






*说在前面*
一、网页版大模型的使用限制和本地构建的必要性
网页版的各种大模型在日常简单办公时已够用了,但依然存在不能完全满足我们工作场景的需要。
因为我们很多情况下需要上传相关附件,从而让大模型有针对性的进行反馈。但如果大家有使用过网页版的附件上传功能,就会知道网页版大模型对上传附件的大小、格式、数量和内容的限制(很多党政或内部文件上传后系统会因为内容敏感而直接不予处理),而且更为重要的是上传内部文件、保密文件和内部数据本身就是违规和存在高泄露风险的行为。
二、本地模型及知识库的使用场景
1、根据公司制度就相关问题进行回答;
2、根据公司财务数据、风险管理数据进行数据处理(目前数据数据在这套配置下效果不好,文字类的文件处理能力较强);
3、将监管文件进行收集后,交由大模型对某一操作的合规性和风险性进行判断。
要实现以上目的,需要我们上传足够多的背景材料。但在目前DeepSeek官网经常掉线、大量数据处理需要额外收费,以及内部信息不得外泄的合规要求下,如果能够实现本地化部署,就可以在享受大模型便利的同时,避免可能的风险和限制,并形成非常个人化的使用风格,成为个人的新竞争力。
当然,如果贵公司足够有实力布设了公司层级的本地化大模型系统,那就直接使用呗。
这篇文章纯粹是我摸索数日后的心血来潮之作,总结不断碰壁的经验,也希望能够给大家带来一些帮助。
三、本地部署的步骤
1、通过下载Ollama,下载适合的DeepSeek来进行大模型的本地化部署;
2、通过chatbox实现窗口对话功能
(这一步其实并非必须,因为在Ollama安装后可以通过命令行与大模型进行对话,也可以在完成第三步之后,也可以使用Ragflow窗口进行对话。但chatbox不只可以支持本地模型,还可以支持很多在线模型的API接口,也是很有用的。而且我下载Chatbox的真实原因是我当时在第三步卡了很久,准备用用残血蒸馏模型算了)
3、通过Docker和RagFlow,实现知识库的本地化部署
四、本地部署大模型所需资源
这里将后面所需的涉及的所有资源和相关链接都统一一股脑的给大家,方便大家提前下载、学习。
另外,可以去B站上学习相关UP主的视频,同时记得一定要看大家的评论,毕竟每一台电脑的配置和情况是不一样的,相互帮助可以少走很多弯路。
(1) Ollama
官网网址:https://ollama.com/
