







本課課程:
- 零基礎实战Scala 函数式编程
- Spark 源碼中的 Scala 函数式编程鑒賞
Spark 源碼中的 Scala 函数式编程鑒賞
這些是函数,里面傳進出的方法要麼是自己本身,要麼是自己的子類。
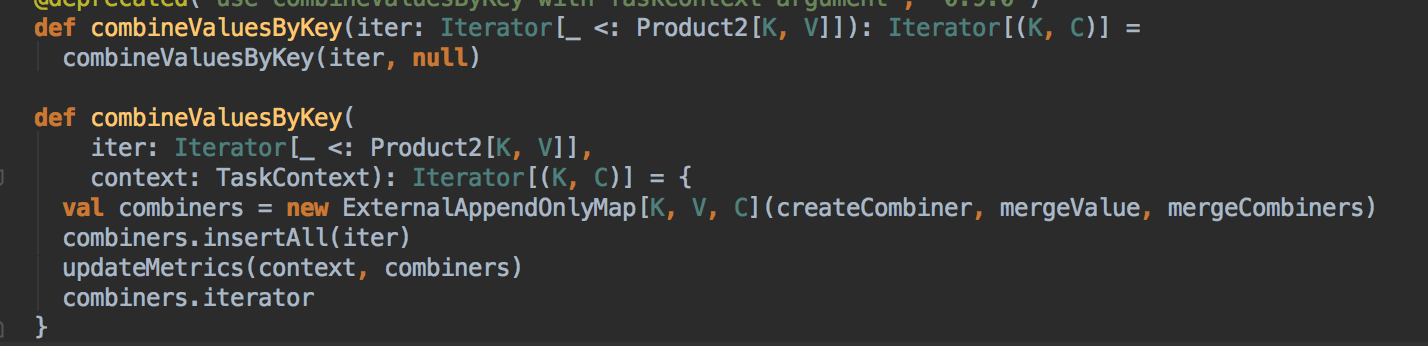
沒有函数體表明這是抽象函数
這里 SparkContext 函数里有一個 sc,這個 sc 又是另外一個函数(這里是一個函数赋值給另外一個函数的例子)

零基礎實戰 Scala 函数式编程
函数可以被简单的被认为是包裹了一条或者几条语句的代码体,该代码体接收若干参数,经过代码体处理后返回结果,形如数学中的f(x) = x +1。在Scala中函数式一等公民,可以像变量一样
被传递,被赋值,同时函数可以赋值给变量,变量也可以赋值给函数,之所以可以是这样,原因在于函数背后是类和对象,也就是说在运行的时候函数其实是一个变量!!!当然,背后的类是Scala语言自动帮助我们生成的,且可以
天然的被序列化和反序列化,这个意义非常重要:
- 意义1:可以天然的序列化和反序列化的直接好处就是函数可以在分布式系统上传递!!!
