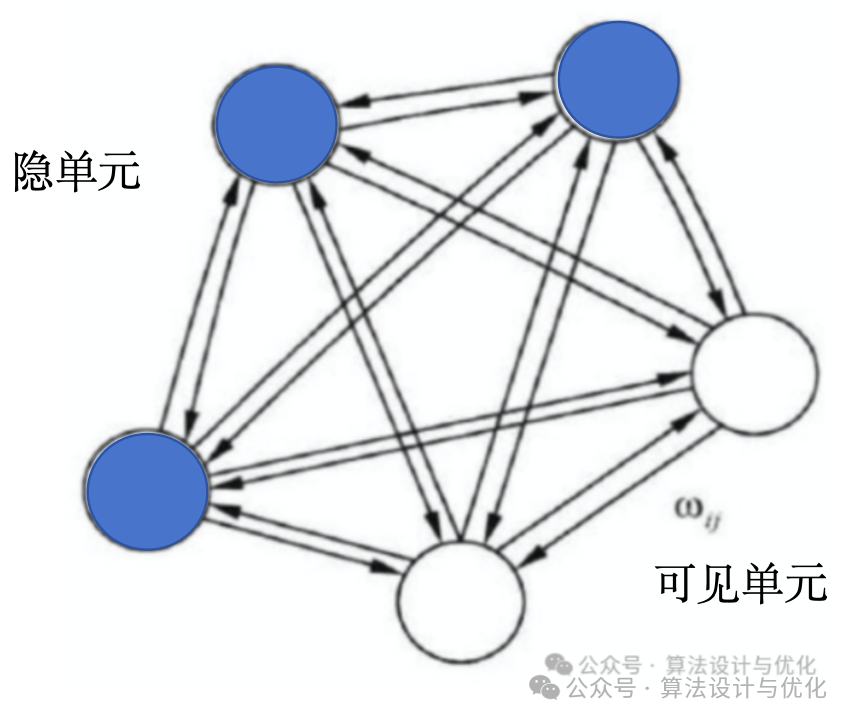
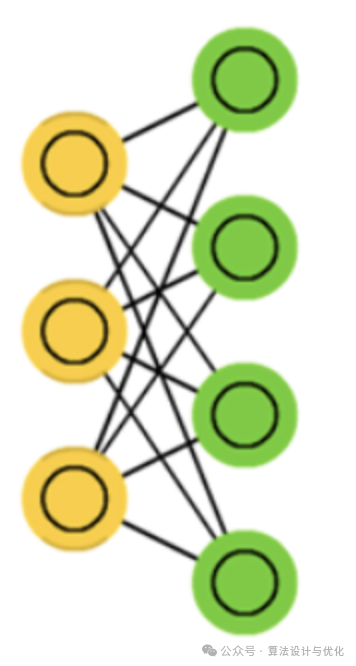
可以看到BM所有神经元都相互连接,这样计算过于复杂,于是就出现了限制玻尔兹曼机(Restricted Boltzmann Machine,BM),也就是隐层和可见层全连接,但是同一层不再相互连接,如下图所示。此时的BRM依然是通过采样以得到服从RBM所表示分布的随机样本。
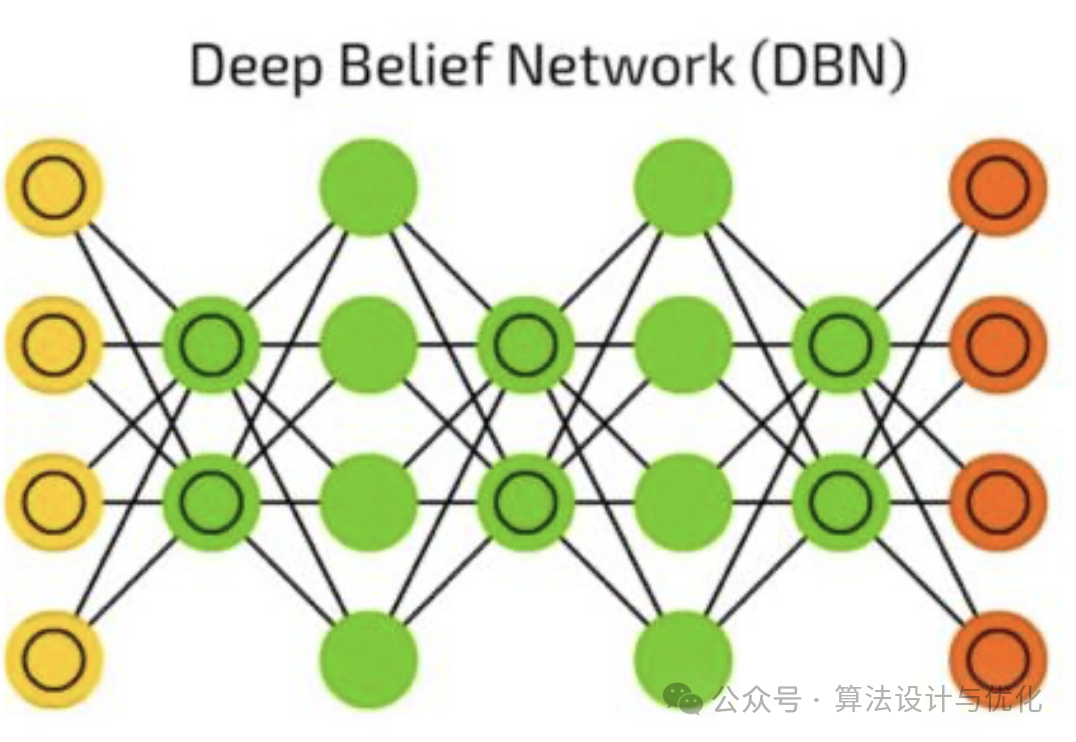
2002年Hinton提出了一个RBM学习的快速算法(对比散度)加快了RBM的学习效率。2006年Hinton又提出了基于RBM的深度信念网络(Deep Belief Network, DBN)。一个DBN模型由若干个RBM堆叠而成,一个RBM一个RBM的训练,逐层预训练和微调。
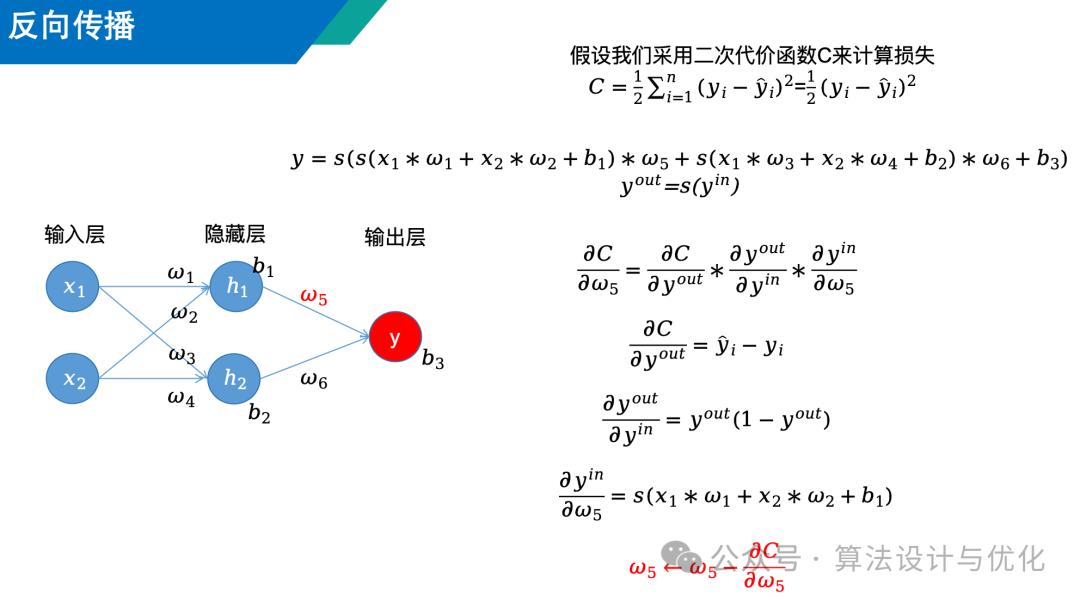
七、1986年——反向传播(Backpropagation,BP)
早在1974年就有人提出了BP算法,但是到1986年才受到了广泛关注。BP神经网络就是我们常说的含有一层隐藏层的神经网络,也叫多层感知机。BP算法的核心就在于通过下图中红色的公式来更新神经网络中的权重参数和偏置参数,下图中共有9个参数,每个参数的更新都是类似计算的。计算过程其实很简单,链式法则就像剥洋葱一样,一层一层的剥开,从外往里一个一个计算就完事了。
Cybenko 等人证明了具有隐含层(最少一层)的神经网络在激活函数为 Sigmoid 函数的情况下具有逼近任何连续函数的本事,这就是著名的万能逼近定理(Universal Approximation Theorem)。也就是一个仅有单隐含层的神经网络,在神经元个数足够多的情况下,通过非线性激活函数,足以拟合任意连续函数。
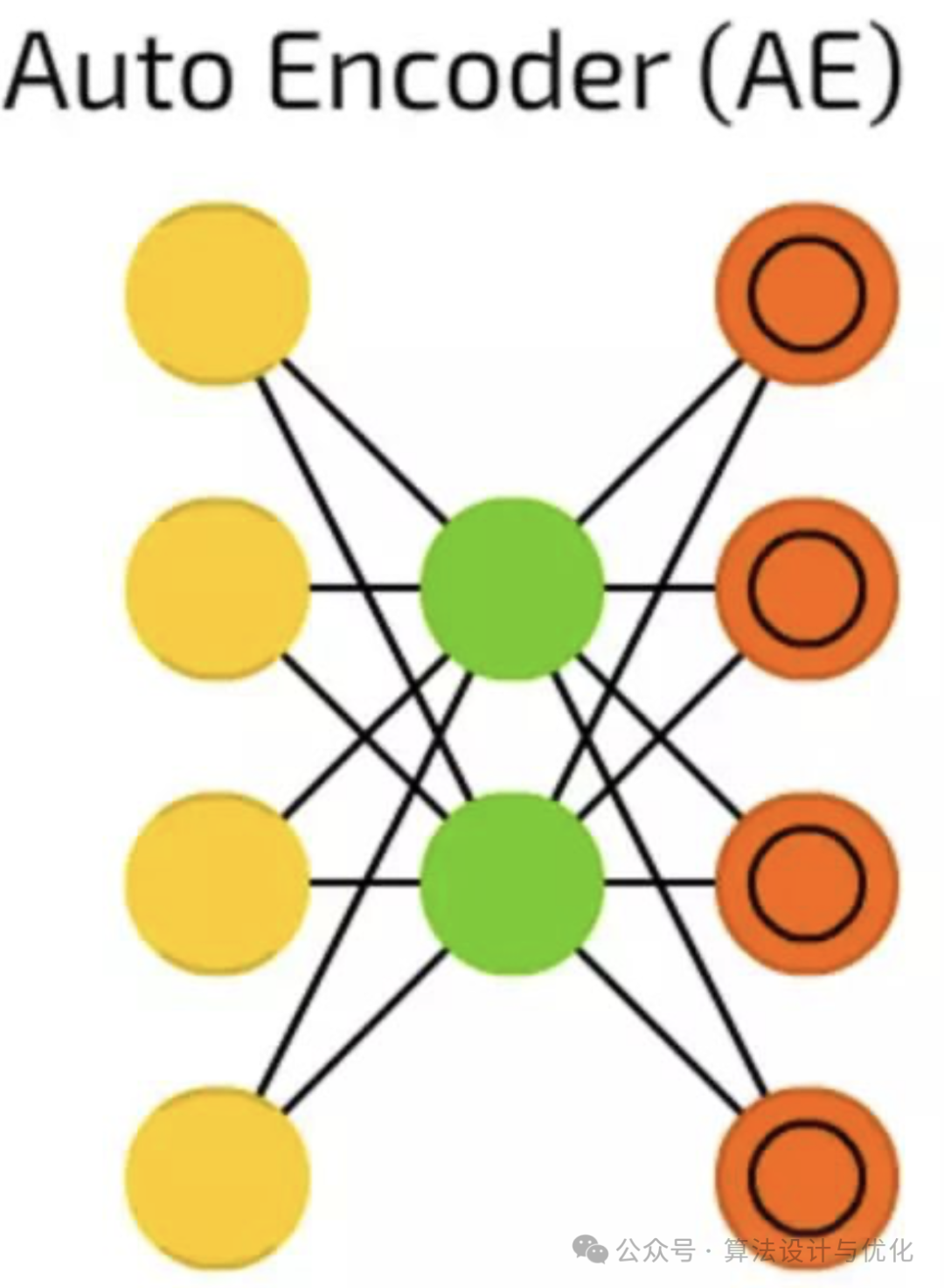
八、1986年——自编码器(AutoEncoder, AE)
