







目录
前言:
本篇文章将系统的介绍数据预测过程之中涉及的重要概念,完成阐述数据预测的基本框架和脉络。旨在为读者顺利学习和理解后续章节的各具体算法奠定理论基础。
一、什么是数据预测?
数据预测简而言之,就是基于已有的数据集,归纳出输入变量和输出变量的关系。基于这种关系,我们可以得到两个重要的用途:发现对输出变量产生重要影响的输入变量,另一方面我们可以得到当在数量关系具有普适性和未来情况不变的假设下,可以用于对新的数据的预测。我们将数值型输出的情况的预测称之为回归,对于分类型输出的变量的预测称之为分类。
数据预测将涉及下列问题:
1.预测建模(Modeling):
我们知道机器学习的编程范式而言:输入变量对应于“数据”,输出变量对应于“答案”,二者之间的取值规律对应于“规则”。而“规则”隐藏在数据集之中,需要基于一定的学习策略归纳出来,并且通过预测模型的形式表现出来,这个过程就是预测建模。
2.模型评价(Model Assessment):
我们将预测模型运用到新数据的预测之中,对于预测精度高、误差低的模型会更乐意被我们接受。所有我们如何对模型进行一个客观、全面的评价,是数据预测的重要问题。
3.模型选择(Model Selection):
面对我们筛选出性能良好的模型而言,我们还要进行比较,从中选出一个最好的佼佼者。
二、预测模型:
对于预测模型我们根据数据的输出形式分类为:回归预测模型和分类预测模型。
1.回归预测模型:
回归预测模型的核心目标是找到一个能够最好地拟合数据的数学方程式,这个方程可以表达为y = f(x),其中y是因变量,x是自变量,f代表两者之间的函数关系。根据自变量的数量,可以分为一元回归和多元回归;根据函数关系的类型,又可分为线性回归和非线性回归。
最简单常见的回归模型————线性回归:
y = β₀ + β₁x₁ + β₂x₂ + ... + βₙxₙ + ε
自变量(X):自变量是模型中用来预测或解释因变量的输入特征,可以是单个变量(一元线性回归),也可以是多个变量(多元线性回归)。在实际应用中,自变量通常代表影响因变量的各种因素,如房价预测中的房屋面积、位置、房龄等。因变量(Y):因变量是模型试图预测的目标变量,它受到自变量的影响并表现出某种变化趋势。在房价预测的例子中,因变量就是房屋的价格。回归系数(β):回归系数是自变量前面的参数,它们决定了每个自变量对因变量的影响程度。在多元线性回归中,每个自变量都有一个对应的回归系数,表示该自变量对因变量的贡献大小和方向。误差项(ε):误差项表示模型无法解释的部分,即除了自变量之外,还有哪些因素影响了因变量。在统计学中,误差项通常被假设为服从正态分布的随机变量,其均值为零,方差为常数
2.分类预测模型:
分类预测模型是一类用于将数据项映射到特定类别或组别的算法和统计方法的总称
比较抽象,这里先介绍一个简单常见的分类预测模型————Logistic回归模型:
Logistic回归模型是一种广义线性回归分析模型,特别适用于因变量为分类变量的情况,当需要根据一组自变量预测一个二分类结果(如疾病发生与否,这里我们一般用0和1表示)时,Logistic回归是常用的方法之一。