- 意义2:因为函数背后其实是类和对象,所以可以和普通的变量完全一样的应用在任何普通变量可以运用的地方,包括作为参数传递,作为返回值,被变赋值和赋值给变量等;
补充:整个IT编程技术的发展史,其实就是一部封装歷史:

- Function时代:在C语言中提供了函数的概念,用函数把若干条语句进行封装和复用;
- Class时代:在C++和Java等语言中提供了类和对象,把数据和处理数据的业务逻辑封装起来;
- 框架时代:把数据、代码和驱动引擎封装起来,是过去10年和未来10年IT技术的核心
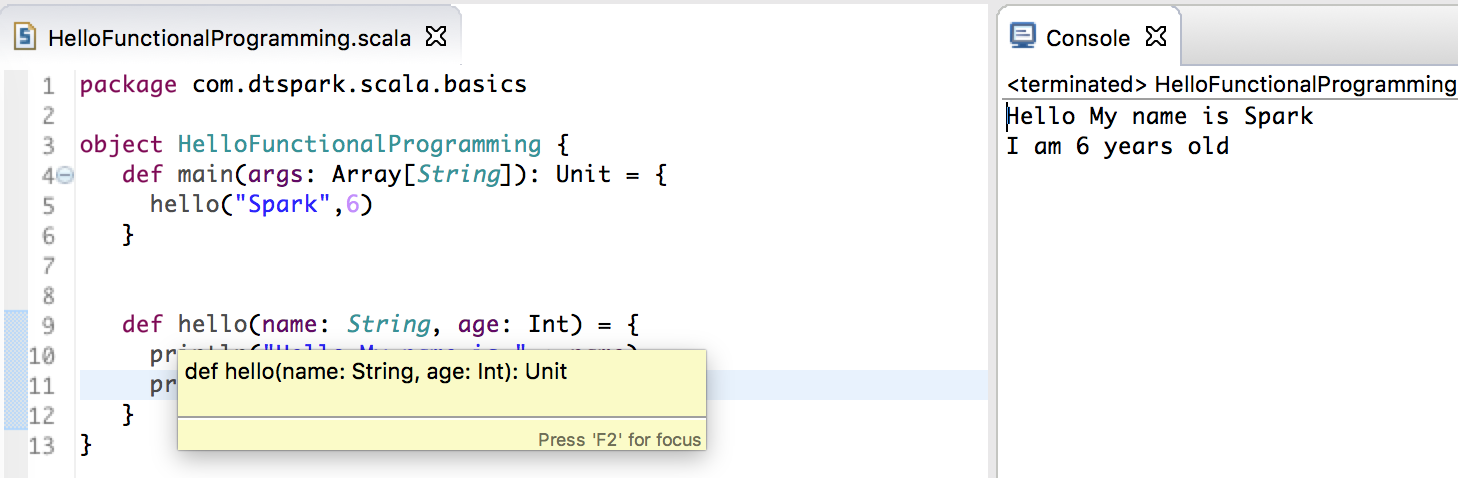
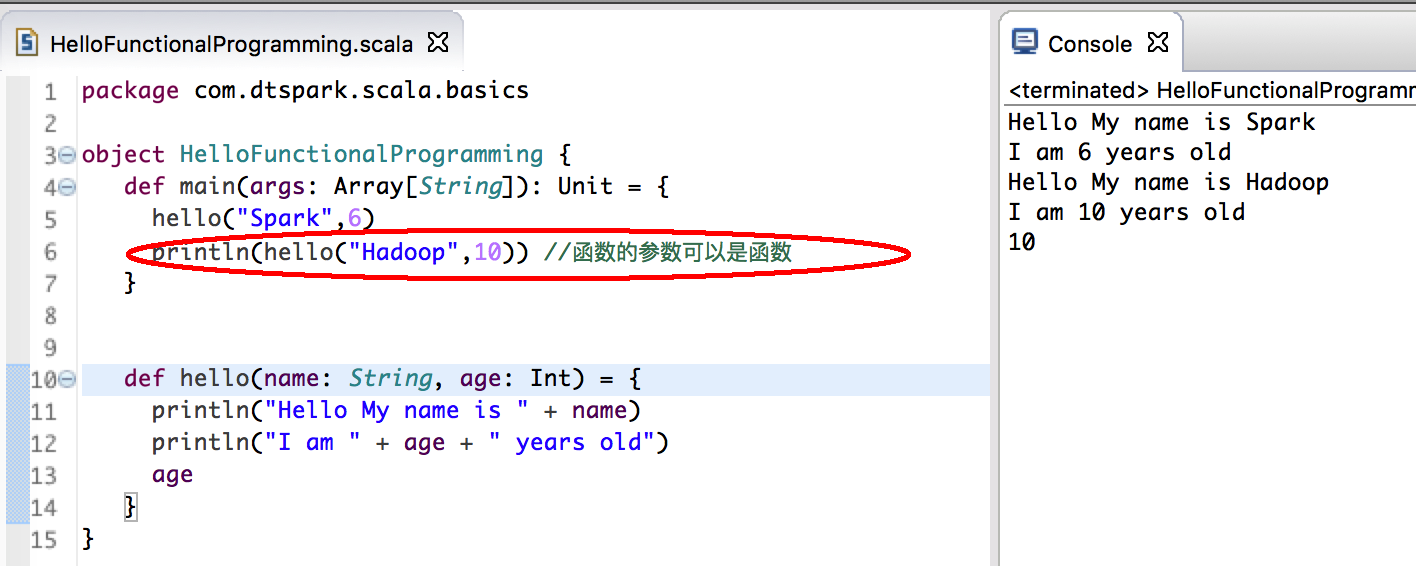
- def关键字来定义函数;
上一節課已經說明了类型是根據最后一条语句值的类型,所以當我們的方法體里有兩個 print 方法,這個函数返回的類型是 Unit;
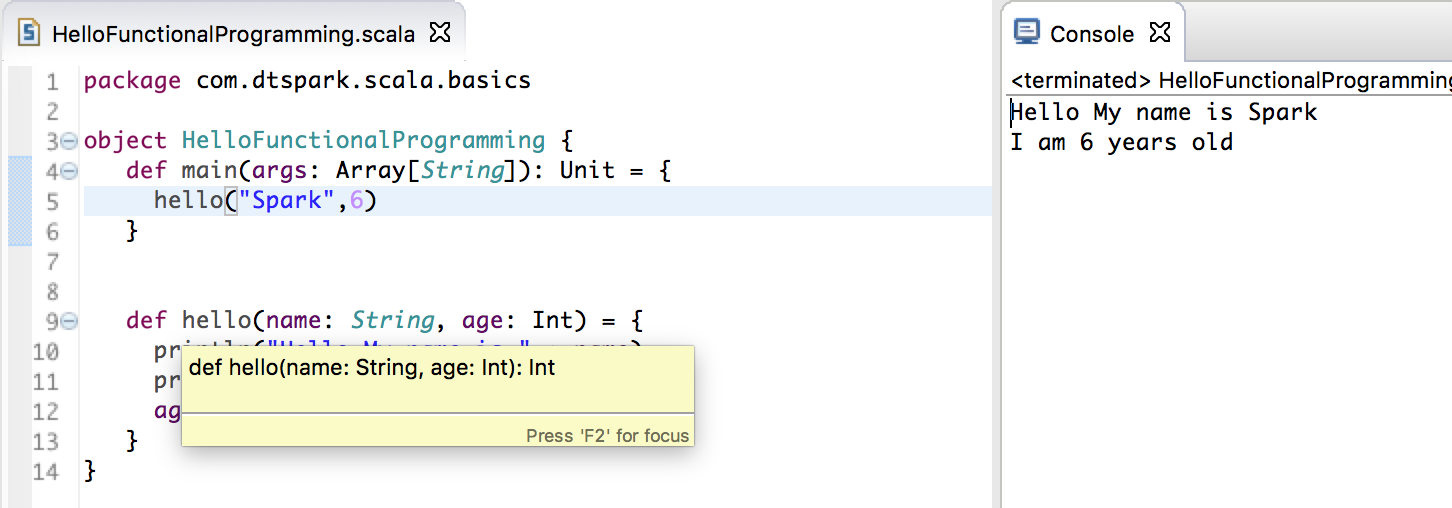
所以當我們的方法體里的兩個 print 方法後寫下 age 作為最後一個返回值的時候,這個函数返回的類型是 Integer;