自编码器包含编码器(encoder)和解码器(decoder)两部分,如下图所示,先编码再解码,使得输出和输入尽可能相等,目的是对输入信息进行表征学习(从原始数据中学习到有用的、更高层次的表示或特征)。
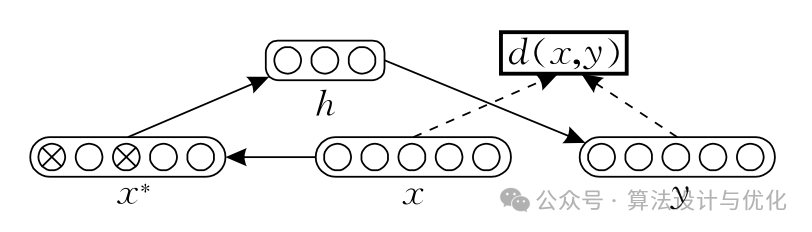
当输入数据包含噪声时AE的性能会受到影响,因此2008年有了去噪AE(Denoising AE,DAE),如下图所示。先给输入数据x添加随机噪声得到x*,再对x*进行编码解码,希望解码后的数据和x尽可能相等。
AE的隐藏层神经元数量小于输入神经元,如果大于的话就是稀疏自编码器(Sparse AE,SAE),希望每次获得的编码尽量稀疏。
AE生成能力较弱,因此出现了生成模型变分自编码器(Variational AE,VAE),通过将输入映射到一个概率分布上而不是一个确定的点。具体来说,编码器输出的是潜在变量 z 的均值和方差,随后从这个参数化的高斯分布中采样得到 z,解码器再基于这个采样的 z 生成输出。
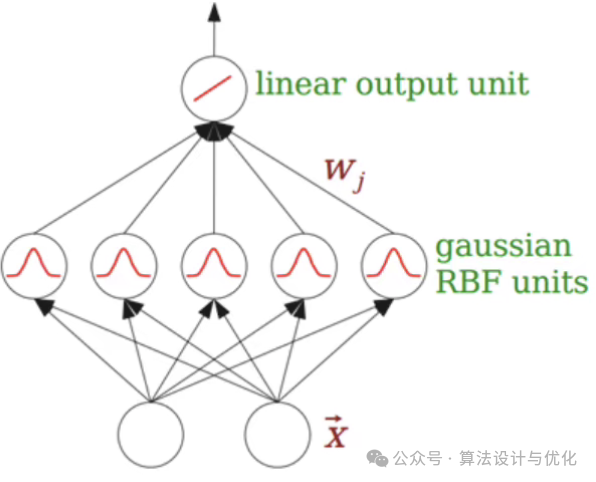
九、1988年——径向基神经网络(Radial Basis Function Nerual Networks, RBFNNs)
RBFNN跟多层感知机类似,都是输入层,一层隐藏层和输出层。不同的是RBFNN隐藏层使用的是径向基函数(输入x,返回x与函数中心点之间的距离)作为激活函数,输入层到隐藏层没有权重,隐藏层到输出层才有权重,如下图所示。这就使得RBFNN不需要去更新隐藏层参数,计算效率直接提升一个档次,因此也叫局部逼近网络。
基于RBFNN,衍生出了广义回归神经网络(Generalized Regression Neural Network,GRNN)和概率神经网络(Probabilistic Neural Network,PNN)作为RBFNN的变体进一步加快了其运算速度,个人感觉很有潜力~
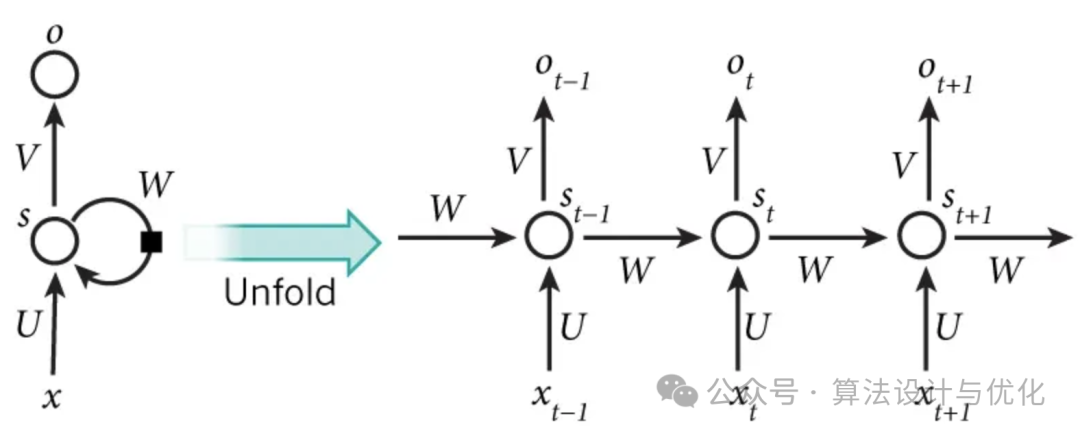