(2) Chatbox
官网网址:https://chatboxai.app/zh
(3)Docker
官网网址:https://app.docker.com/
(4)Ragflow
Github介绍主页:
https://github.com/infiniflow/ragflow/blob/main/README_zh.md(这一步对我而言有点难的,是我卡的最久的地方,建议先看一遍,不用弄懂至少有个印象)
(5)DeepSeek等网页版大模型:
DeepSeek本尊或纳米AI或KIMI或豆包等,这些都很好用。在后面的操作中,如果遇到自己实在走不通的时候就直接向他们求助吧。大模型可能会给你好几种备选的解决办法,不一定都有用,但绝对是能够起到提点思路的作用。
提示词基本格式:【我在干什么的时候】+【干了什么】+系统反馈【原文粘帖系统反馈了什么信息(记得用引号括起来)】+【请大模型给与什么帮助】
举例:
1、我在ragflow模型配置过程中,出现了以下错误信息,请告知原因和解决方法“提示:102 Fail to access model(deepseek-r1:8b).ERROR:[Errno 111] Connection refused”
2、我在再次尝试之后出现提示了以下错误:“D:\RagFlow\ragflow-main\docker>docker compose -f docker-compose.yml up -d time=“2025-02-20T14:45:42+08:00” level=warning msg=“The “HF_ENDPOINT” variable is not set. Defaulting to a blank string.” time=“2025-02-20T14:45:42+08:00” level=warning msg=“The “MACOS” variable is not set. Defaulting to a blank string.” Error response from daemon: Head “https://registry-1.docker.io/v2/valkey/valkey/manifests/8”: unauthorized: incorrect username or password”,请进一步进行指导。
