




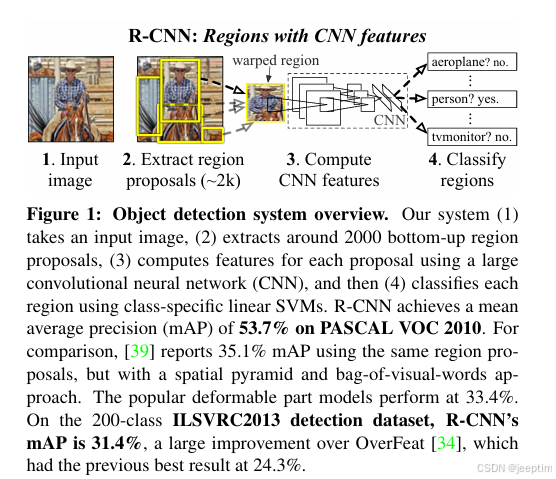
RCNN
基本架构:选择性搜索算法(SS)+CNN+SVM+线性回归模型
缺点:需要分开训练CNN\SVM\线性回归模型,因此无法做到端到端训练;因为每张图片需要提取2000个候选区域,每个区域需要特征数量大,因此推理速度极慢且占用内存大。
选择性搜索算法:为了提升区域选择效率而使用的算法,该算法相较于穷举法有较大提升,其本质是图像分割算法。首先初始化区域集,计算相邻区域相似度,具有高相似度区域合并到一起。具体的相似度计算分为四个子模块(颜色、纹理、尺度、填充)。颜色和纹理是判断区域相似度的基本要素;尺度相似度则是为了避免合并后的区域不断吞并周围区域,造成无效的区域划分;填充相似度则是为了解决物体间的包含关系(如:车轮在汽车上、眼睛在动物身上)。最终将四个模块归一化求和计算。具体的公式可以参考:选择性搜索算法(Selective Search)超详解(通俗易懂版)-CSDN博客
CNN:用于提取候选区域的图像特征,这一步中可以采用的卷积神经网络可以有很多种(Resnet、Inception、VGG等),最初的RCNN仅提取网络的高层特征,即被多次下采样后的高级抽象特征。因此无法很好的提取小目标。
SVM:用于对特征进行类别分类,使用n个svm组成的权值矩阵(n为分类数)与特征矩阵相乘,得到最终的概率矩阵。使用非极大抑制对每类样本的进行处理剔除重叠建议框,保留高分框。SVM本质上是二分类分类器,通过核技巧将特征映射到高维空间来处理线性不可分样本,通过叠加多个SVM分类器可以处理这样的多分类问题(也称为One-vs-All (OvA) 或 One-vs-Rest 方法)。
线性回归模型:用于微调非极大抑制筛选后的边界框。在训练期间,通过比较预测的边界框和真实目标边界框之间的差异来计算回归损失。回归损失用于调整回归器的权重,以使其能够更准确地预测边界框的位置。
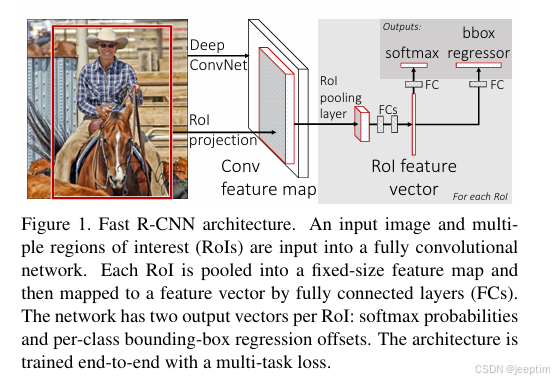
fast-RCNN
基本框架:选择性搜索算法+CNN+ROI pooling+softmax+线性回归模型
改进:RCNN中将每个感兴趣区域转换成相同尺寸再使用CNN提取特征,每个感兴趣区域分别提取特征消耗计算资源极大。fast-RCNN将整张图片输入CNN获得整体特征,再将选择性搜索算法的感兴趣区域投影到图像中,获得相应的特征矩阵。然后将每个特征矩阵经ROI pooling缩放到7*7大小特征图,特征图再输入进softmax分类器与线性回归模型中对类别和边界框位置进行预测。在训练和预测速度上相较于RCNN有较大提升。
ROI pooling:实际上是将图像每个维度划分为7*7的区域,对每个区域执行最大池化。
损失计算:不同RCNN训练时分开计算边界框和分类损失,fast-RCNN将特征图并联输入到softmax分类器与线性回归模型中,因此将分类损失与边界框损失的和作为最终损失值。
缺点:选择性搜索仍然较为耗时,对小目标的检测性能仍然较差。
更多细节可以参考:RCNN_哔哩哔哩_bilibili
目标检测 | R-CNN、Fast R-CNN与Faster R-CNN理论讲解-CSDN博客
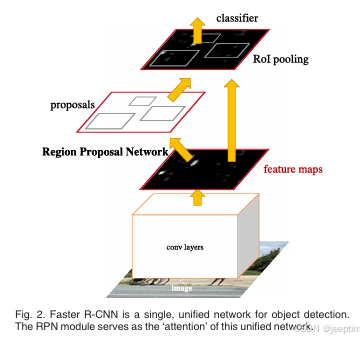