十、1990年——循环神经网络(Recurrent Neural Networks, RNN)
这一年Jeffrey Elman提出了第一个全连接的RNN,从单层前馈神经网络出发构建递归连接,因此也被称为简单循环网络(Simple Recurrent Network, SRN),如下图所示。简单解读一下,就是RNN的隐藏层的值s不仅仅取决于当前这次的输入x,还取决于上一次隐藏层的值s。权重矩阵W就是隐藏层上一次的值作为这一次的输入的权重。
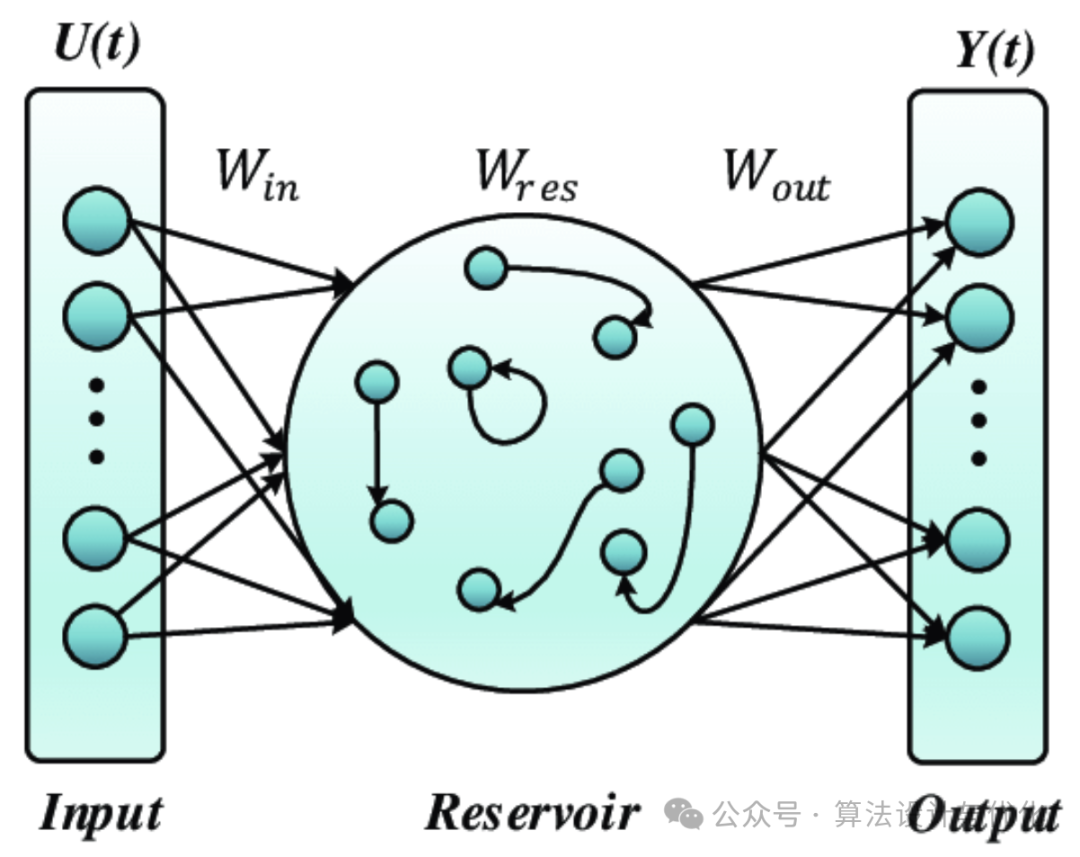
回声状态网络(Echo State Network, ESN)是一种特殊的RNN,如下图所示,隐藏层也叫储备池,包含大量随机连接的神经元,这些连接权重在初始化时随机设定且在整个学习过程中保持固定不变。其目的是创造一个高度非线性转换的动态系统,能够捕捉输入数据的时间依赖性和复杂动态特征。
递归神经网络(recursive neural network)被视为RNN的推广,按照树/图结构处理信息,具体请参考https://zybuluo.com/hanbingtao/note/626300。
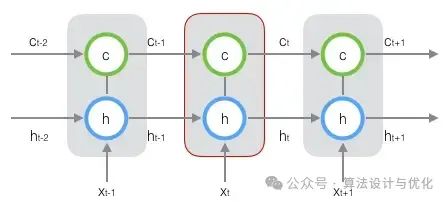
RNN的一个主要问题是在对长序列进行学习时会出现梯度消失(gradient vanishing)和梯度爆炸(gradient explosion),无法捕捉长时间跨度的非线性关系。于是,在1997年出现了著名的长短期记忆网络(Long Short-Term Memory networks, LSTM)如下图所示。跟上图对比,就是增加了一个状态让他来保存长期状态,不就能记住了吗?相应的,有三个门(输入门、输出门和遗忘门)来控制这个状态。同年还产生了双向循环神经网络(Bidirectional RNN, BRNN)。
2014年,K. Cho提出了门控循环单元(Gated Recurrent Unit, GRU)。GRU简化了LSTM,仅包含两个门:更新门和重置门。这使得GRU更容易训练和更容易收敛。