(6)B站相关Up主视频
这些视频我都反复看了好几遍,当然还看过其他很多视频,但这几个视频对我帮助是最大的(特别第一个)。
l【【知识科普】【纯本地化搭建】【不本地也行】DeepSeek + RAGFlow 构建个人知识库】(up主:*堂吉诃德拉曼查的英豪*)
l【一图看懂DeepSeek R1满血版、蒸馏版、阉割版的区别!本地部署需要什么硬件配置?】(up主:*一小时技术精讲*)
l【什么是API?DeepSeek技巧升级2.0~】(up主:*秋芝2046*)
在这个自我学习的过程中,我再次感受到了互联网的开放和共享,这个小小的心得其实是全网络分享者们共同智慧的结晶。
*实操上手*
一、软件的安装
(一)Ollama
1、下载并安装ollama
ollama是本地部署大模型的基本工具,本地部署基本绕不开,可以在上面本地化使用 GPT4、DeepSeek等模型。
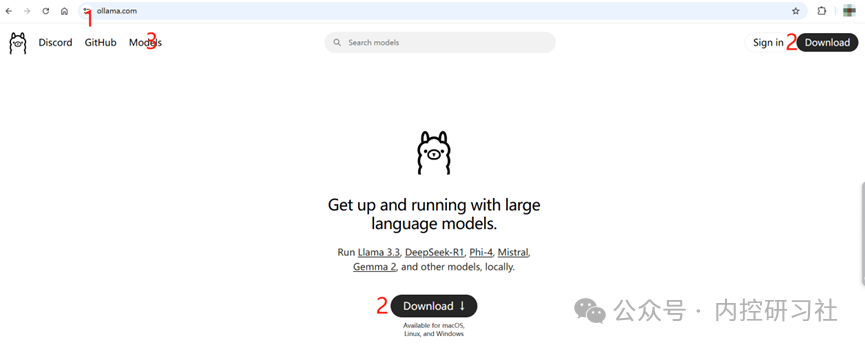
只要登录Ollama的官网,(图片中1是官网地址),点击2根据自己系统下载相关版本的Ollama软件,打开后一路下一步就安装好了。3要记住,等下要去里面找合适的版本代码。
2、配置环境变量
这步很重要,可能对很多朋友而言,这步就超过了日常对电脑使用的程度,需要对电脑进行一定的配置,也是为了能够让后面用到的软件能够相互交互。
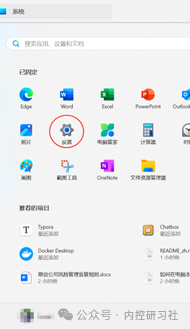
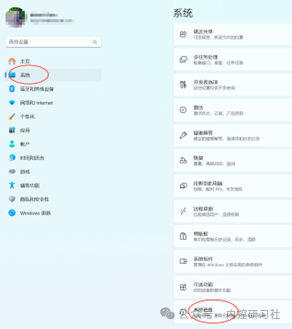
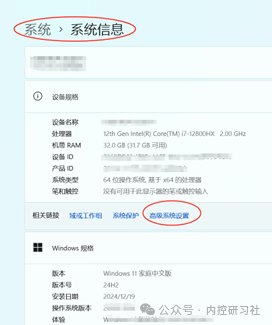
具体操作,打开开始-电脑设置-系统-系统信息,点击【高级系统设置】,选择【高级】选项卡,点击【环境变量】。
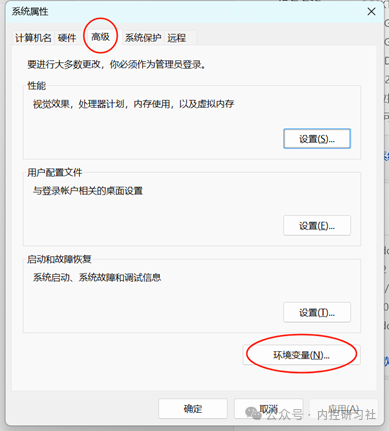
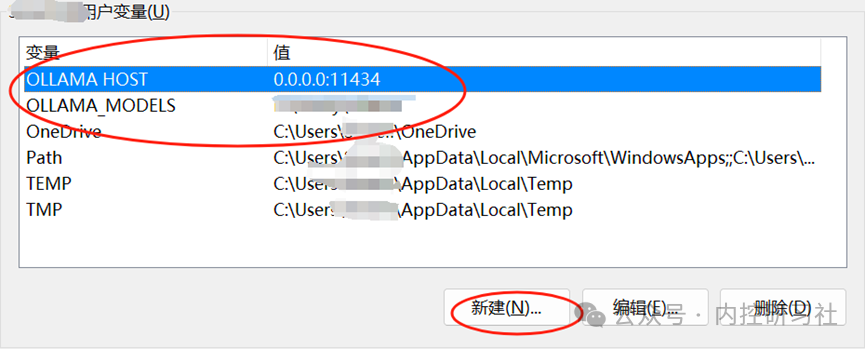
这里新建两个环境变量,我是已完成了设置,这里新建的两个变量的内容见下表:
| 变量名 | 变量值 | 用途 | |
|---|---|---|---|
| 变量1 | OLLAMA_HOST | 0.0.0.0:11434 | *软件间通讯穿透所用* |
