






读者福利:关注公众号【大模型应用开发LLM】可获取入门大模型学习资料包一份~
fastgpt的知识库,是我认为目前最简单好用的知识库了,我一直用了很久。不过评论区多次提到另外一位热门选手:ragflow


ragflow其实我去年也用过,但是并没有深入一直去使用,因为当时我用着老是有各种各样的问题,比如上传的文件老是解析失败,用着用着突然访问不了了,问答拆分等解析模式非常慢等等。最关键的是当时因为搞各种本地大模型,本地部署,资源不够用了,,,而ragflow又非常吃资源

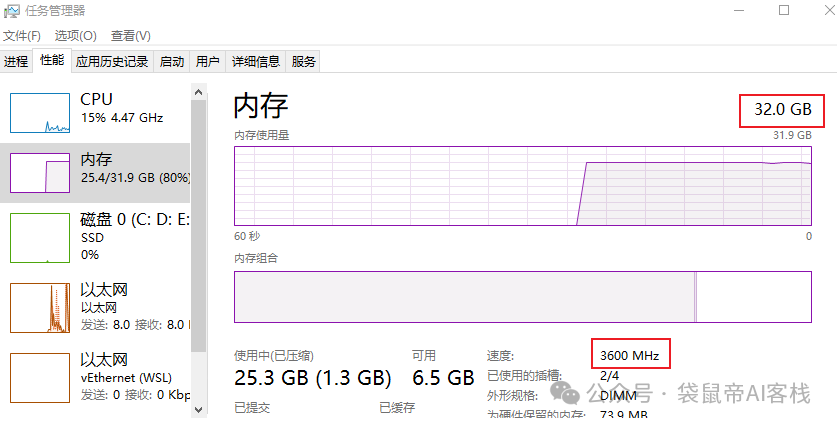
内存需求是fastgpt和dify的4倍;CPU是fastgpt和dify的2倍;而我的本地电脑内存就只有16G,属于是刚好能用。这两天为了在开各种软件的同时还能流畅运行ragflow,我斥巨资给电脑加装了两条16G内存条(共32G)
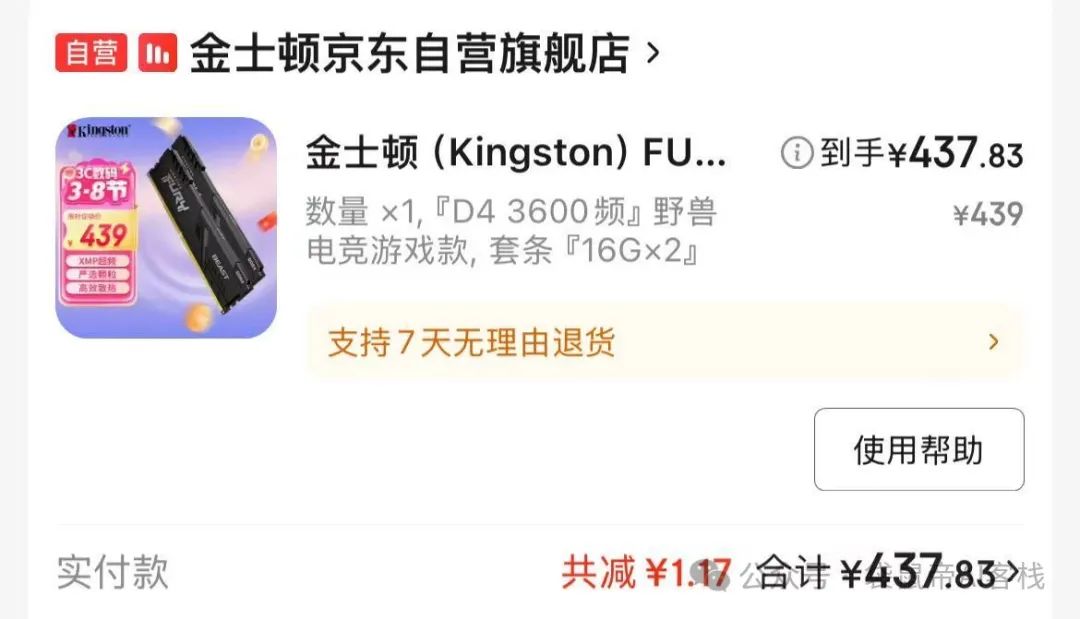
加装之后果然流畅多了~
这期给大家分享一下这几天ragflow的使用感受,和适用场景。
内容主要有:
1.简单介绍本地部署流程;
2.知识库搭建,参数配置讲解;
3.ragflow的团队管理、权限控制;