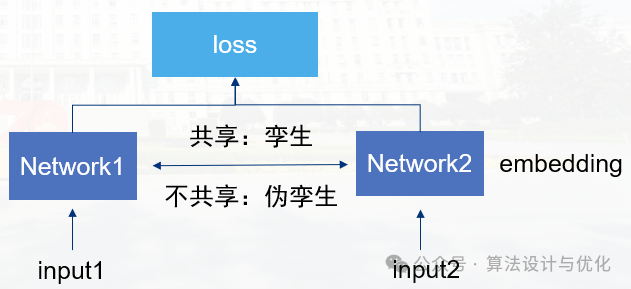
十一、1993年——孪生网络(Siamese Networks, SN)
孪生网络就是"连体的神经网络",神经网络的"连体"是通过共享权值来实现的,如下图所示。简单解读一下就是通过两个共享权重的相同子网络分别处理输入数据,产生可对比的特征表示,进而计算它们的相似度,使得相似样本的特征向量彼此靠近,而不相似样本的特征向量彼此疏远。
十二、1997年——脉冲神经网络(Spiking Neural Networks, SNN)
最早的感知机是第一代神经网络,BP神经网络是第二代神经网络,SNN的作者将SNN称为第三代神经网络。SNN如下图所示,他的输入是离散的脉冲序列(0和1),但目前还没有太好的训练方法,之后可能会有所突破。
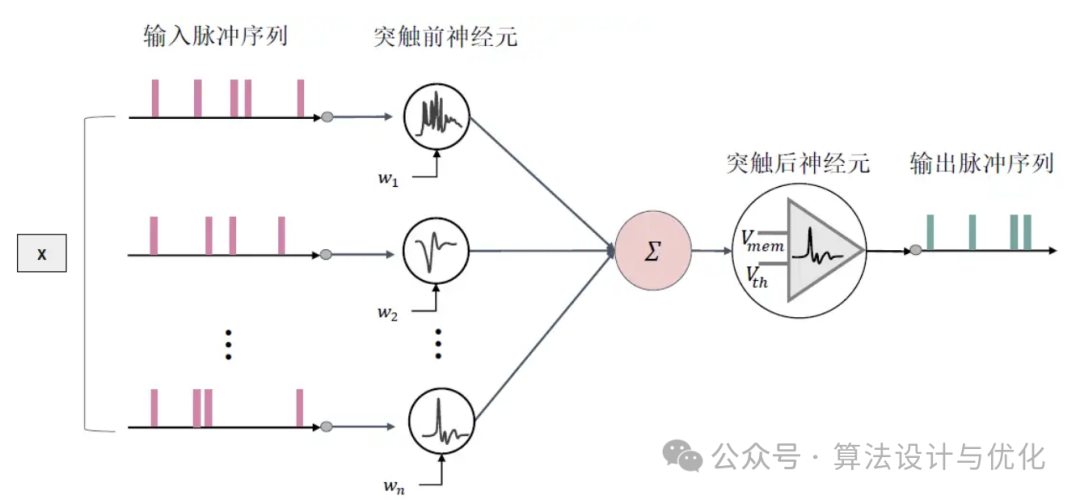
在此基础上,还有混合型脉冲神经网络液体状态机(Liquid State Machine,LSM),即前馈和反馈混合。
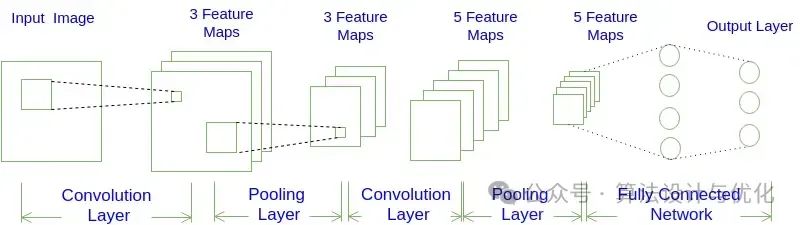
十三、1998年——卷积神经网络(Convolutional Neural Networks, CNN)
早在1980年,福岛邦彦提出neocognitron模型,被认为是启发了CNN的开创性研究。1989年Yann LeCuu构建了LeNet最初版本,在1998年提出的卷积神经网络LeNet-5在手写数字识别中取得成功,CNN进而引起了广泛关注。CNN网络如下图所示,主要不同的是卷积层和池化层,无非就是特征提取和降维,多卷几次,就能把特征里包含的信息大大小小都给学到了,池化层就是取其精华弃其糟粕。相关的还有去卷积、反卷积。
自2012年的AlexNet 开始(首次采用GPU加速,使用了 ReLU 激活函数,Dropout,LRN 局部响应归一化),得到GPU计算支持的复杂CNN多次成为ImageNet竞赛的优胜算法,2013年的ZFNet ,2014年的VGGNet、GoogLeNet 和2015年的ResNet ,UNet。