所以當我們的方法體里的兩個 print 方法後寫下 name 作為最後一個返回值的時候,這個函数返回的類型是 String;
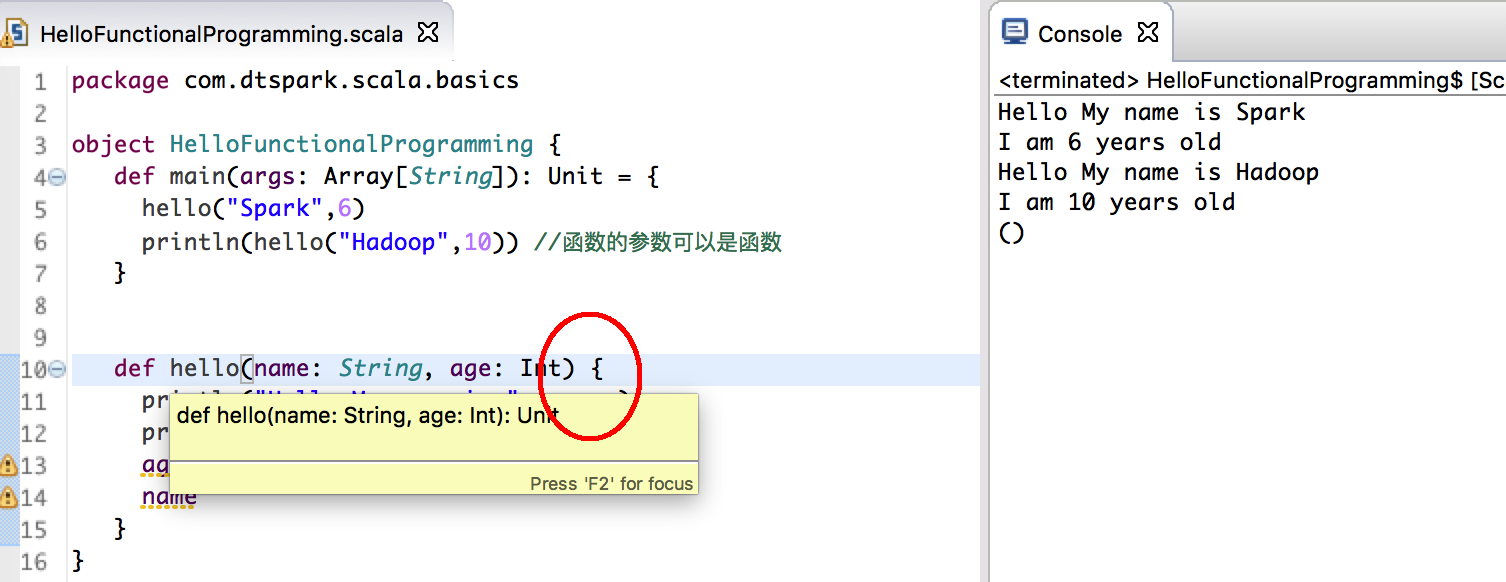
- 函数会自动进行类型推断来确定函数返回值的类型,如果函数名称和函数体之间没有等于号的话则类型推断失效,此时函数的类型是Unit (如果我們去掉了 = 號,返回值也會變成 Unit)
- 函数的参数可以是函数;
- 如果在函数体中无法推导出函数的类型,则必须声明具体的类型,例如下面的 fibonacci;