一、ragflow本地部署

ragflow在github上面也是一个明星项目了,有高达42.8k的Star,得到大家的高度认可。


**Github地址:**https://github.com/infiniflow/ragflow.git


在这里直接下载源码包
无法访问GitHub的朋友,可以公众号后台私信:“ragflow” 获取最新源码包。
源码包解压之后,到如下路径 ragflow/docker
路径上输入cmd,回车,进入控制台,输入如下指令一键启动。
docker compose -f docker-compose.yml up -d
ragflow的镜像比较大,最大的有10G。最好开着魔法,会比较快,实在没有魔法的朋友可以参考这篇,配置国内镜像加速地址。
内有镜像加速地址配置方法
袋鼠帝,公众号:袋鼠帝AI客栈DeepSeek+dify v1.0.0,本地构建企业级AI应用平台,真的太香了~
部署完毕之后,查看容器状态,如果都是running状态,就代表启动成功。
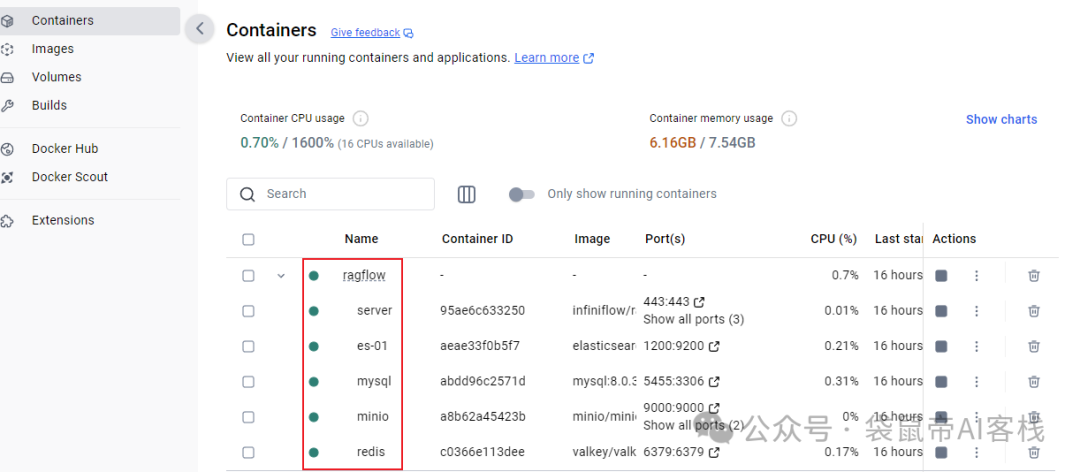
访问本机 http://127.0.0.1,即可进入ragflow的操作界面。

