







一句话总结
先验概率P,乘以似然函数L,正比于后验概率。
重点
先验概率,后验概率和似然函数的关系

如上图,图中的公式有误,应该是
P(E|H) 就是似然函数, P(E) 相当于是一个归一化项,整个公式就是表达了“后验概率正比于先验概率乘以似然函数”。
Likelihood function 和 probability的区别
Probability is used before data are available to describe possible future outcomes given a fixed value for the parameter (or parameter vector). Likelihood is used after data are available to describe a function of a parameter (or parameter vector) for a given outcome.
The likelihood of a set of parameter values, θ, given outcomes x, is equal to the probability of those observed outcomes given those parameter values, that is
举例说明,掷硬币的例子,每次有50%的概率掷出正面;而如果掷了一枚硬币100次,这个硬币有50次正面朝上,那么这个硬币是均匀的可能性是多少。“似然概率”可以理解成“像这个样子发生的概率”。对于50次正面朝上这样一个结果,我们可以拿极大似然估计来求出这个“可能性”
极大似然估计(MLE)和极大后验估计(MAP)
一个没有正则化项的LR其实就是极大似然估计,加入了正则化项就是加入了先验,就成了极大后验估计。
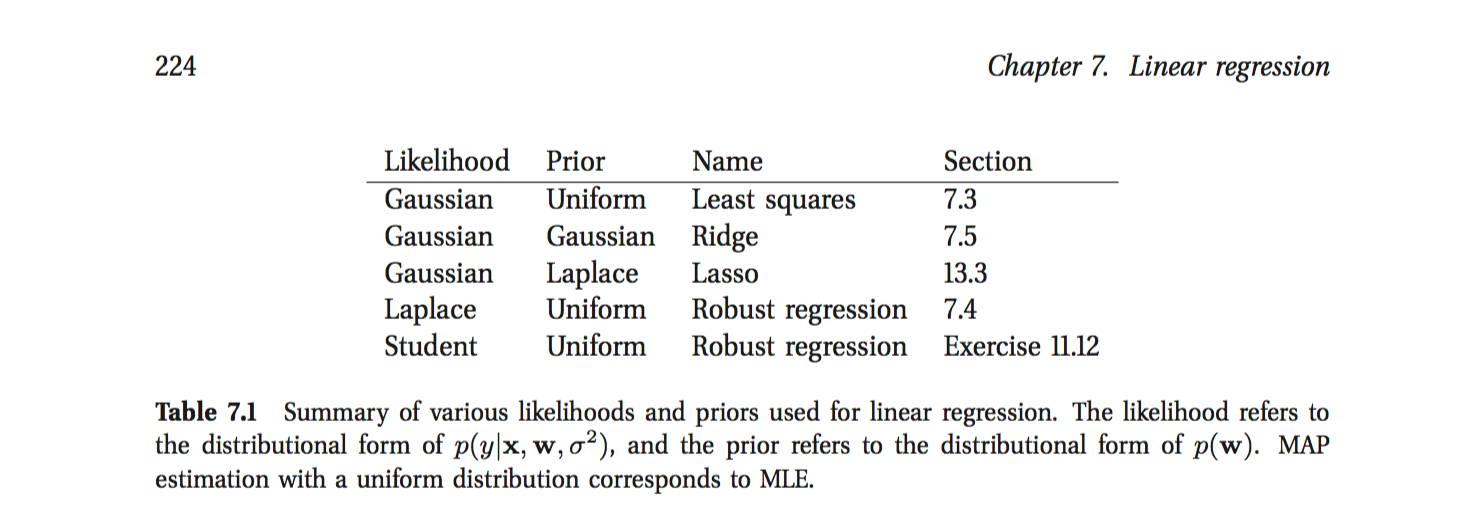
假定样本服从高斯分布,对样本做极大似然估计,就会得到最小二乘的损失函数;如果对weights加入先验,就成为极大后验估计。


参考
https://en.wikipedia.org/wiki/Maximum_a_posteriori_estimation
https://en.wikipedia.org/wiki/Maximum_likelihood_estimation
MLAPP 1.4.5 Linear regression
参考文献
Scalers的两篇文章http://mp.weixin.qq.com/s?src=3×tamp=1467648494&ver=1&signature=XKymJ5tpDbq*qGGgJc68A-jqDVzLmtEHNzJv5VjZ3RLXt3YheNcXf530pWqfPDvOSWZ2JDl6qEZ*Bc72DtiPJEMttrgExkv*cYBA06sWaaXaJSm0IaC2juto5TYkIhnJw*q4kCbYrQxmB5pzvSAbHQ==和
http://mp.weixin.qq.com/s?__biz=MzA4MjIyNDYzMQ==&mid=200606852&idx=1&sn=626f4251a07ca4eb315718f231b0a7dd&scene=7#wechat_redirecthttps://en.wikipedia.org/wiki/Likelihood_function#Historical_remarks
http://www.ruanyifeng.com/blog/2011/08/bayesian_inference_part_one.html















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