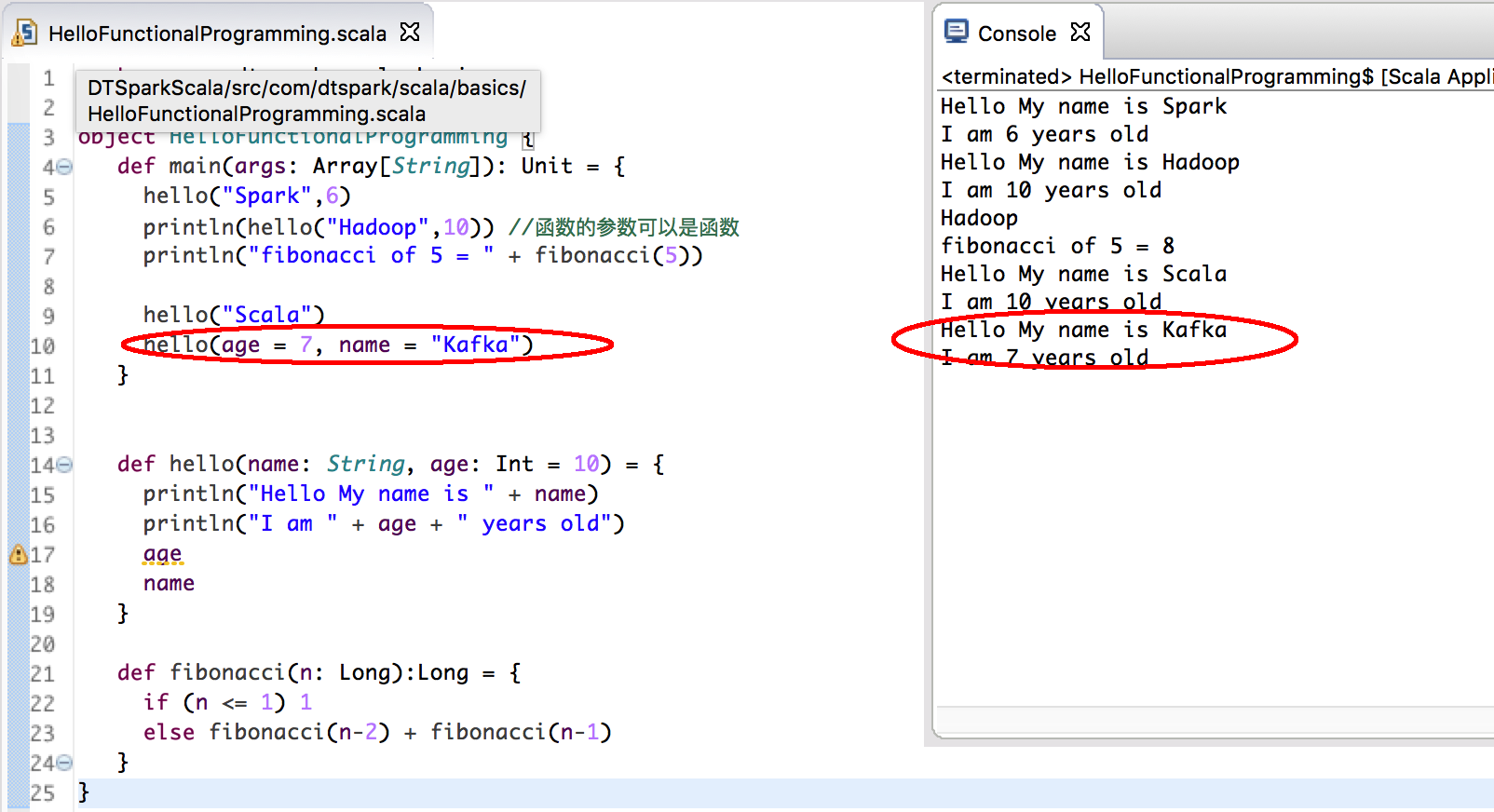
- 函数的参数可以有默认值,这样在调用函数的时候如果不想改变默认值的话就直接不传递该参数而是直接使用默认值即可,这在实际的编程中意义重大,尤其是在Spark等框架中,因为框架一般都有自己的默认配置和实现,此时我们就可以非常好的使用默认值;
- 我们可以基于函数的参数的名称来调整函数的传递参数的顺序,重点在于为什么可以这么做呢?原因在于函数背后其实是类,其参数就是类的成员,所以无所谓顺序!