| 变量2 | OLLAMA_MODELS | 找个你喜欢的硬盘地址,比如” E:\ ollama” | 默认模型下载地址,不设定就下载到C盘了,C盘不够大就满了 |
(二)确定并下载大模型
这一步还是用的Ollama,不过在此之前,要先根据自己的电脑配置和需要来确定要下载什么大模型。
1、确定准备本地部署的大模型及版本号
以DeepSeek为例,满血版本的大模型肯定好啊,不过自己的电脑也肯定跑不动。我在B站找了几张图,大家自己看一下,根据自己的配置和目标,选择什么版本模型。
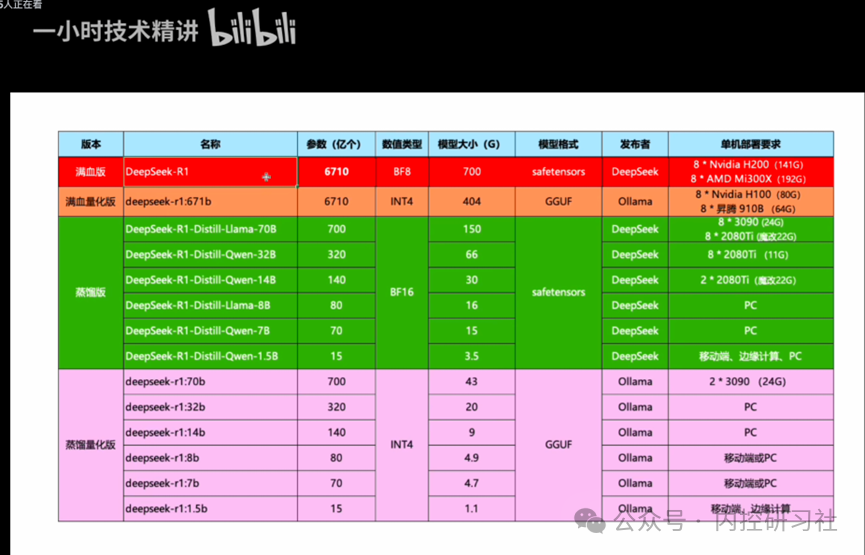

我目前使用是打黑神话的游戏本作为主机,选择了8B的版本。目前使用下来完全不卡,但显卡的算力似乎没有用到,可能是配置上还有问题,感觉14B的版本应该也能运行起来。
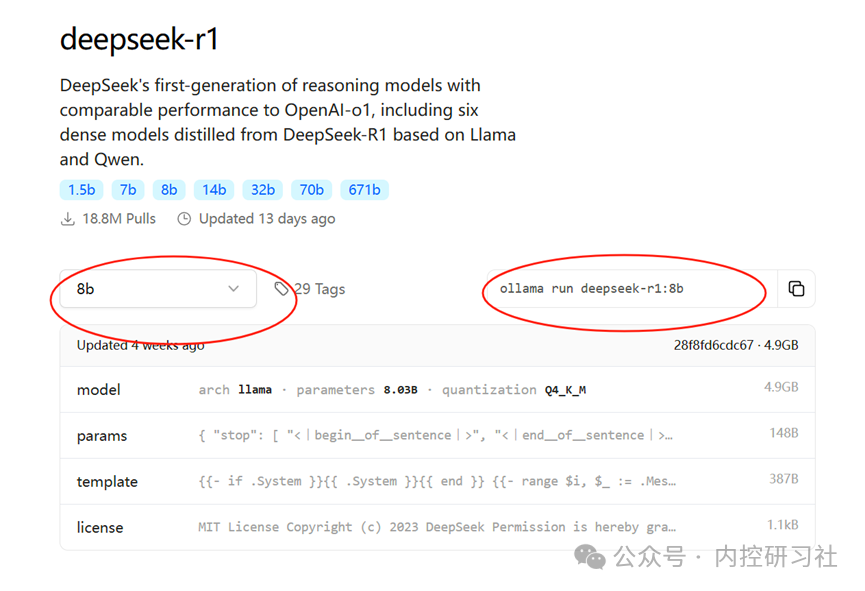
当确定准备上的模型版本之后,回到Ollama的官网,点击models(也就是第一张图中的3),进入下一页,找到DeepSeek,点击进入,选择你要的版本,从而确定Ollama内部的版本号(如8b版本对应的版本号就是ollama run deepseek-r1:8b)。
版本号记得复制一下,后续会用到。
(2)通过Ollama安装大模型
这里就需要用到Windows的命令行了。快捷键:win+r,打开命令窗口,输入CMD回车,进入命令行窗口。
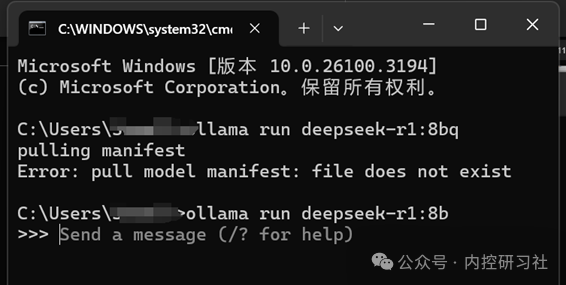
在光标之后输入刚刚复制的“ollama run deepseek-r1:8b”,就开始自动安装了。
这里可以看到,第一次我命令输错时,系统是不会运行的。
当我们正确安装之后,再输入同样的命令,这个时候系统会让我们询问问题,这就说明大模型已本地安装完毕了。
大家可以在这步体验一下蒸馏版本与满血版本的差异。我用下来,8B版本满足了我对本地模型的期望(但远远不能和满血版相比),但1.5B 版本的表现就和脑残差不多了,完全不建议使用。
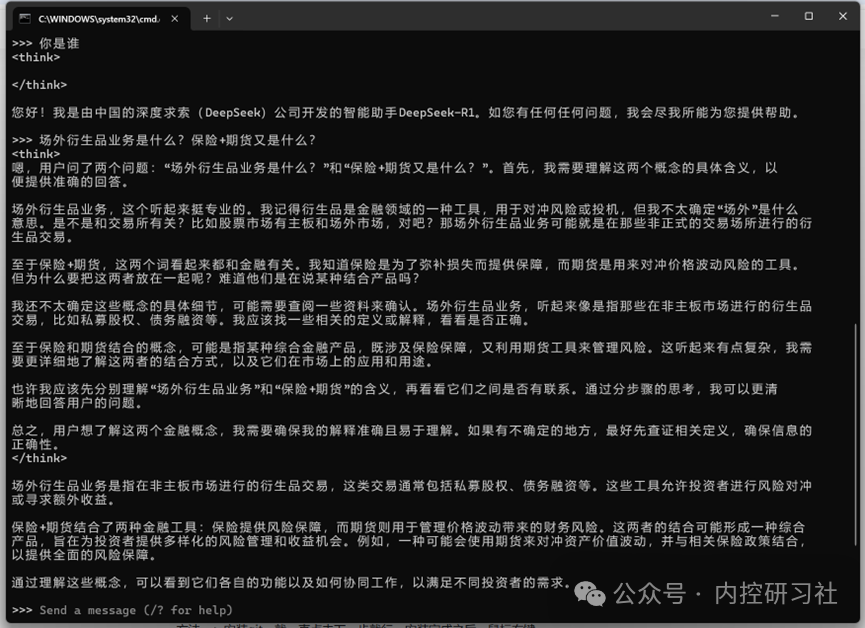
从上面的演示来看,这个回答肯定不是我们所期望的。考虑到是蒸馏且未联网的情况下,还算可以接受。
不过这个界面还是太丑,大家还是更喜欢如微信这样的聊头界面,这就需要使用Chatbox等软件接入模型,从而方便聊天。
(二)Chatbox