十四、2004年——极限学习机(Extreme Learning Machine,ELM)
ELM是一个一层隐藏层的简单前馈神经网络,结构很简单。隐层权重和偏置通常是随机初始化的,无需在训练过程中进行调整,学习过程仅计算输出权重,如此学习效率大幅提升。
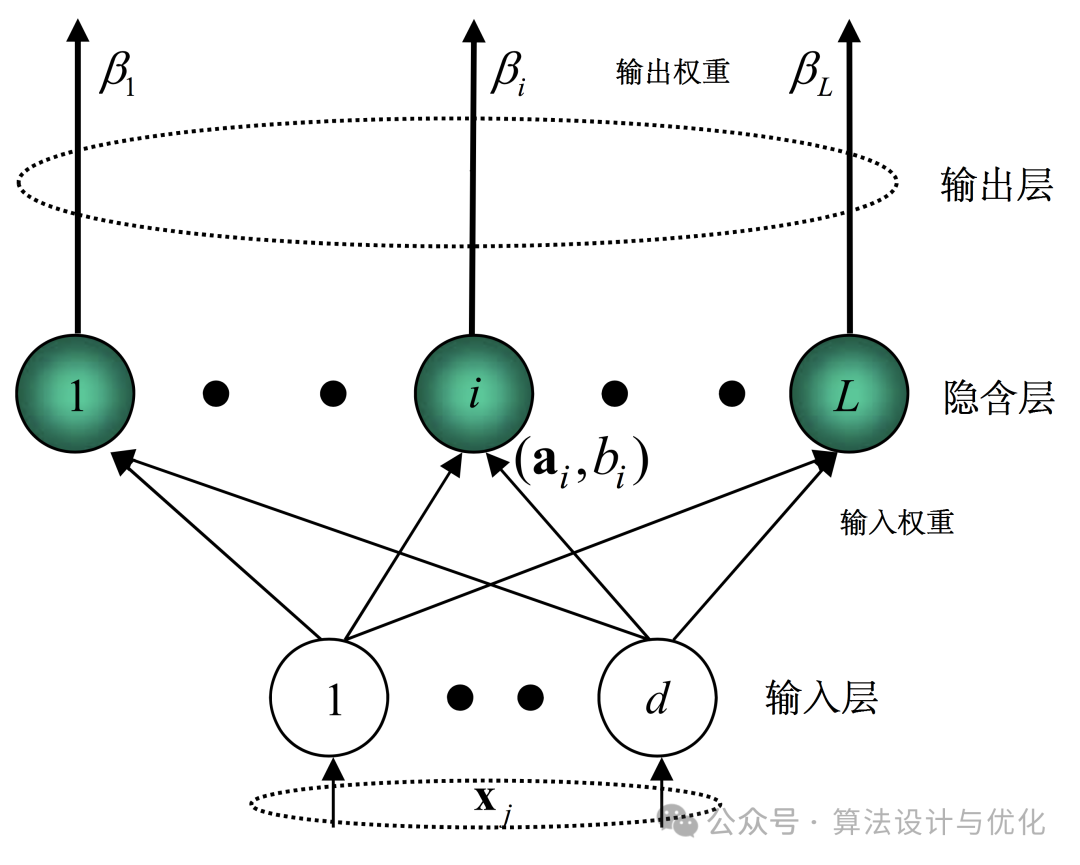
乍一看感觉很熟悉,没错,就是径向基神经网络RBFNN,ELM随机设置隐藏层权重改为RBFNN的不设置权重,激活函数再换成径向基函数,都是只计算输出权重,是不是很像了!
十五、2005年——图神经网络(Graph Neural Network, GNN)
GNN专门设计用于处理图结构数据(常见的就是交通预测,将一片区域划分为好多小区域,每个小区域就对应图中的一个点)。通过节点间的邻居信息传递和聚合操作,迭代地更新每个节点的特征表示,从而捕捉局部乃至全局的图结构信息。

值得关注的另一个是超图神经网络,图的一条边只能连接两个点,而超图允许连接超过两个点,相比之下,超图神经网络能处理更复杂的情况。
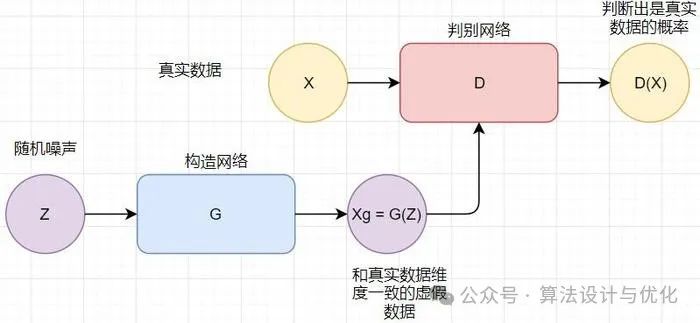
十六、2014年——生成对抗网络(Generative Adversarial Network,GAN)
GAN主要包括两个部分:生成模型(Generator)和判别模型(Discriminator)。生成模型试图学习真实数据的分布,以便它可以创建新的、但看起来真实的样本。判别模型则尝试区分生成的数据样本与真实数据样本。这两个模型在训练过程中相互对抗:生成器努力生成更逼真的样本以欺骗判别器,而判别器则不断学习以更准确地区分真实样本与伪造样本。这种对抗过程形成了一个动态的平衡,随着训练的进行,生成器逐渐改进其生成数据的质量,直至生成的数据在统计特性上与真实数据非常接近,以至于判别器无法可靠地区分两者。
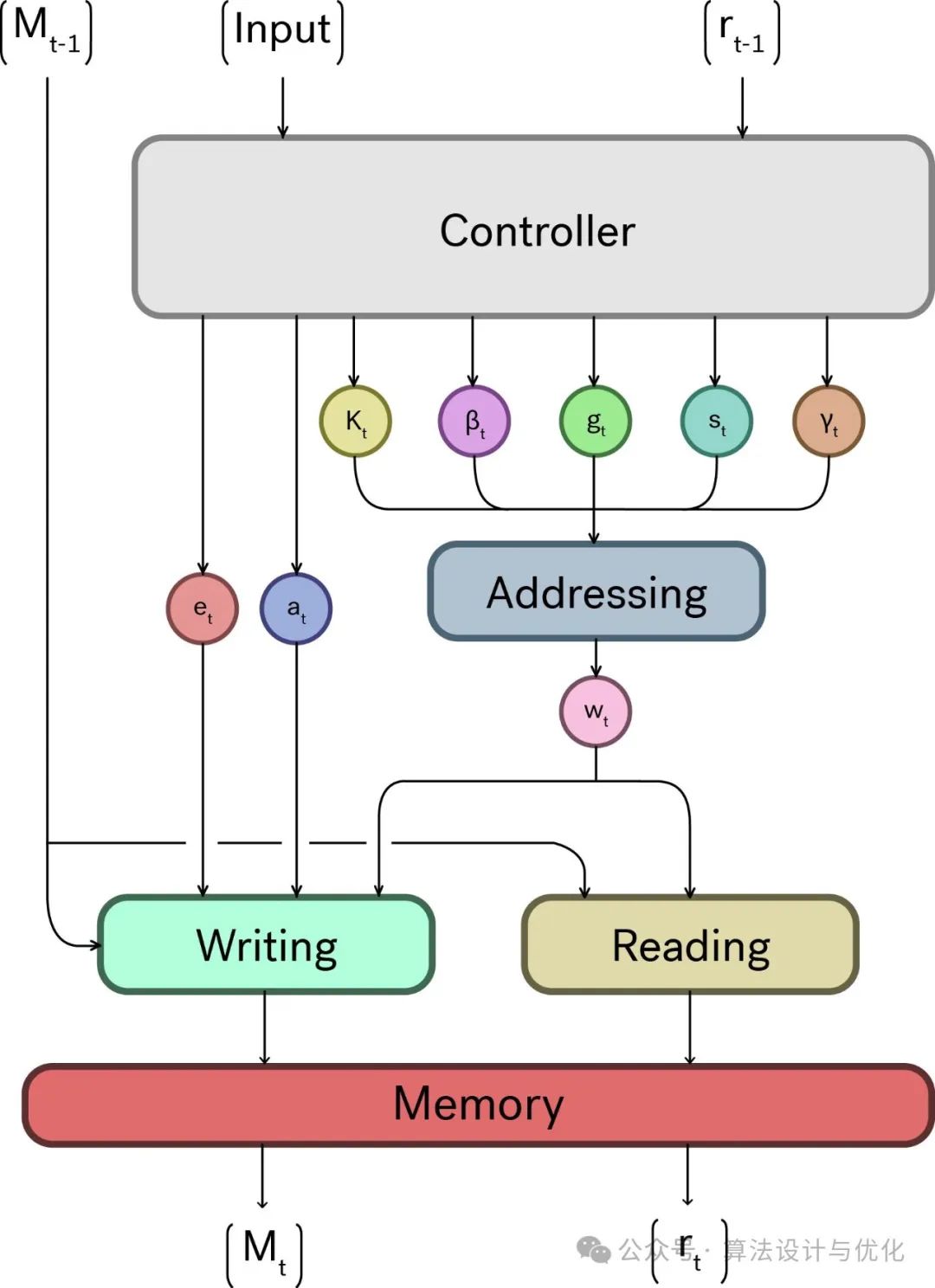