faster-RCNN及其拓展组件:
基本框架:CNN+RPN+ROI pooling+softmax+线性回归模型
改进:使用RPN替换SS(并不是指在原作用位置直接替换),其他结构与fast-RCNN无异。因为使用RPN输出边界框,无论是算法速度还是生成边界框的数量,都极大缩减了预测时间。
RPN:不同于SS作用于原图,RPN作用与特征图,因此RPN中一个滑块中对应的原图作用面积会是anchor面积的数倍,这个倍数取决于CNN的卷积以及池化层的分布情况。具体来说每个滑块中的anchor对应到原图上的尺度有三种(128^2,256^2,512^2)比例也有三种(1:1,1:2,2:1)。RPN会在特征图中历遍所有像素,但不是所有anchor都会被保留,对于VGG作为backbone的情况只保留256个anchor,只保留IOU大于0.7(或IOU最大)与IOU小于0.3的anchor。
损失计算:论文中采用分部式计算,也可以直接采用联合训练方法。分部式计算主要是将RPN的训练与fast-RCNN训练分开,先训练RPN参数,再用RPN生成边界框训练fast-RCNN,然后使用fast-RCNN的训练参数微调RPN参数以微调边界框,最后再微调fast-RCNN全连接层参数。
缺点 :该模型仍然使用高层特征进行物体分类和边界框回归,对小目标的检测仍然不利。
为解决以上缺点,可以使用组件FPN。
FPN:
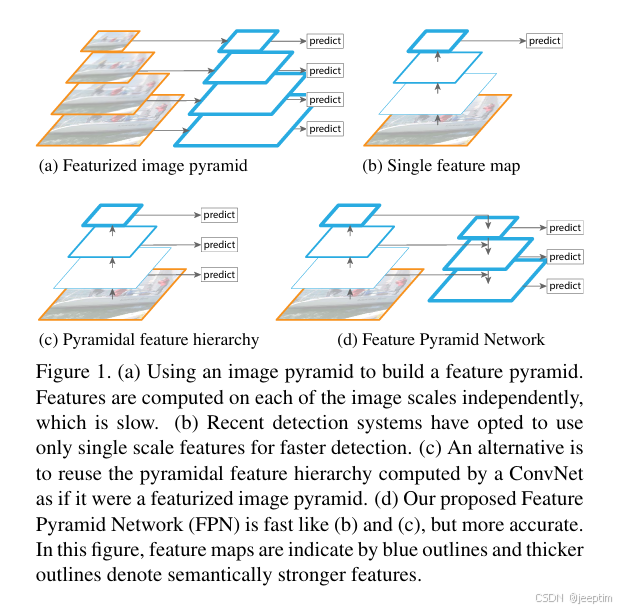
为帮助我们理解FPN的性能提升,上图中有四种特征提取方案:
(a) 使用图像金字塔构建特征金字塔,每个尺度单独计算特征。虽然可以获得不同尺度的特征,但是计算资源占用大,且推理时间长。
(b) 对图像进行卷积池化操作后只提取最后一层的高级语义特征,这就是RCNN系网络的做法。缺点前文已点明。相对于方案a,它的推理速度快且计算资源占用少。
(c) 是将a和b两种方法的长处结合,将图像卷积池化后的特征分别计算,得到不同尺度的特征。兼具速度与特征量。但是特征的鲁棒性不强,浅层特征较弱,割裂计算无法发挥这些浅层特征的作用。
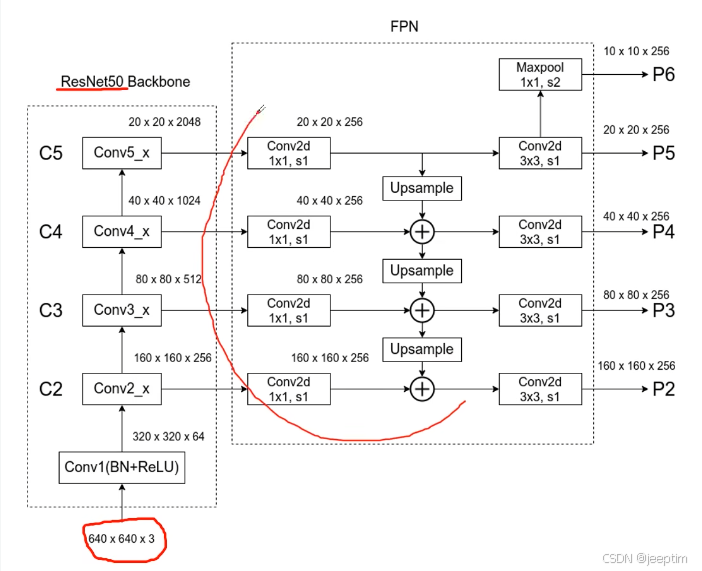
(e) FPN方法本尊,使用了更深的层来构造特征金字塔,这样做是为了使用更加鲁棒的信息;除此之外,我们将处理过的低层特征和处理过的高层特征进行累加,这样做的目的是因为低层特征可以提供更加准确的位置信息,而多次的降采样和上采样操作使得深层网络的定位信息存在误差,因此我们将其结合其起来使用,就构建了一个更深的特征金字塔,融合了多层特征信息,并在不同的特征进行输出。具体做法是先将除第一层外的各层用1*1*256卷积统一通道数,将统一通道数后的各层从最高层开始,最高层经上采样后维数与下一层一致,将最高层特征直接与下一层相加,以此类推,得到每层的输出特征,具体流程看下图。注意这里还使用了maxpool池化生成了p6特征,p2~p6会输入到rpn中,分别使用不同尺寸的anchor(32^2,64^2,128^2,256^2,512^2)进行训练。分别对应识别最小到最大的目标。

















 1788
1788

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