1、下载并安装Chatbox
到https://chatboxai.app/zh上下载Chatbox最新版本,打开后一路下一步进行安装
- Chatbox的配置
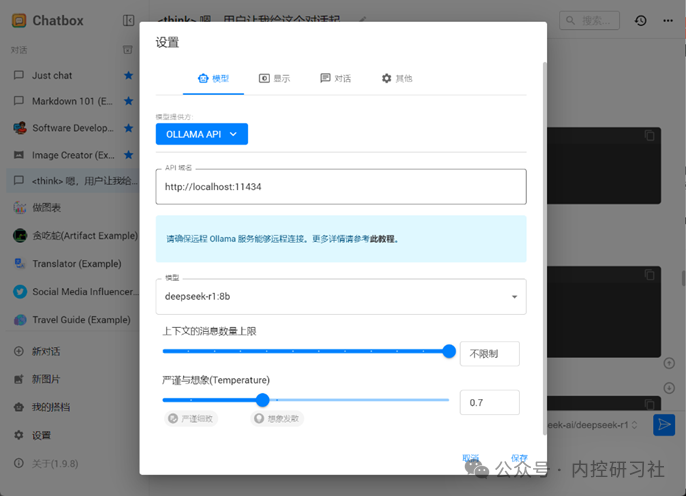
打开ChatBox进入首页,第一次进入会提示选择并配置AI模型提供方。选择“使用自己的API Key或本地模型”。
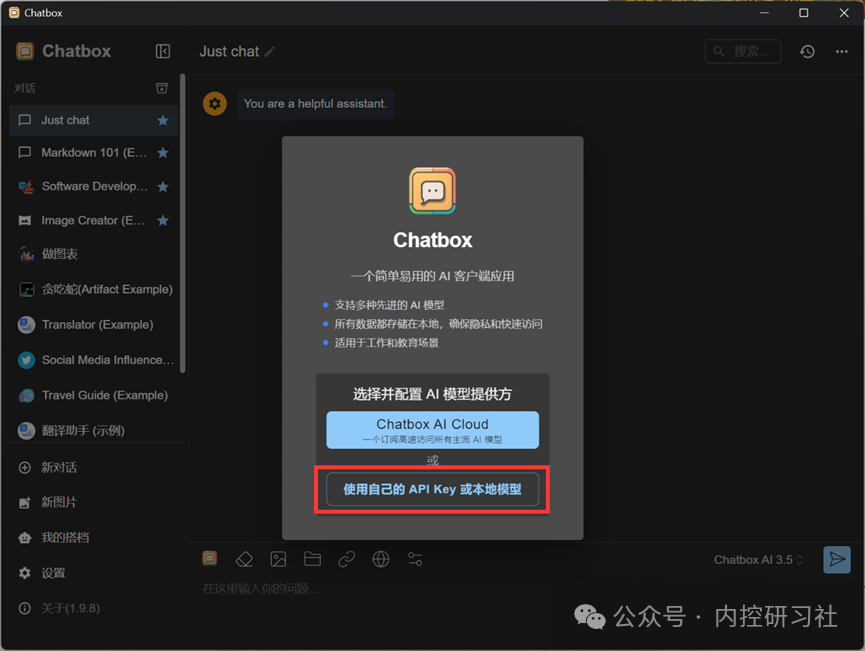
紧接着选择添加自定义提供方-模型选择Ollama,并按照以下表格进行配置后保存。Ollama里面可能有自带的模型,所以一定准确选择你下载的且想要运行的模型。
然后我们就可以Just chat开始在本地方便的与模型进行对话了,不必再使用丑丑的命令行了。
现在看着有点成功的喜悦了吧?但这个回答肯定不是我们想要的精准结果,所以让我们继续。
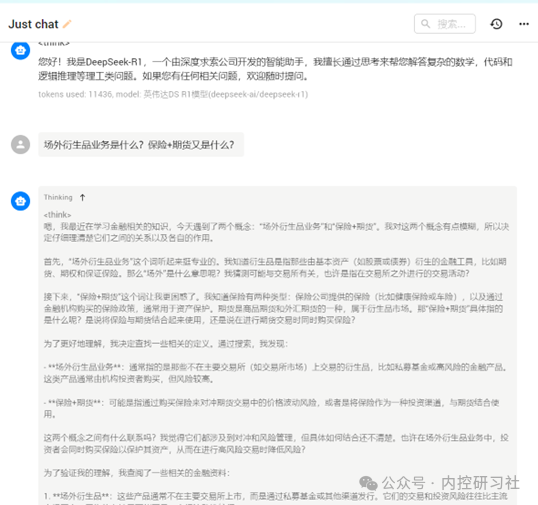
(三)****Ragflow和****Docker
这一步其内核逻辑说实话没有搞明白,也是折腾我最久的环节,因为两个软件的安装的过程和常规软件的安装有很大的差别。根据网上看来的资料,Ragflow是后面调用的核心,而Docker是为Ragflow运行提供所需的各种环境。
大家按照我的操作来进行,碰到问题就问下联网满血版的大模型,寻求帮助。
1、下载Ragflow所需的全部配置文件
到网址https://github.com/infiniflow/ragflow,点击绿色的Code按钮,然后用ZIP格式下载全部所需的文件。
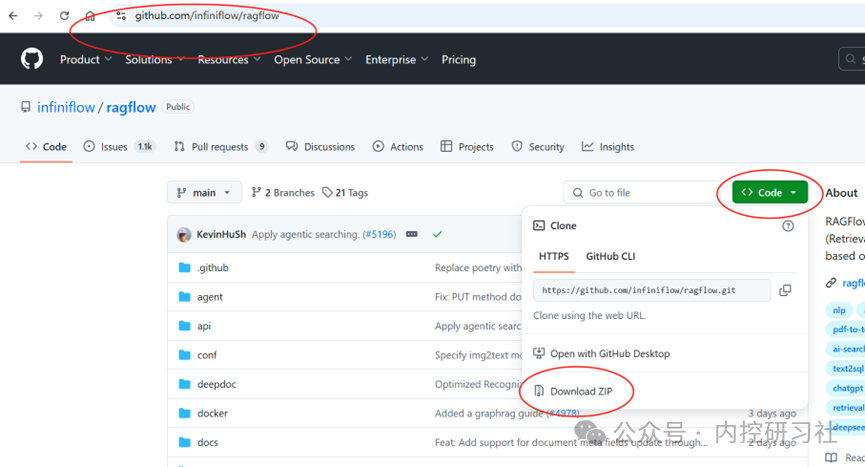
将这个压缩包全部解压之后,进入文件夹,进入子文件夹docker,找到文件“.env”,用记事本打开,找到大约84行左右,进行配置的调整。
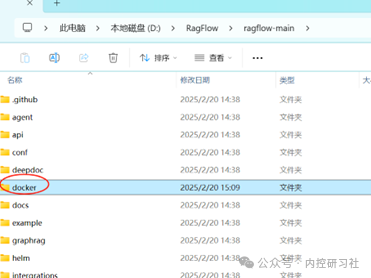
这里的调整主要有两个:
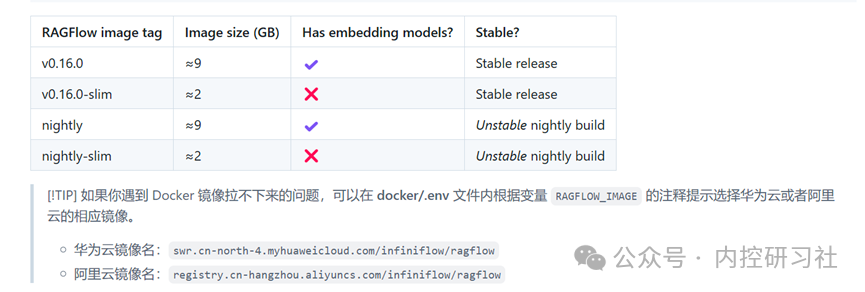
(1)将原来84行的“RAGFLOW_IMAGE=infiniflow/ragflow:v0.16.0-slim”之前加一个#,让系统运行的时候不会去下载Slim版本,因为Slim版本缺少一些功能,不能使我们本地对文件进行解读;