ln(P/1-P)=β0+β1X1+β2X2+⋯+βkXk+ϵ
参数分析:对于P而言为输出变量(记为y)取类别值为1的概率,对于其余参数而言于线性回归的概念一致。对于该公式我们似乎无法理解凭空出现的P,在这之间涉及了sigmoid函数,他将线性组合的结果映射到 (0, 1) 区间内。仅需了解即可。
三、预测模型的几何理解:
1.回归预测建模:
首先,基于p个输入变量进行回归预测建模的时候,将数据集之中的N个一般观测,视为p+1维空间的N个点,增加了一个输出变量的点。(比较好理解当输入变量只有1个的情况下,我们只需利用平面直角坐标系即可表示,对于输入变量有2个的时候我们需要使用三维的空间坐标系表示)。在教程课本给出的视图我们显然可以看见,在1个输入变量的情况下:回归方程与回归直线相对应。对于在2个输入的情况下:回归方程与回归平面相对应。
2.分类预测建模:
首先,基于p个输入变量进行分类预测建模时,将数据集之中的N个样本观测数据视为p维空间的n个点。其次,由于N个样本观测的输出变量取值不同,相应的样本观测点利用不同的颜色和形状来表示。对于二分类预测建模的目的,就是找到一条可以将不同的形状或颜色的样本观测点“有效分开”
四、预测模型的参数估计:
对于回归模型而言:我们需要基于数据集给出参数的合理估计值,从而使回归平面可以很好拟合样本观测点。分类预测建模也需要基于书籍及给出参数的合理估计,使得分类平面可以很好的把不同类型的观测点给分隔开。所以无论在回归预测模型还是在分类预测模型都需要我们,设置一个度量指标,测度上述目标尚未完成的程度,我们一般称之为损失函数(Loss Function),记为L。对于建模参数的估计我们一般采用一损失函数最小为目标,通常有jai监督学习算法。
1.有监督学习算法与损失函数:
参照机器学习的编程范式:我们可以知道“数据”即为预测建模的输入变量,“答案”为输出变量,“规则”为模型参数的估计值体现。这里我们发现:寻找“规则”的时候(就是求参数的过程),我们必须要在输出变量的监督下实现。
对于损失函数我们一般用L来表示记为L(e),其中e为误差,L与e成正比,用于度量预测模型对数据的拟合误差。
回归预测模型:对于回归模型之中我们一般用残差(残差的概念:输出变量的实际值减去预测值的差)来表示误差。而对于损失函数的设计:L(e)=e平方。被称之为平方损失函数,是最常见的损失函数:对于总损失而言:每一个观测值的损失函数相加。
总结特点:用残差表示误差,一般用误差的平表示
分类预测模型: 对于分类模型的误差定义,比较困难,所以我们在这里以K分类的预测模型中我们一般以概率的对数式表示损失函数,称之为交互熵。详细公式参照课本教程。
2.参数解空间和搜索策略:
我们可以知道的是损失函数是关于输出变量的实际值和模型参数的函数。比如在我们上面介绍的回归预测模型的损失函数L,我们可以发现是有关模型参数βi(i=0,1,2...p)的一个二次函数,它是存在最小值的。我们为了使损失函数取得最小的参数β,我们只需要1对参数求导,另导数为0并且解方程即可。例如在线性回归之中:
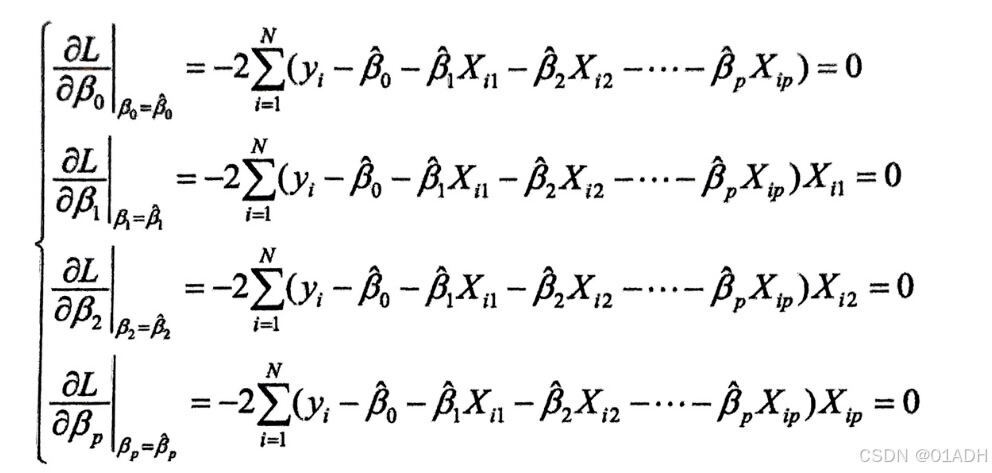
这种参数求解方法称之为最小二乘法。是一种常见的方法。
