







本次分享将展示如何利用Scrapy爬取网页中的图片。爬取的网页如下:

首先建立sina_trip项目:
scrapy startproject sina_trip在settings.py中,添加以下代码:
ITEM_PIPELINES = {'scrapy.pipelines.images.ImagesPipeline': 1} # 开启图片下载
IMAGES_URLS_FIELD = 'url' # 图片的网址字段为url
IMAGES_STORE = r'.' # 图片储存地址为当前目录items.py中的代码如下:
import scrapy
# 创建字段,本例中只需要图片的网址,故只有一个字段url
class SinaTripItem(scrapy.Item):
url = scrapy.Field()之后在spiders文件夹下新建文件sina_trip_spider.py,代码如下:
import scrapy
from scrapy.spiders import Spider
from scrapy.selector import Selector
from sina_trip.items import SinaTripItem
# 创建爬虫,用于爬取网页中的图片
class sinaTripSpider(Spider):
name = "sinaTripSpider" # 爬虫的名称
start_urls = ["http://travel.sina.com.cn/"] #需要爬取的网址
def parse(self, response): #parse function
item = SinaTripItem() # 创建字段实例
sel = Selector(response) # 创建网页选择器,用于选取网页中的元素
sites = sel.xpath("//img/@src").extract() # 提取网页中所有图片的网址
for site in sites:
item['url'] = ['http:'+site] # 视爬取的图片网址决定是否加'http'
yield item在终端输入命令:
scrapy crawl sinaTripSpider运行结果如下:
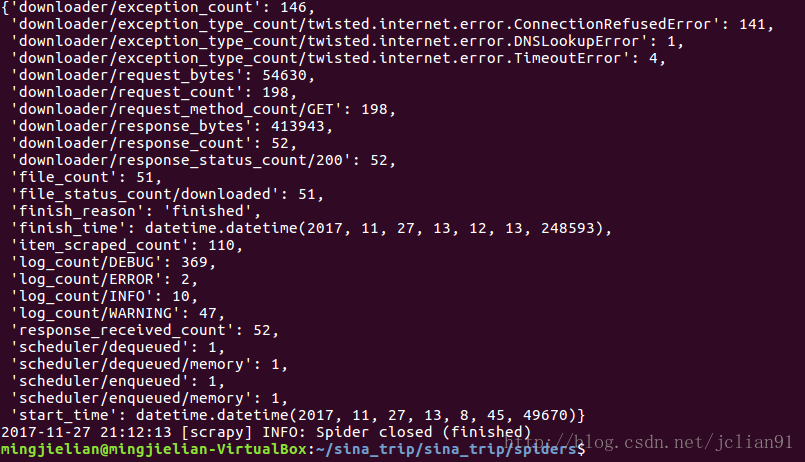
运行完后,在spiders文件夹下会多出full文件夹,这是图片下载后保存的文件夹地址:

full文件夹里面的图片如下:

Bingo,我们的图片爬虫也成功啦~~但是美中不足的是,图片保存的名称是用Hash值加密过的,可能并不是我们想要的图片名称,笔者会在之后的文章中讲到如何自定义保存后的图片的名称。欢迎大家持续关注~
本文的Github地址如下,欢迎大家访问哈:https://github.com/jclian91/scrapy-for-sina_trip-
本次分享到此结束,欢迎大家批评与交流~~
注意:本人现已开通两个微信公众号:因为Python(微信号为:python_math)以及轻松学会Python爬虫(微信号为:easy_web_scrape), 欢迎大家关注哦~~















 3626
3626

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