然后将87行最前面的#删除,让系统运行时自动下载完整版本。
(2)调整一下87行对应的下载地址,因为网络的问题,原有的地址很可能报错,用科学上网都不一定能够解决,因此我们去网上找一下对应国内进行的地址,进行替换。
国内镜像怎么找呢,还记得一开始让大家看的Github的栏目么,那个里面就有。

将“.env”文件调整之后,记得保存之后关闭。
2、下载Docker并完成注册
这步有点复杂,我基本将网上涉及到的每一个步骤都走一遍,然后问了网页大模型好多回,终于尝试通了,但过程中遇到的问题究竟是什么,我并不很清楚。只能说通过不断试错最终成功了。
*(1)安装Docker*
访问 Docker 官网,选择适用于 Windows 的版本进行下载。
打开软件,使用命令行(Win+r,CMD回车),输入“docker version”,检查 Docker 的版本信息。如果有消息回复,没有显示错误,说明docker正确安装。
****(2)****打开docker软件,记得一定要登录好,记下自己的用户名和密码,因为这个可能在后续会用到。
成功登录后进入到刚才下载完成的ragflow-main文件夹下,在上面这个路径输入cmd,就是点击地址栏,然后直接cmd回车。等于在这个路径下运行命令行。
运行命令:
docker compose -f docker/docker-compose.yml up -d
等待镜像包下载完成
下载完成之后,再输入命令:
docker logs -f ragflow-server
在这个过程中,可能会遭遇到很多的问题,我这里将我遇到的问题罗列一下:
A)之前的“.env”文件没有配置好,原始地址联不通,镜像地址没填入,无法下载;
B)网络不通(前面的步骤用到了科学上网,但不同软件的联通路径并不一致,需要多次调试)
C)Docker软件的登录装填与命令行的情况不一致。这种情形下,可能需要再命令行里面使用“docker login”进行一次登录,这里用户名会显示,但密码即便输入了也不会显示出来。
D)电脑的虚拟化没有做好
总之这个环节,遇到的问题都可以问Deep seek满血版,大模型的回答比很多UP主都清晰。
*(3)使用ragflow创建知识库*
A)打开电脑自带的浏览器,访问http://localhost:80/,进行注册并登录,方便我们使用,将界面设置成中文。