二、ragflow知识库搭建

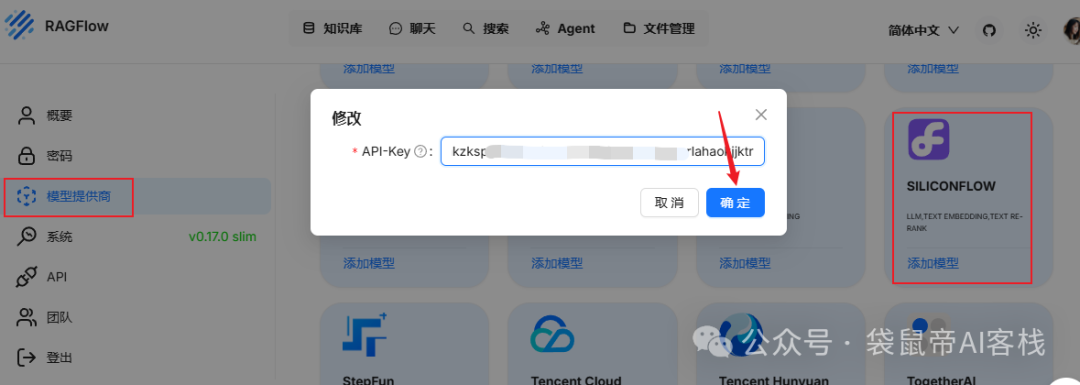
点击右上角头像->模型提供商
为了方便,咱还是配置使用硅基流动(因为里面有免费模型,模型全面,包含了知识库所需的索引模型、聊天模型、重排模型等等),还有DeepSeek V3 和 DeepSeek R1满血版,性价比高,最适合用来调式了。
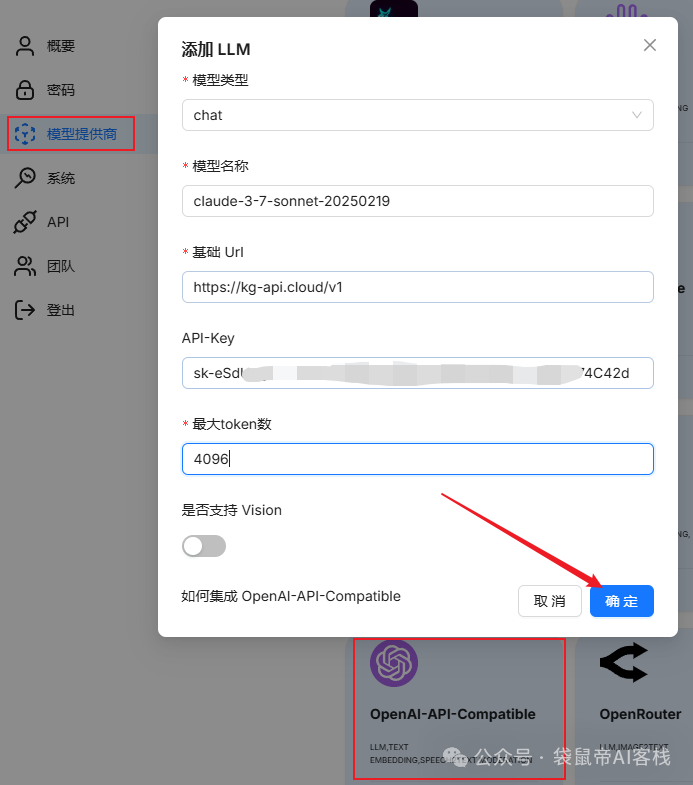
当然如果想要使用中转站,也可以选择OpenAI-API-Compatible进行配置
PS:推荐一个中转站 https://kg-api.cloud/