十七、2014年——神经图灵机(Neural Turing Machine, NTM)
图灵机(Turing Machine)是英国数学家图灵于1936年提出的一种理论计算模型。NTM的灵感就来源于图灵机,但它利用神经网络来控制读写头对外部存储矩阵的操作,从而实现对数据更灵活和可适应的处理。
十八、2015年——残差网络(Residual Network,ResNet)
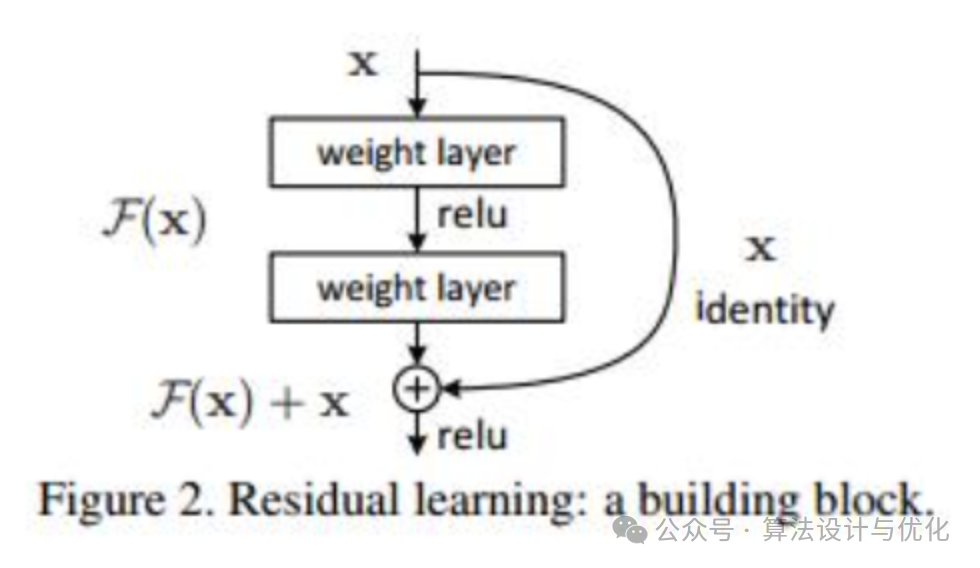
ResNet通过残差学习解决了深度网络的退化问题,称得上是深度学习的一个历史大突破。其核心思想是通过引入“残差块”(Residual Block)来学习残差映射,即输出相对于输入的变化量,如下图所示。简单来说,就是利用恒等快捷连接绕过非线性变换,从而简化优化过程,有效解决深层网络的梯度消失问题,使网络能够轻易达到数百乃至上千层的深度。
十九、2015年——深度Q网络(Deep Q Network,DQN)
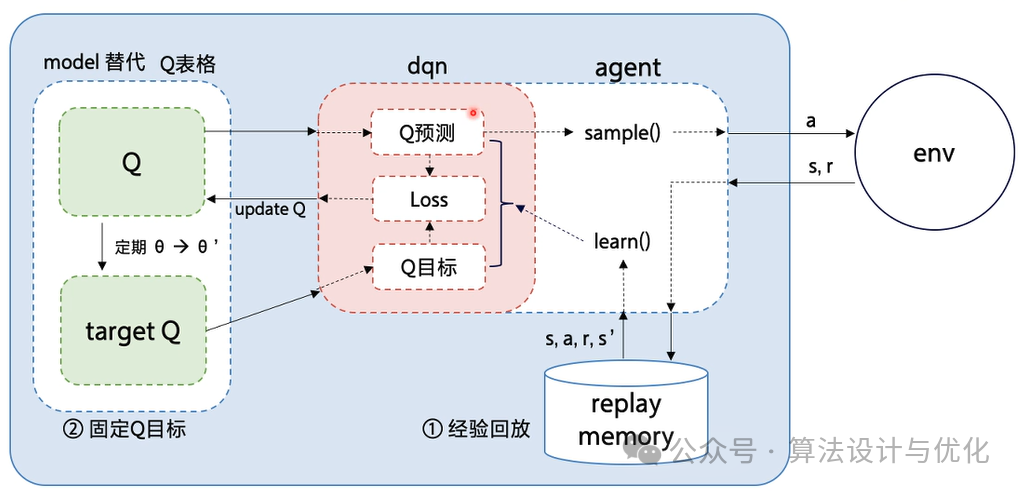
深度Q网络是深度学习和强化学习的强强联合。说到强化学习,就是训练机器学会干一件事,干得好的了给他奖励,干的不好了就惩罚他,于是机器就学会了最大化他的长期收益,并尽可能少的受到惩罚。在这过程中涉及到机器所处的状态,机器采取的动作以及对应的奖励/惩罚值,还有这个Q值,Q值就可以理解为长期收益,我们想尽可能最大化这个长期收益。传统的Q-learning算法通过一张表格来记录每个状态下不同动作对应的奖励/惩罚值,但是对于复杂的问题例如下围棋,企图用一张表格记录并查询简直费劲的要死,于是我们用神经网络输入状态和动作,让神经网络输出对应的Q值,极大地提升了在复杂环境下的决策质量和学习效率。围棋人机大战中的机器用的就是DQN。
二十、2016年——YOLO模型(You Only Look Once)
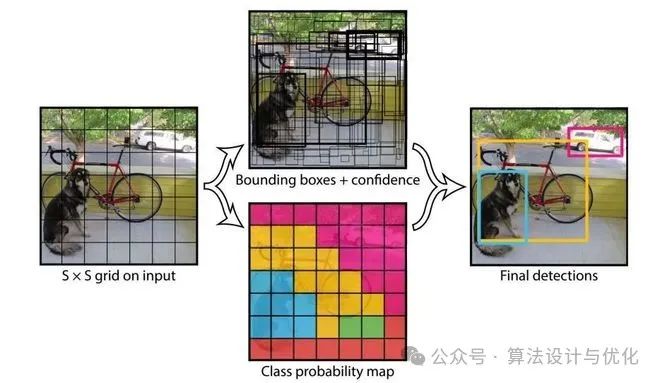