预测模型解空间的概念:所有模型参数的解构成的集合空间。而机器学习常在预测模型参数的解空间之中,采取一定的搜索策略来估计参数。
下面给出机器学习的预测建模过程
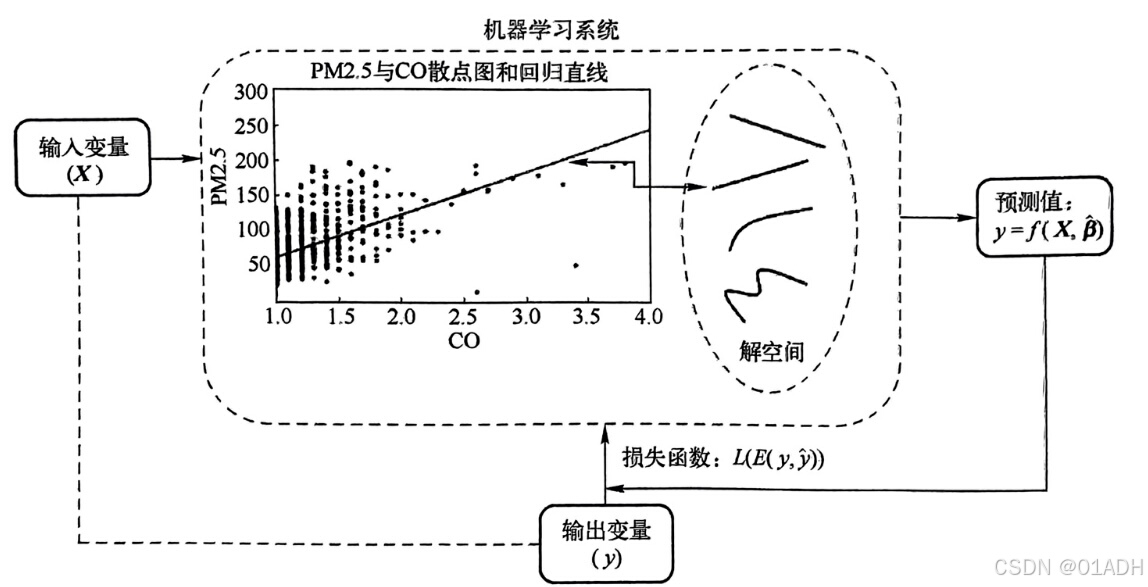
我们将输入变量和输出变量交付给机器学习系统,随后学习系统在解空间的所有解集,搜索与系统输入和输出关系最接近的第j组解,随后给出在该模型参数下的预测值。进一步,计算损失函数并且交付给学习系统,继续在解空间之中搜索更贴近输入和输出关系的参数解。重复该过程,直到损失函数达到最小为止,此时的参数估计,是对数据集的最好拟合。 对于我们如何寻找使损失函数取得最小值的解呢?需要一些搜索策略,例如:梯度下降法、贪心搜索策略等等。
五、预测模型的评价:
1.模型误差的评价指标:
模型误差通常指的是模型预测值与实际观测值之间的差异。它反映了模型在特定数据集上的拟合程度。这里的实际观测值一般指代旧数据。
①回归模型之中的评价指标:
这里介绍均方误差(MSE):
对于所有项的方差相加再除去N即可。MSE越大误差越大,反之MSE越小误差越小。
②对于二类预测模型的误差分析评价指标:
这里引入混淆矩阵的概念:
一般而言我们将二分类之中的1类称之为正类,0类称之为负类。继而产生了4种结果:TP(实际和预测的值都为1),FN(实际为1而预测的结果为0),FP(实际为0而预测结果为1),TN(实际和预测结果均为0)。
基于混淆矩阵的一些度量模型的指标:如总正确率、总错判率、敏感性、特异性等等详见教程课本。
2.模型图形化评价工具:
①ROC曲线:
ROC曲线是一种评估二分类模型性能的工具,它通过在不同的阈值下计算真阳性率(TPR)和假阳性率(FPR),并将这些点绘制在坐标图上,形成一条曲线。ROC曲线通常位于(0, 0)和(1, 1)连线的上方。如果ROC曲线位于这条直线下方,说明分类器的性能较差。ROC曲线离左上角越近,表明分类器的性能越好。左上角的点表示完美分类,即TPR=1,FPR=0。ROC曲线下的面积称为AUC(Area Under Curve),用于量化分类器的整体性能。AUC值越大,分类器的性能越好。
②PR曲线:
PR曲线是一种用于评估二分类模型性能的图形工具,PR曲线以精确度为纵轴,召回率为横轴,展示了在不同阈值下这两个指标的变化关系,PR曲线通常从左至右,召回率逐渐增加(但不一定严格递增),而精确度可能振荡下降。
二者均是基于混淆矩阵而实现的。
3.泛化误差分析:
泛化误差是指模型在未见过的新数据样本上的预期误差,也就是模型对未知数据的预测能力。
①训练误差:
我们知道预测建模的核心目的就是通过数据集估计出预测模型的参数,这是一个基于数据集训练模型的过程。用于模型训练的数据集称之为训练集,其中的样本观测称之为袋内观测。基于训练集的袋内观测,建立模型并且计算得到的模型误差,称之为训练误差或者经验误差。也就是我们前面介绍的模型误差。所以我们不能将训练误差作为泛化误差的估计。
对于训练误差而言:误差的大小与模型复杂度和训练样本量有关。模型复杂度可以用待测的参数来反应,待测参数越多,那么复杂度越高。在恰当的样本量的前提之下:模型复杂度越高,那么对于训练误差就会越小。另一方面,在模型复杂度确定的条件之下,训练误差会随着样本量的增加而下降。
