










视觉大模型,也称为视觉Transformer,是近年来计算机视觉领域的一大突破。这种模型在图像识别、目标检测、语义分割等任务中表现出色,成为深度学习领域的研究热点。本文将通过万字长文,对视觉大模型进行全面解读,包括其原理、应用、优缺点以及未来发展趋势。
一、视觉大模型的原理
视觉大模型基于Transformer架构,由自注意力机制和位置编码两部分组成。自注意力机制使模型能够关注输入数据中的重要部分,而位置编码则帮助模型理解图像中元素的位置关系。通过这两部分,视觉大模型能够捕捉图像中的全局和局部信息,从而在各种计算机视觉任务中取得优异的表现。
二、视觉大模型的应用
1、图像识别
图像识别是视觉大模型最直接的应用场景。通过训练,模型可以识别出图像中的物体类别、人脸表情等。例如,在ImageNet大规模视觉识别挑战赛中,使用视觉大模型的参赛者取得了极高的准确率。
2、目标检测
目标检测是计算机视觉领域的另一重要任务。视觉大模型能够准确识别出图像中的物体,并给出其位置信息。常用的目标检测算法包括Faster R-CNN、YOLO等,它们都可以与视觉大模型结合,提高检测准确率。
3、语义分割
语义分割要求模型将图像中的每个像素分配给相应的类别。视觉大模型能够捕获图像的全局信息,从而更准确地完成语义分割任务。例如,使用Mask R-CNN算法结合视觉大模型,可以实现高精度的语义分割。
三、视觉大模型的优缺点
1、优点
(1)全局信息捕捉:视觉大模型能够捕获图像中的全局信息,从而更准确地识别物体和场景。
(2)高准确率:在各种计算机视觉任务中,使用视觉大模型的模型具有较高的准确率。
(3)可扩展性:视觉大模型的架构可以很容易地扩展到更大的规模,以处理更复杂的任务。
2、缺点
(1)计算量大:由于视觉大模型的参数数量巨大,导致其计算量很大,需要高性能的硬件支持。
(2)训练时间长:由于模型规模较大,训练时间较长,需要大量的数据和计算资源。
(3)调参难度高:视觉大模型的超参数较多,调参过程较为复杂,需要经验丰富的工程师进行操作。
四、视觉大模型的训练与优化
视觉大模型的训练涉及数据采集、数据预处理、模型结构设计和训练技巧等多个环节。训练过程中的优化算法和损失函数的选择对模型性能至关重要。此外,推理加速技术,如模型剪枝、量化和压缩,也被广泛应用于提高模型推理速度和降低计算成本。
五、未来发展趋势
随着技术的不断发展,视觉大模型仍有很大的发展空间。未来可能出现以下趋势:
- 模型优化:通过改进模型架构、优化算法等方式,降低视觉大模型的计算量和参数量,提高其训练和推理速度。
- 跨模态融合:将视觉大模型与其他模态的数据(如文本、音频等)进行融合,实现跨模态的语义理解和生成任务。
- 端到端学习:通过端到端的训练方式,直接将原始图像输入到模型中,让模型自动提取特征并进行分类或检测等任务,提高模型的自适应能力。
- 可解释性研究:研究如何提高视觉大模型的解释性,使其在推理过程中能够给出更清晰、更有逻辑的解释。
- 应用拓展:将视觉大模型应用于更多的实际场景中,如自动驾驶、智能安防等,推动计算机视觉技术的发展和普及。
总之,视觉大模型是当前计算机视觉领域的重要研究方向之一。虽然其存在一些缺点和挑战,但随着技术的不断进步和应用场景的不断拓展,相信这些问题会逐步得到解决。让我们一起期待视觉大模型的未来发展吧!