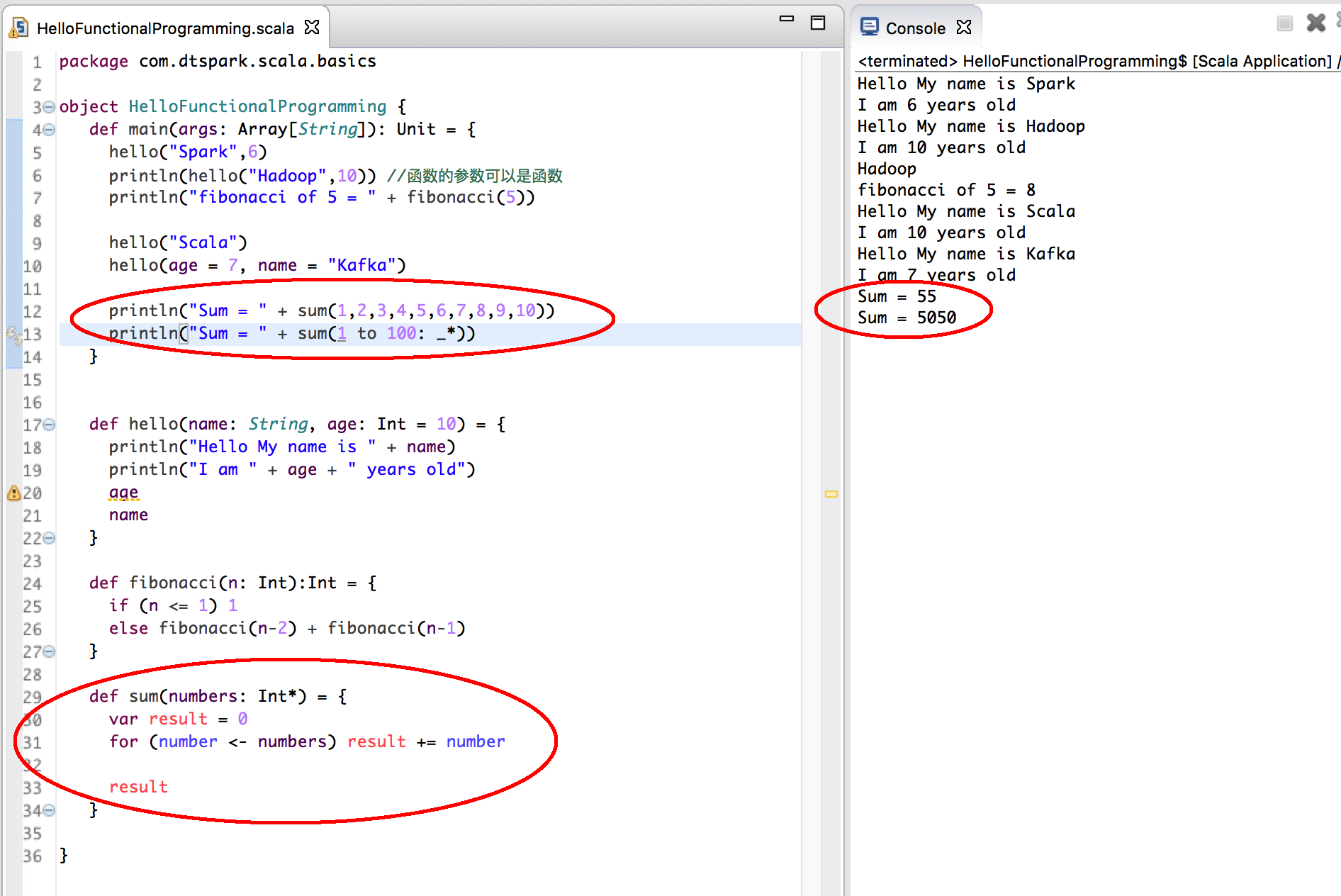
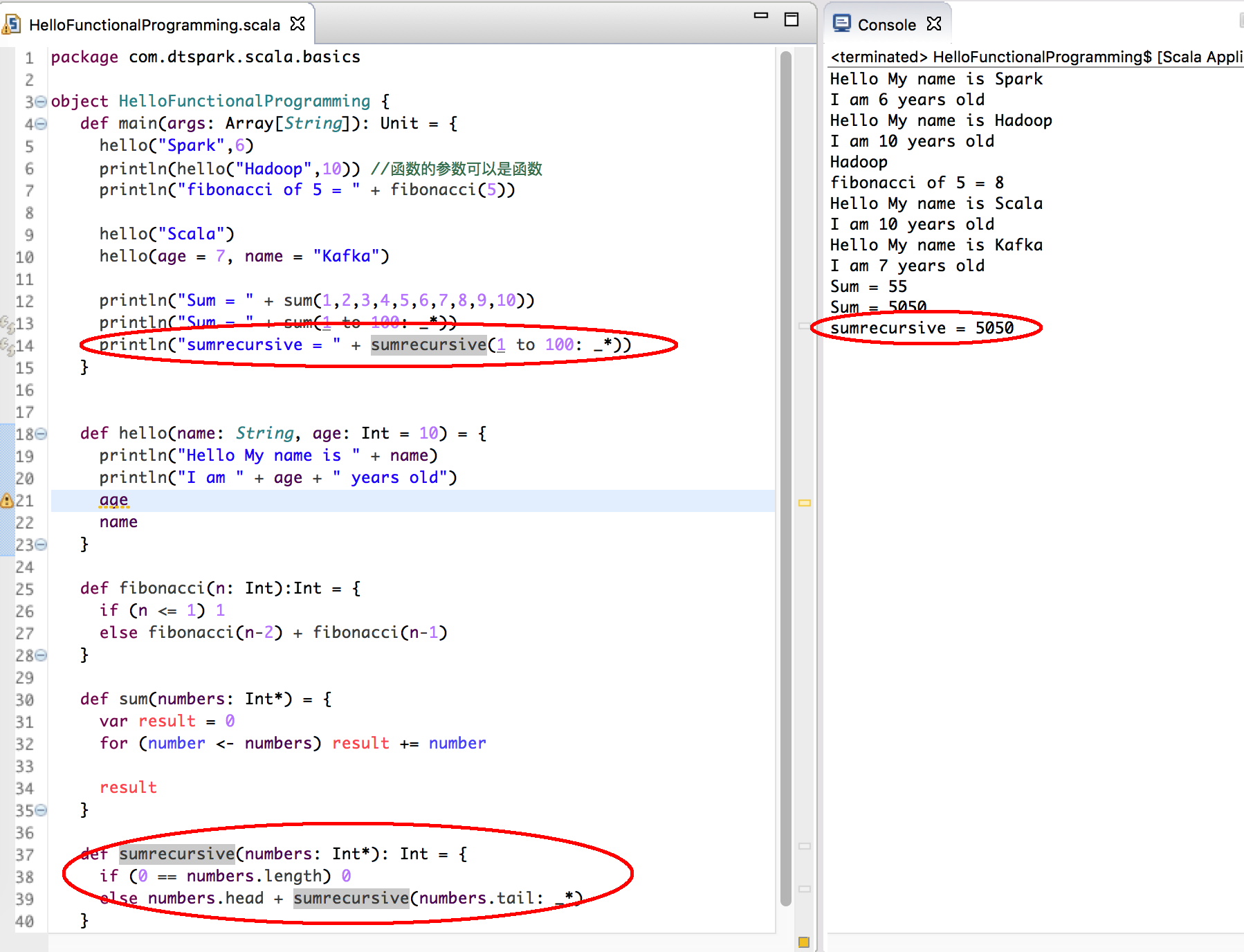
- 函数中如果不确定传递参数的个数,可以使用变长参数的方式;传参时候的一个方便的语法是: _*
- 可变参数中的数据其实会被收集成为Array数组,我们在入口方面main中其实就是可变参数,是以Array[String]的方式呈现的;



感谢阅读
Janice
——————————————————————————————–—————————————————————————
Sharing is Good, Learning is Fun.
今天很残酷、明天更残酷,后天很美好。但很多人死在明天晚上、而看不到后天的太阳。 – 马云 Jack Ma
以下是笔记参考来源:
资料来源于: 大数据Spark “蘑菇云”行动前传第5课:零基础实战Scala函数式编程及Spark源码解析
视频来源于: http://www.tudou.com/listplay/rd3LTMjBpZA/taE_Z5Yu6WE.html
如果您对大数据Spark感兴趣,可以免费听由王家林老师每天晚上20:00开设的Spark永久免费公开课,地址YY房间号:68917580
















 587
587

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