YOLO模型的核心思想是在一个过程中直接从整张图像中预测边界框和物体类别,通过将图像划分为网格并为每个网格预测潜在目标的边界框和概率,从而实现快速、实时的目标检测。提到目标检测就会说YOLO,当然还有其他目标检测模型Faster R-CNN等等。
继 2023 年 1 月 YOLOv8 发布一年多以后,2024年也就是今年的2月份发布了YOLOv9,据说被评价为新的SOTA实时目标检测器。
二十一、2017年——胶囊网络(Capsule Networks, CapsNets)
CapsNets的设计初衷是为了解决CNN存在的局部敏感性和层次结构解析能力不足的问题。具体来讲就是图片的微小变化会对CNN结果产生较大影响。与传统神经网络中的神经元相比,胶囊具有更高维度的输出和更复杂的内部结构(位置、方向、大小等),这使得胶囊能够对输入数据进行更为精细和丰富的描述。
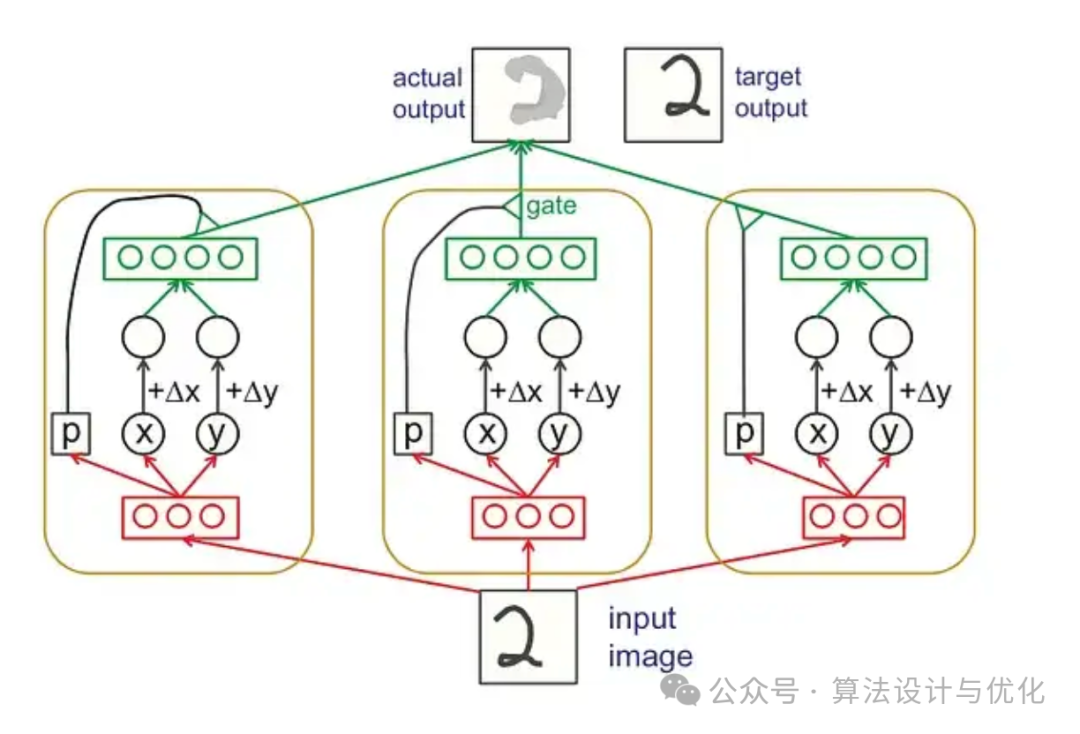
二十二、2017年——PointNet
PointNet是一种专门为处理点云数据(一种几何数据结构)设计的深度学习模型。它的创新之处在于能够直接用2D卷积神经网络直接处理3D点云。由于 PointNet 不能很好地提取局部精细的特征,为了解决直接提取3D点云特征的过程中,如何能够更好的提取不同尺度下局部的精细特征,PointNet++应运而出。
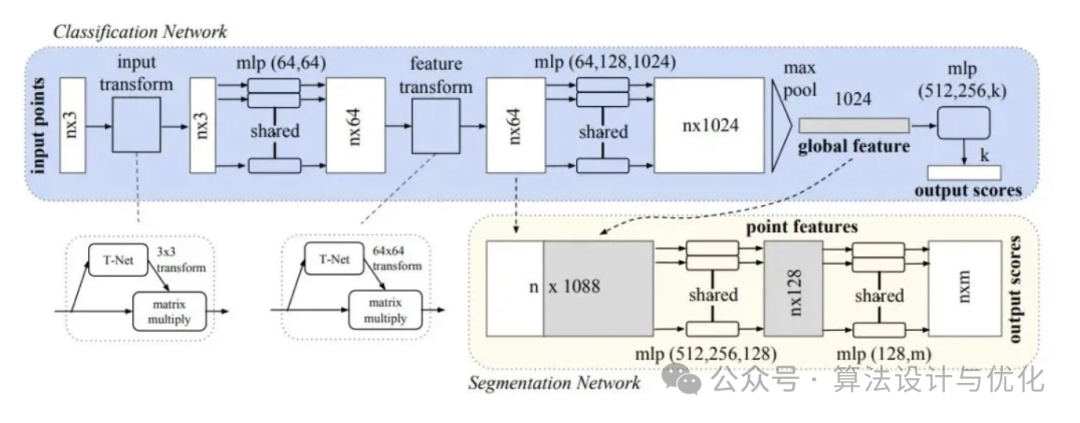
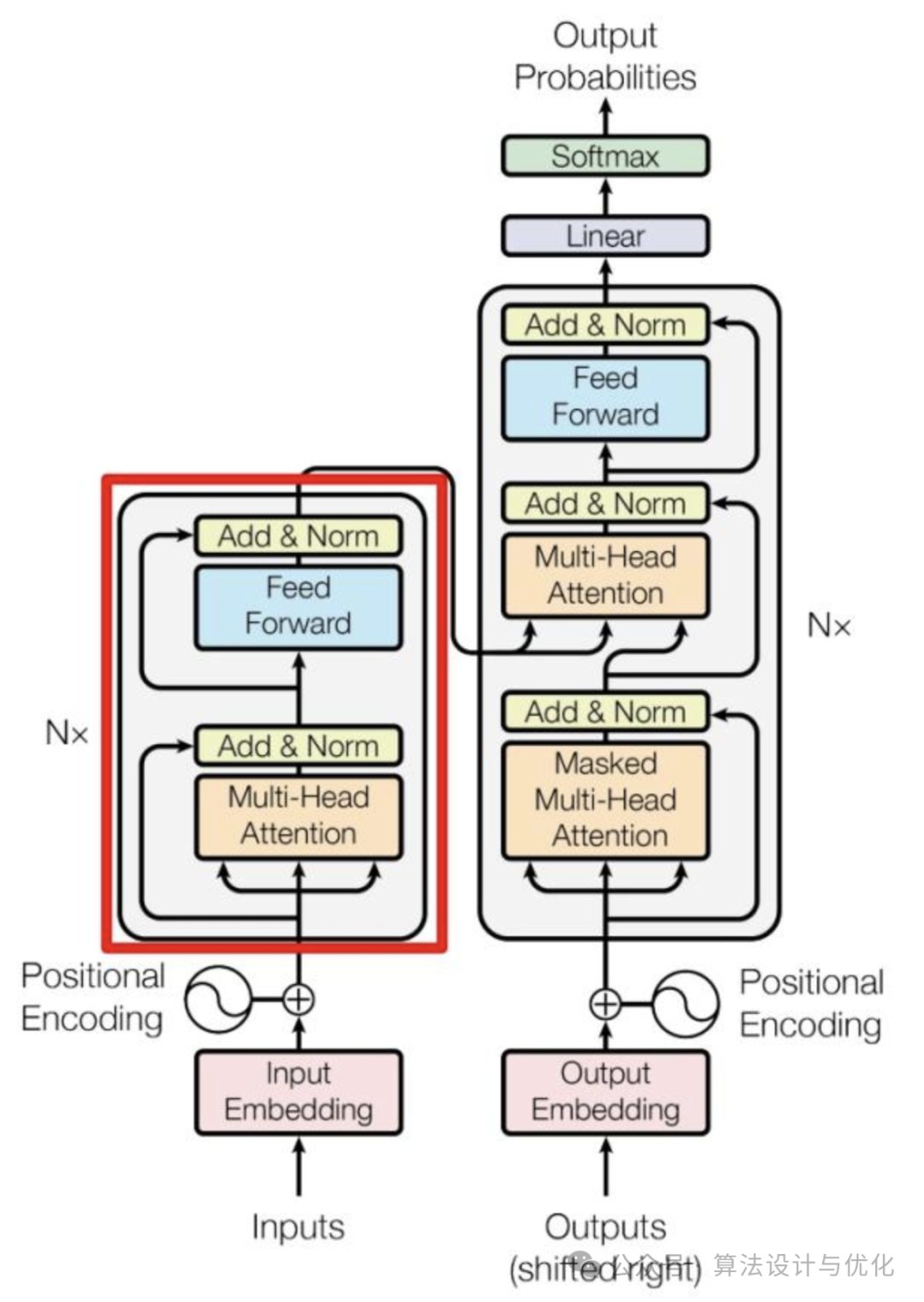
二十三、2017年——Transformer
Transformer 由多个 Encoder 和 Decoder 组成,Encoder 和 Decoder 如下图所示,其核心在于根据输入的不同部分之间的相关性,动态地分配注意力权重。这意味着模型可以同时考虑输入序列的所有部分,从而更好地理解和生成上下文相关的输出。之后还有很多基于Transformer的模型例如Bert,GPT,XLNet等等。
二十四、2020年——扩散模型(Diffusion model)