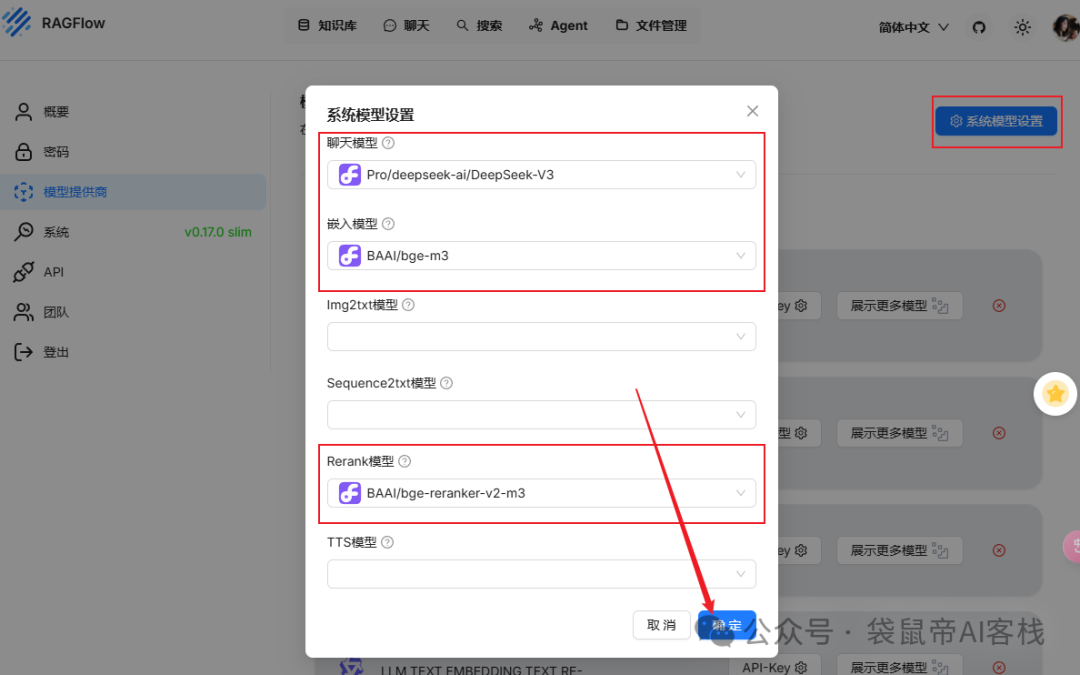
右上角系统模型设置这里,就可以配置聊天、嵌入、重排模型
在知识库->创建知识库,进入如下页面,进行知识库参数配置
PS:知识库有两套参数,一套是文件解析,进入知识库所需的参数配置,另一套是用户提问,进行知识库检索的参数配置
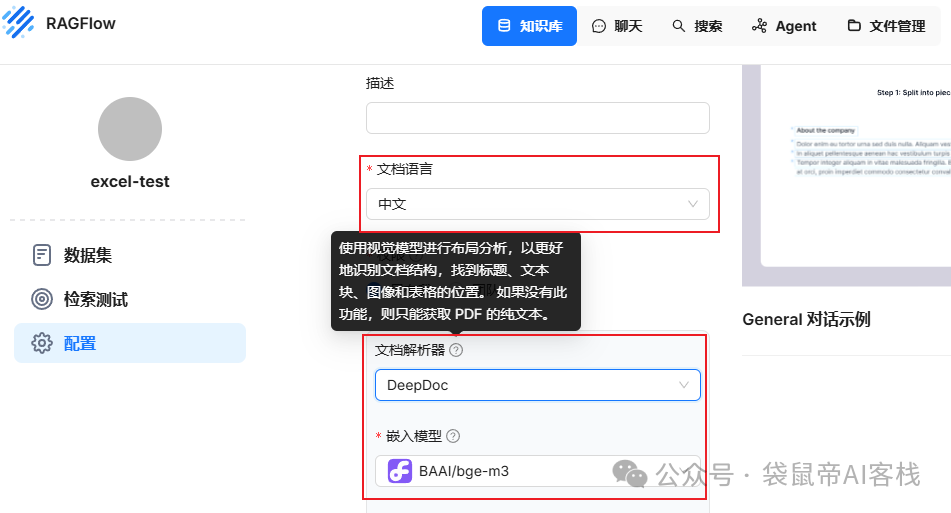
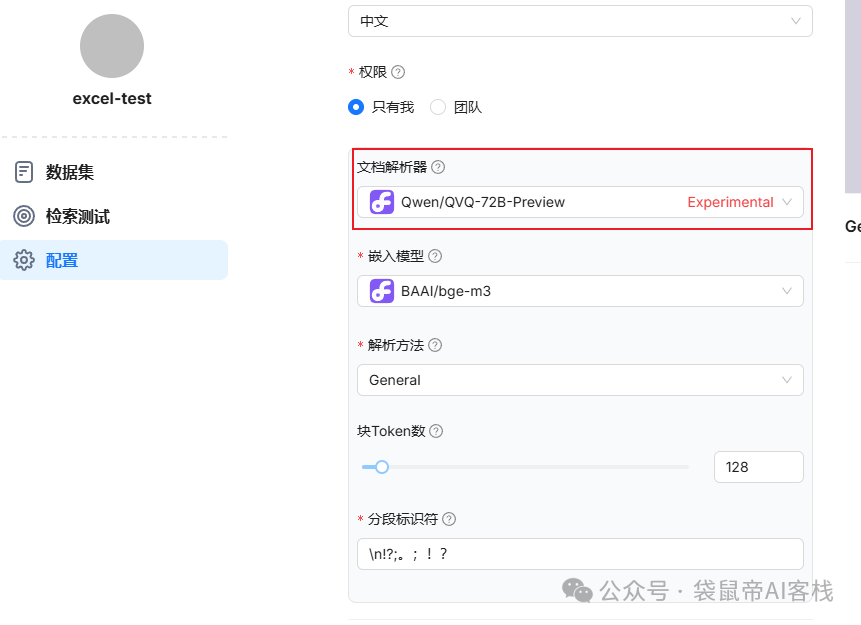
