






推荐系统是 1992 年施乐公司的 David Goldberg 在论文中首次提出的。人类历史上第一个发表的推荐系统算法是协同过滤。该算法长期占据着主导地位。一直到最近,仍然有研究者发问称对比了大量的推荐算法,发现基于物品的协同过滤性能优异,吊打其他算法。

随着时间的推移,出现了越来越多的推荐系统算法。1998年,亚马逊公司的员工发明了基于物品的推荐系统。随后在 2006 年,因为 Netflix 推荐系统大赛的缘故,基于矩阵分解的推荐系统被发明出来。随后在 2010 年左右,线性模型和排序学习算法风靡一时。从 2016 年开始,基于深度学习的推荐算法后来居上,一举占据了包括 RecSys 在内的各大学术会议的显要位置,给推荐系统领域带来了一场彻底的革命。
2017 年开始,人工智能领域的研究者开始广泛关注人工智能伦理问题。随后,推荐系统的具体场景落地问题得到了关注,尤其是序列化推荐,成为了热门研究课题。本文将带领读者阅读数据挖掘顶级会议 ACM KDD 2023 年的论文 Text Is All You Need: Learning Language Representations for Sequential Recommendation。论文的作者来自美国高校 UCSD 和美国公司亚马逊。
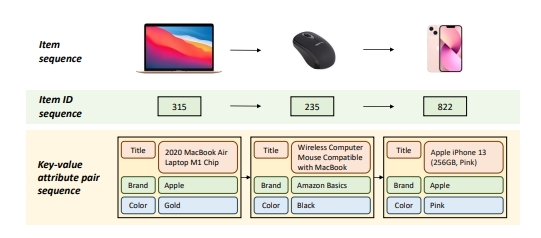
图一输入数据中用户信息
图一中显示了这篇文章中的算法利用的输入数据与其他算法的不同:物品不再是由物品 ID 唯一表示的数字,而是一个键值对构成的数据集合。例如,一台苹果笔记本电脑,不再由一个数字 315 表示,而是由产品名称、品牌名称和颜色代表的数据集合表示。
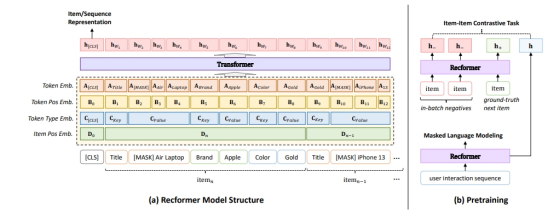
图二算法架构图
在作者设计的算法架构中,共有 4 个嵌入层:
- 元素嵌入向量:键值对中每个元素的嵌入向量
- 元素位置向量:用于表示元素在序列中位置的向量
- 元素类型向量:用于表示元素类型的向量
- 物品位置向量:用于表示物品在序列中位置的向量
算法架构在 4 个嵌入层求和之后加入了一个 Layer Normalization 层:
![]()
随后我们得到嵌入层的终极表示方法:
![]()
我们随后利用双向 Transformer 结构 Longformer 对嵌入层编码,得到物品的嵌入式向量表示:
![]()
给定序列 S,序列中下一个出现的物品为物品 i 的评分由下述公式计算:
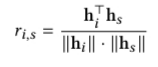
预测出现的物品 i 为使上面公式得分值最高的物品:
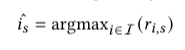
为了让算法效率更高,作者提出了预训练模型+两阶段微调算法来实现算法架构:
为了使上面的算法执行速度更加高效,研究者提出了利用预训练模型来实现上述算法结构。第一种预训练模式是 MLM,也就是 Masked Language Modeling 。MLM 的算法架构流程如下:
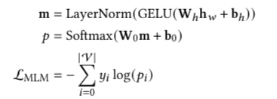
另一种预训练模式是 item-item contrative (IIC)。这种预训练模式的损失函数定义如下:
![]()
在算法的实际执行中,我们采用了加权和的形式:
![]()
最后,我们对算法做两阶段微调。算法的伪代码如下:

作者最后在论文中针对该算法做了对比实验:
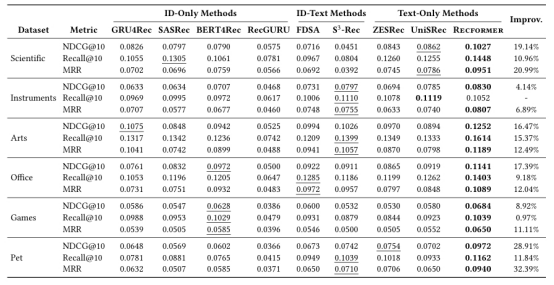
通过实验,我们发现作者在论文中提出的算法性能优越。
推荐系统自诞生以来,算法架构变得越来越复杂。随着大模型的兴起,如何利用大模型进行推荐也成为了研究的热点。如果有一天大模型被证明能使推荐的效果明显好于其他方法,推荐系统的研发将被集中在极少数有能力提供数据和大规模 GPU 集群的公司。因此,趁着这一切还没有发生,广大中小企业,还有高校师生,以及独立研究者应该抓紧时间为这一领域增砖添瓦。
















 2115
2115

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