六、产业落地化现状
1、百度文心 UFO 2.0
近年来预训练大模型一次次刷新记录,展现出惊人的效果,但对于产业界而言,势必要面对如何应用落地的问题。当前预训练模型的落地流程可被归纳为:针对只有少量标注数据的特定任务,使用任务数据 fine-tune 预训练模型并部署上线。然而,当预训练模型参数量不断增大后,该流程面临两个严峻的挑战。首先,随着模型参数量的急剧增加,大模型 fine-tuning 所需要的计算资源将变得非常巨大,普通开发者通常无法负担。其次,随着 AIoT 的发展,越来越多 AI 应用从云端往边缘设备、端设备迁移,而大模型却无法直接部署在这些存储和算力都极其有限的硬件上。
针对预训练大模型落地所面临的问题,百度提出统一特征表示优化技术(UFO:Unified Feature Optimization),在充分利用大数据和大模型的同时,兼顾大模型落地成本及部署效率。VIMER-UFO 2.0 技术方案的主要内容包括:
⑴ All in One:行业最大 170 亿参数视觉多任务模型,覆盖人脸、人体、车辆、商品、食物细粒度分类等 20+ CV 基础任务,单模型 28 个公开测试集效果 SOTA。
⑵ One for All:首创针对视觉多任务的超网络与训练方案,支持各类任务、各类硬件的灵活部署,解决大模型参数量大,推理性能差的问题。
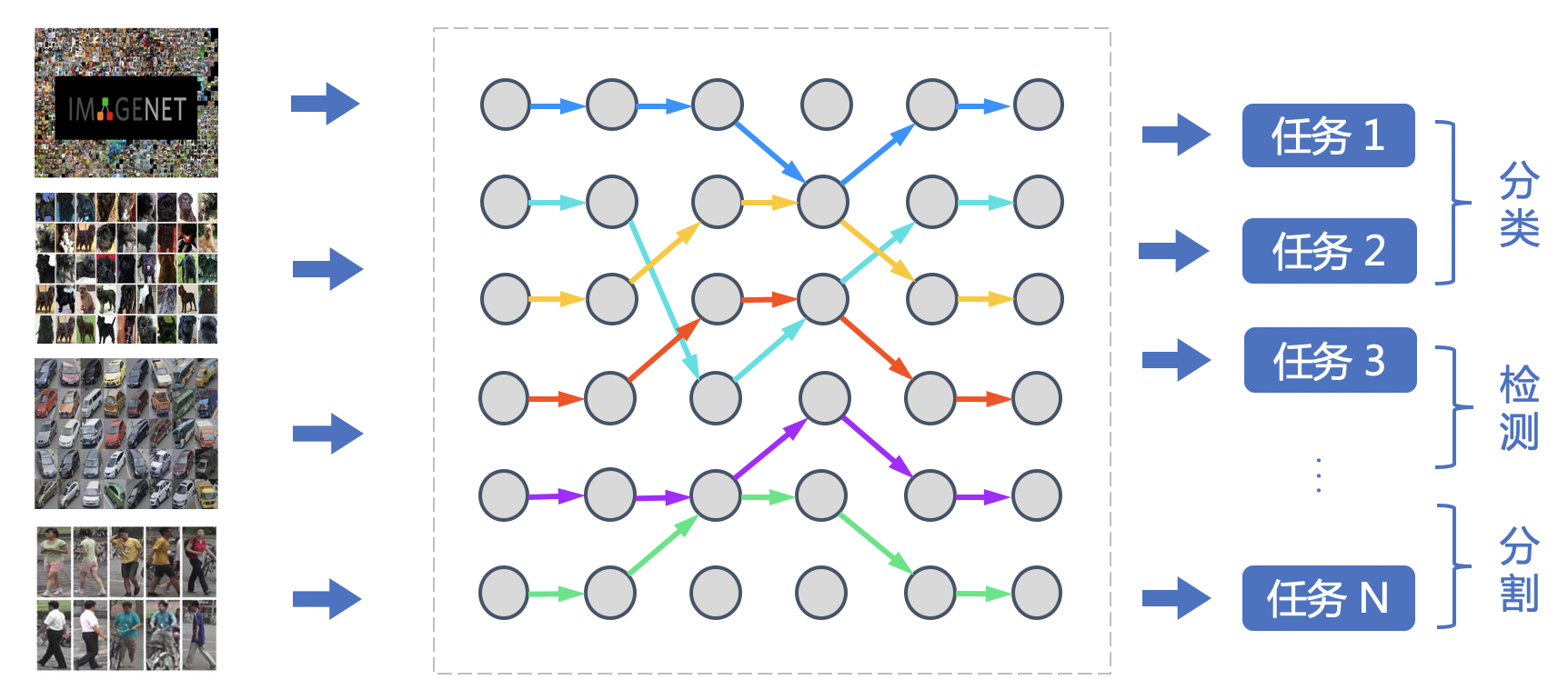
VIMER-UFO 2.0 大模型可被广泛应用于智慧城市、无人驾驶、工业生产等各类多任务 AI 系统。同时 VIMER-UFO 2.0 支持多种应用模式配合,兼顾效率和效果。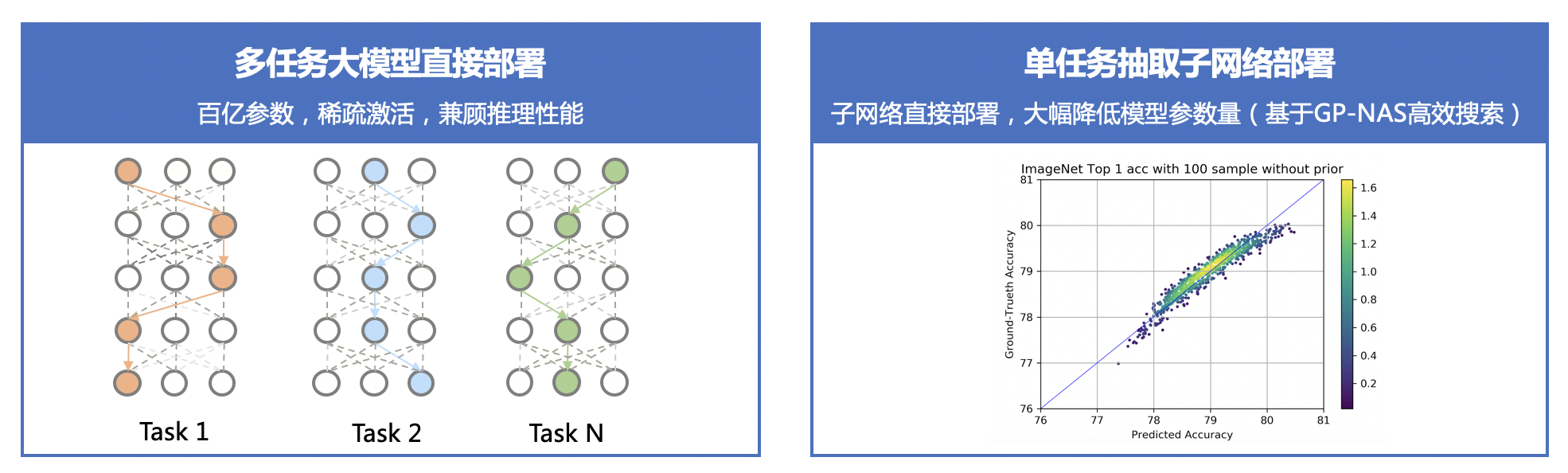
2、华为 盘古CV视觉大模型