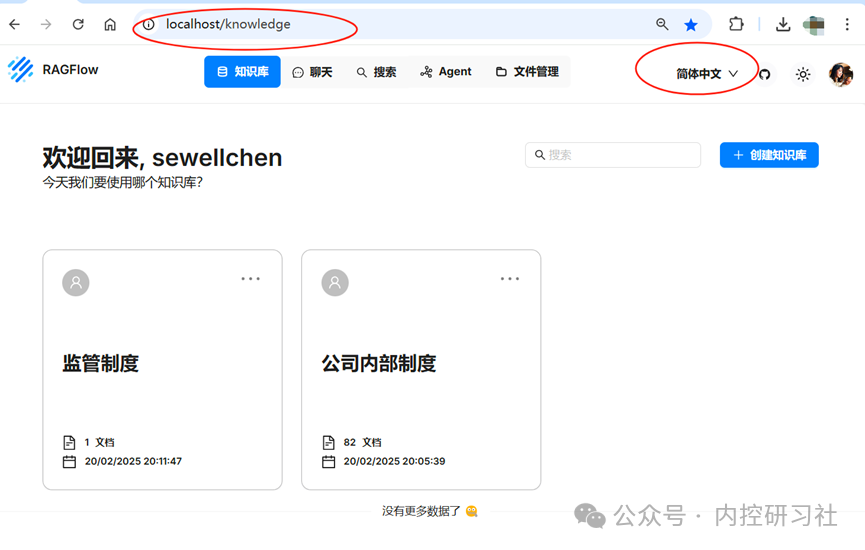
点击右上角的头像,点击【模型提供商】-找到ollama,点击【添加模型】
模型类型选择chat,win+r,输入cmd,输入命令ollama list,查看自己安装模型名称,复制然后输入到模型名称
基础url,输入http://自己的ip地址:11434(或者http://host.docker.internal:11434),最后点击【确定】按钮。
B)点击【系统模型设置】
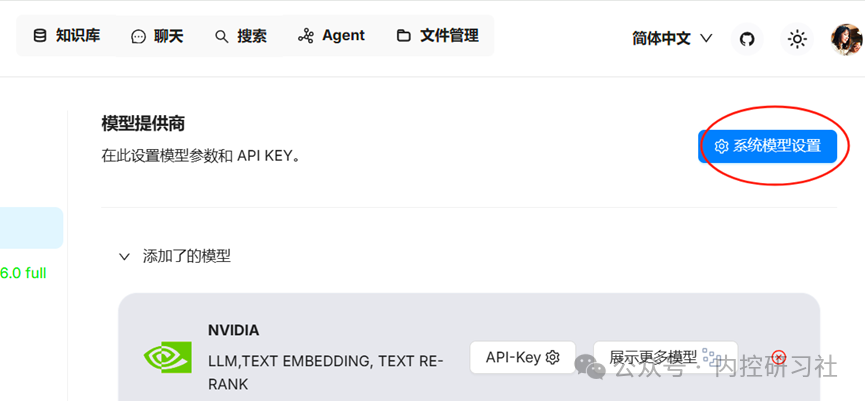
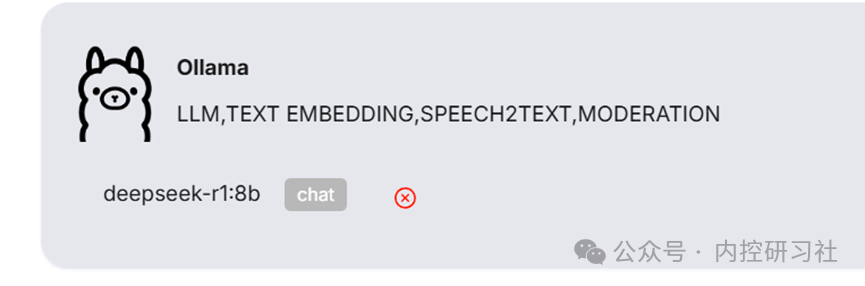
选择刚才添加的模型,其他保持默然,然后点击确定
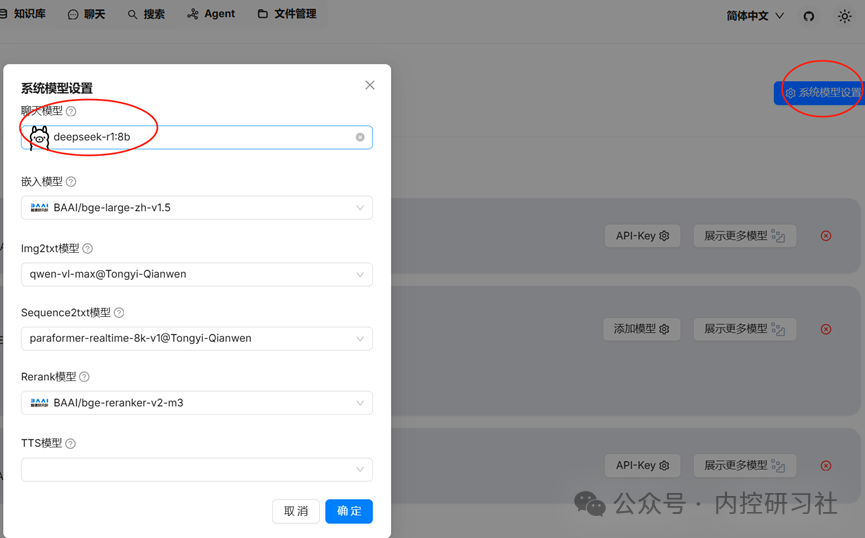
如果聊天模型没有选择我们的本地模型,如果是其他在线模型,那数据还是会有泄露的情况。
C)回到知识库界面,点击【创建知识库】,
输入知识库名称,例如:监管制度
然后配置知识库,把语言改成中文
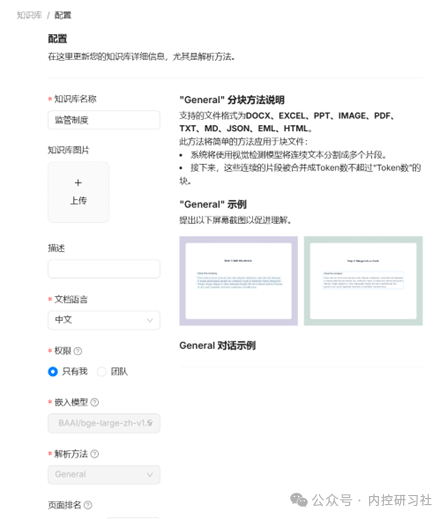
选择好相应的嵌入模型和解析方法。
点击【数据集】,再点击【新增文件】,上传文件,然后记得一定要点击解析的小绿标,解析速度看文件大小和电脑配置,我的电脑似乎只用了CPU,没有用到GPU。
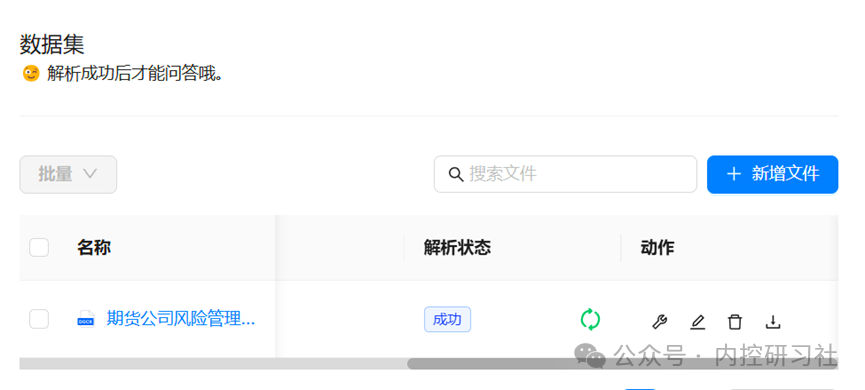
解析状态“成功”之后,等于这个知识就可以被模型使用到了。
解析完成之后,点击上面的【聊天】按钮,新建助理
填入相关信息、选择好相应的知识库,点击确定。
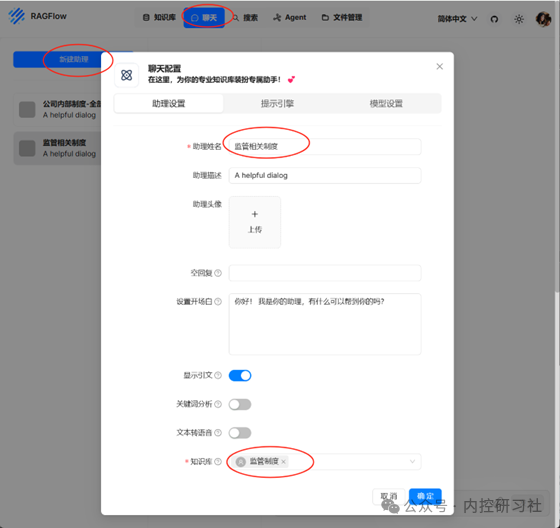
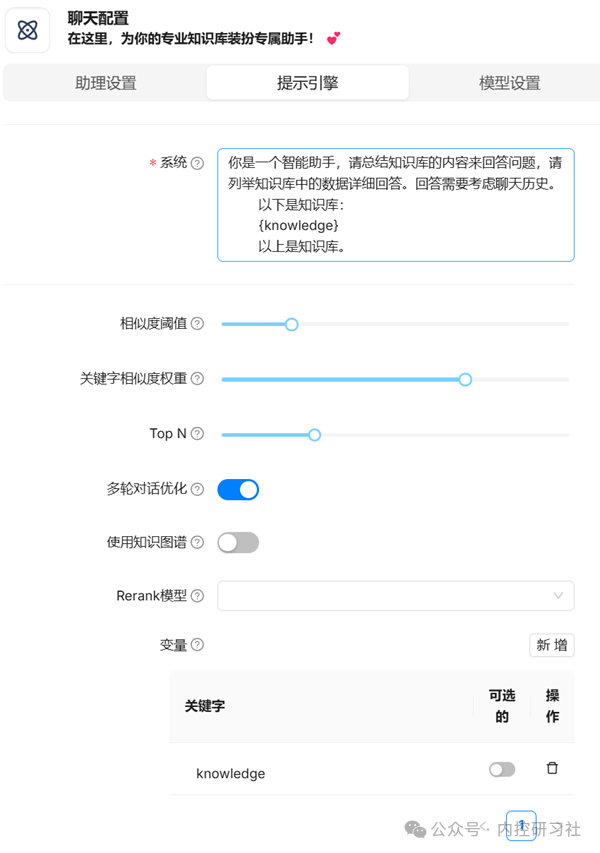
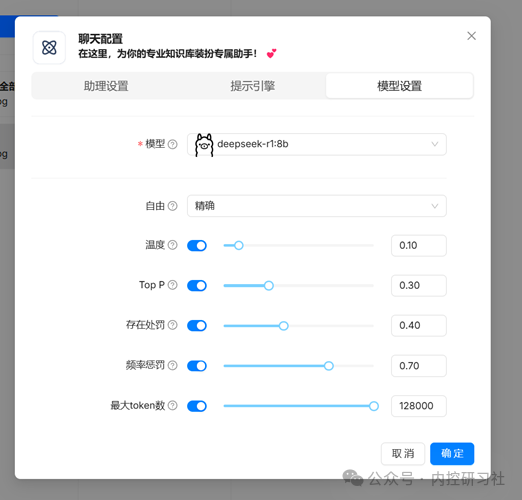
输入你想问的问题,这样一个知识库就完成了
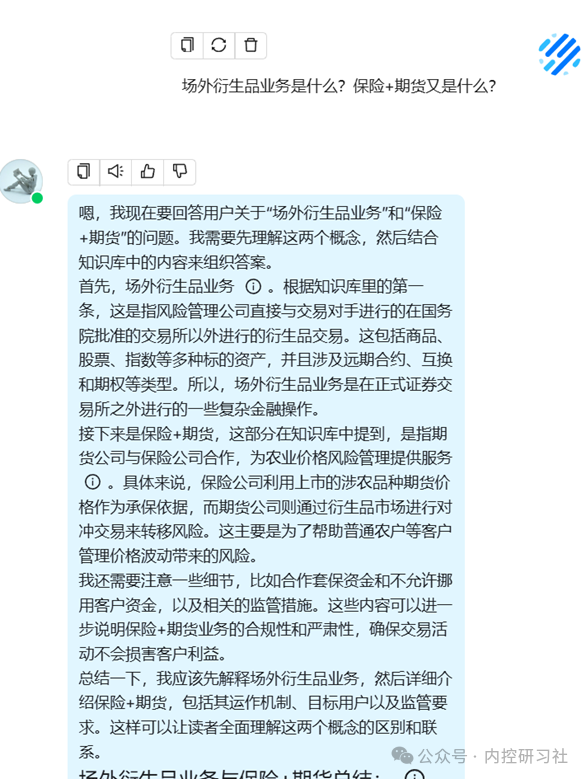
对比一下之前的那个回答,这个回答是不是就高级且有针对性很多了?
知识就可以被模型使用到了。
解析完成之后,点击上面的【聊天】按钮,新建助理
填入相关信息、选择好相应的知识库,点击确定。