扩散模型最早在2015年Deep unsupervised learning using nonequilibrium thermodynamics中提出,但我们常说的扩散模型通常是指2020年提出的Denoising Diffusion Probabilistic Models。主要有两个过程:正向扩散和逆向扩散。
正向扩散:逐步添加噪声,一共加T次,最终变成一个真正的噪声。
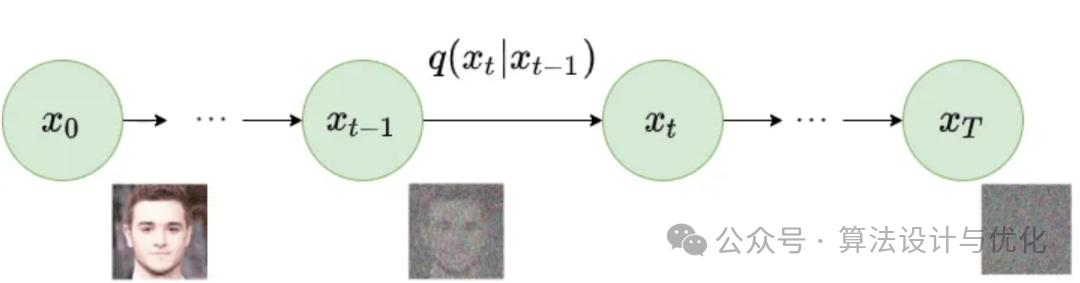
逆向扩散:逐步恢复图片,使用的是共享参数的 U-Net 结构。

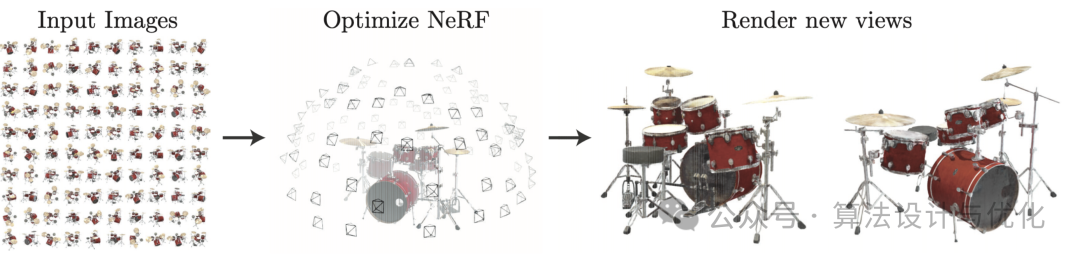
二十五、2020年——神经网络辐射场(Neural Radiance Fields, NeRF)
SLAM (Simultaneous Localization and Mapping)是一种在未知环境中同时构建地图(Mapping)并定位自身(Localization)的技术。它通过传感器(如摄像头、激光雷达)的数据实时估计机器的位置,并构建环境的地图。NeRF的出现正在重塑SLAM系统,它不同于传统的三维重建方法把场景表示为点云,而是将场景建模成一个连续的5D辐射场隐式存储在神经网络中,只需输入稀疏的多角度带pose的图像训练得到一个神经辐射场模型,根据这个模型可以渲染出任意视角下的清晰的照片。通俗来讲就是构造一个隐式的渲染流程,其输入是某个视角下发射的光线的位置o,方向d以及对应的坐标(x,y,z),送入神经辐射场Fθ得到体密度和颜色,最后再通过体渲染得到最终的图像。可参考https://blog.csdn.net/minstyrain/article/details/123858806。
鸣谢:本文得到了知名算法工程师毛毛和靓毛的大力支持!
来源于公众号:算法设计与优化
















 2970
2970

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