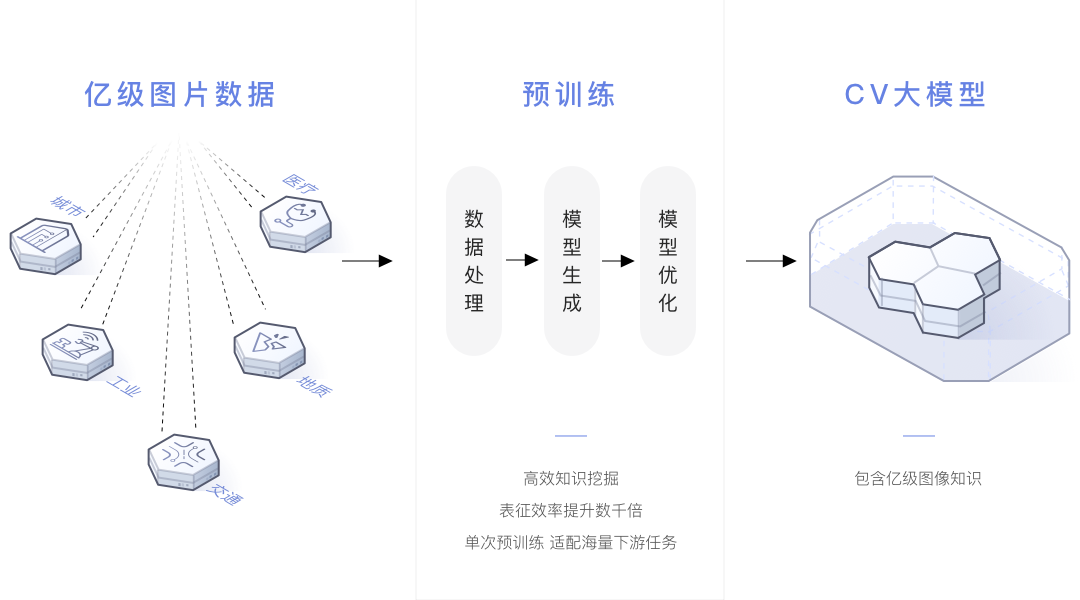
2021年4月份华为发布盘古系列大模型,首次实现模型按需抽取的业界最大CV大模型,首次实现兼顾判别与生成能力
基于模型大小和运行速度需求,自适应抽取不同规模模型,AI应用开发快速落地。使用层次化语义对齐和语义调整算法,在浅层特征上获得了更好的可分离性,使小样本学习的能力获得了显著提升,达到业界第一。做到了
⑴ 当时业界最大CV模型
⑵ 判别与生成联合预训练
⑶ 100+ 场景验证
⑷ 小样本学习性能领先
3、商汤 INTERN 大模型
上海人工智能实验室联合商汤科技、香港中文大学、上海交通大学,共同发布新一代通用视觉技术体系“书生”(INTERN),该体系旨在系统化解决当下人工智能视觉领域中存在的任务通用、场景泛化和数据效率等一系列瓶颈问题。全新的通用视觉技术体系命名为“书生”,意在体现其如同书生一般的特质,可通过持续学习,举一反三,逐步实现通用视觉领域的融会贯通,最终实现灵活高效的模型部署。“书生”通用视觉技术将实现以一个模型完成成百上千种任务,体系化解决人工智能发展中数据、泛化、认知和安全等诸多瓶颈问题。
通用视觉技术体系“书生”(INTERN)由七大模块组成,包括通用视觉数据系统、通用视觉网络结构、通用视觉评测基准三个基础设施模块,以及区分上下游的四个训练阶段模块。“书生”的推出能够让业界以更低的成本,获得拥有处理多种下游任务能力的AI模型,并以其强大的泛化能力支撑智慧城市、智慧医疗、自动驾驶等场景中大量小数据、零数据等样本缺失的细分和长尾场景需求。