②测试误差:
在建模的过程之中,我们可以知道的是对于未知的数据,是无法作为训练集的。相对于袋内观测,新的数据集都是“袋外观测”。因此,泛化误差都是基于袋外观测。为了满足这样的计算特点,我们一般对于数据而言,我们只选择数据集之中的一部分样本观测作为训练集取训练模型,对于剩下的样本我们选择为测试集。相应的模型在测试集的误差我们称之为测试误差。一般而言。我们选择测试误差作为模型泛化误差的估计。
对于测试误差我们采用与训练误差/模型误差的相同的计算方法。
4.数据集的划分策略:
显然经过对模型误差和泛化误差的理解,我们发现需要将数据集分为训练集和测试集。随后我们在训练集上进行模型的训练,在测试集之中计算数据在模型的测试误差,随后用来评价模型的预测性能。所以对原始数据集的划分也是重要的一步。
①旁置法:
即简单地将数据集随机划分为两部分。一部分将作为训练集(通常包含原始数据集的60%~80%)但该方法仅适合于初始数据集样本量N较大的情况。 样本量N较小的时候训练集会更加小,此时模型不具有”充分学习“的数据条件。
②留一法:
对于数据集中的每个样本,将其从数据集中移除,使用剩余的样本训练模型,然后在该样本上进行预测,记录预测结果。由于每个样本都会被单独作为测试集,因此需要进行与样本数量相等次数的训练和测试。优点:每次迭代都使用最大可能数目的样本进行训练,从而提高了模型的泛化能力;具有确定性,即每次执行的结果都是一致的。缺点:当数据集较大时,计算成本非常高,因为需要训练与样本数量相等次数的模型。
③K-折交叉验证法:
和留一法类似,对于数据集我们将其人为的划分为K份,每一次我们选择K-1个子集作为训练集,剩下的一个子集作为测试集合。重复进行K次。
六、预测模型的选择:
1.基本原则:
①奥卡姆剃刀原则:如果对同一个现象有两种不同的假说,应该采取比较简单的那一种。那么在预测模型的选择问题之中,我们需要从预测精度接近和误差接近的预测模型之中选择复杂度较低的模型。
②原则2:通常,简单模型的训练误差高于复杂模型,但如果其泛化误差低于复杂模型,我们此时选择简单模型。
③原则3:预测模型的最优者应该满足两个条件:训练误差在可接受的范围之内。具有一定的预测稳健性。
2.模型过拟合:
在机器学习和统计建模中,模型对训练数据学习得过于精细,以至于捕捉到了训练数据中的噪声和异常值,导致在新的、未见过的数据上表现不佳的现象。其一个显著的特点:预测模型的训练误差较小但是测试误差较大。
3.预测模型的偏差和方差:
①偏差:偏差是指模型对于新数据集之中的样本观测X,模型给出的多个预测值的期望与实际值的差,测度了预测值由于实际值不一致程度的大小。理论上,预测模型的方程越小越好,说明泛化误差越小。
②方差:预测模型的方差是针对新数据集的样本观测X,模型给出多个预测值的方差。测度了多个预测值波动程度的大小。其方程越小,说明模型具有鲁棒性(指系统或模型在面对不确定性、异常值或噪声等不利因素时的抵抗能力,即系统或模型保持稳定性和可靠性的能力)。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