[外链图片转存中…(img-qUy9Te26-1746154177121)]
[外链图片转存中…(img-Ab5nuARA-1746154177121)]
[外链图片转存中…(img-IJKawp0u-1746154177121)]
输入你想问的问题,这样一个知识库就完成了
对比一下之前的那个回答,这个回答是不是就高级且有针对性很多了?
[外链图片转存中…(img-06Vbk0Su-1746154177121)]
在AI高速发展的今天,如何拥抱AI、如何应用AI,不仅是我,相信也是各位读者非常感兴趣的话题。作为合规工作者,我们可以通过DeepSeek+RAGFlow的本地化部署,实现智能应答的高效性,更能确保数据的安全性与合规性。让技术与合规同行,助力企业在合规的道路上走得更稳、更远。
如何学习AI大模型?
大模型的发展是当前人工智能时代科技进步的必然趋势,我们只有主动拥抱这种变化,紧跟数字化、智能化潮流,才能确保我们在激烈的竞争中立于不败之地。
那么,我们应该如何学习AI大模型?
对于零基础或者是自学者来说,学习AI大模型确实可能会感到无从下手,这时候一份完整的、系统的大模型学习路线图显得尤为重要。
它可以极大地帮助你规划学习过程、明确学习目标和步骤,从而更高效地掌握所需的知识和技能。
这里就给大家免费分享一份 2025最新版全套大模型学习路线图,路线图包括了四个等级,带大家快速高效的从基础到高级!




如果大家想领取完整的学习路线及大模型学习资料包,可以扫下方二维码获取

👉2.大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。(篇幅有限,仅展示部分)

大模型教程
👉3.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(篇幅有限,仅展示部分,公众号内领取)

电子书
👉4.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(篇幅有限,仅展示部分,公众号内领取)

大模型面试
**因篇幅有限,仅展示部分资料,需要的扫描下方二维码领取 **


















 1920
1920

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