在“书生”的四个训练阶段中,前三个阶段位于该技术链条的上游,在模型的表征通用性上发力;第四个阶段位于下游,可用于解决各种不同的下游任务。 第一阶段,着力于培养“基础能力”,即让其学到广泛的基础常识,为后续学习阶段打好基础。 第二阶段,培养“专家能力”,即多个专家模型各自学习某一领域的专业知识,让每一个专家模型高度掌握该领域技能,成为专家。 第三阶段,培养“通用能力”,随着多种能力的融会贯通,“书生”在各个技能领域都展现优异水平,并具备快速学会新技能的能力。 在循序渐进的前三个训练阶段模块,“书生”在阶梯式的学习过程中具备了高度的通用性。 当进化到第四阶段时,系统将具备“迁移能力”,此时“书生”学到的通用知识可以应用在某一个特定领域的不同任务中,如智慧城市、智慧医疗、自动驾驶等,实现广泛赋能。
准备了三大资源包:100GAI资源包+大模型资料包+论文攻略资源包(需要那个记得说明)
论文指导发刊+kaggle组队+技术问题答疑
关注工重号:AI技术星球 发送211 领qu资料包:1.Transformer、BERT、Huggingface三大基础模型源码资料
2.ChatGLM、LLM、LangChain、Lora等大语言模型预训练及微调教程和源码资料
3.2024最新大模型相关面试题
4.大模型前沿论文及前世今生合集5、大模型书籍
整理不易,欢迎大家点赞评论收藏!
手把手带你从做科研到论文发表,一条龙全方位指导!
避免各种常见or离谱的坑,顺顺利利学习,快快乐乐毕业~
0基础也能发论文吗? 导师放养? 毕业压力?
找不到热点课题和方向、没有idea、没有数据集,实验验证不了、代码跑不通
没有写作基础、不知道论文的含金量,
高区低投、不清楚不了解完整的科研经验,
评职称、申博压力、自我高区位的追求 都可以找我了解















 4034
4034

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