上图就是进行文件入库所需的配置,文档语言选择中文,文档解析器,可选自带的DeepDoc,还可以选择一些带有视觉功能的大模型(推荐配置都豆包的pro模型,豆包的视觉识别效果亲测很不错)
嵌入模型选择硅基流动的BAAI/bge-m3即可。之前文章的知识库搭建案例里面都是用的txt文件,后续有好些朋友问我多字段的Excel表格文件怎么处理呢。
所以,今天我们就讲另外两个常见案例,用Excel文件、和pdf文件搭建知识库。
pdf知识库
不过我们先看pdf文件,这里我在小米官网下载了一份小米 su7 ultra的参数配置pdf
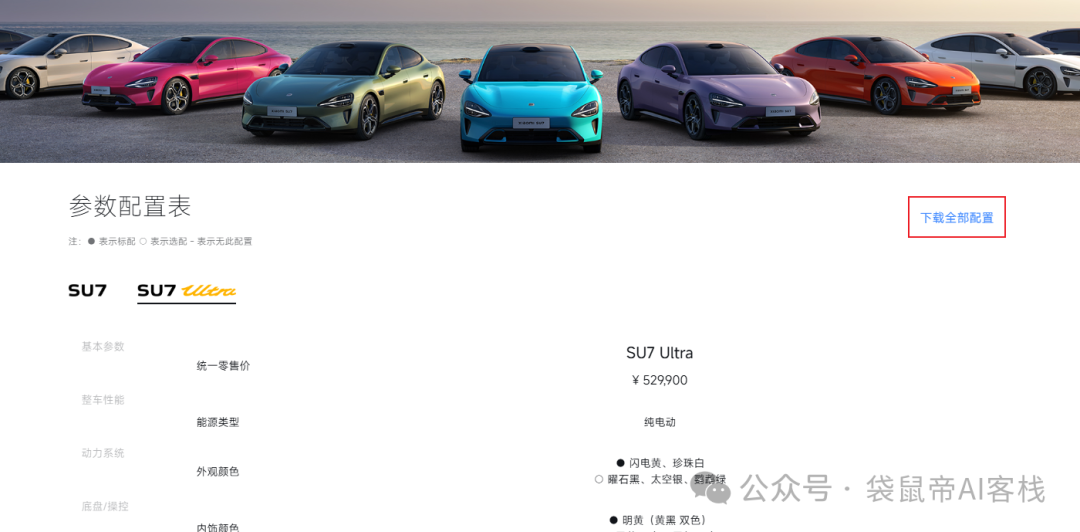
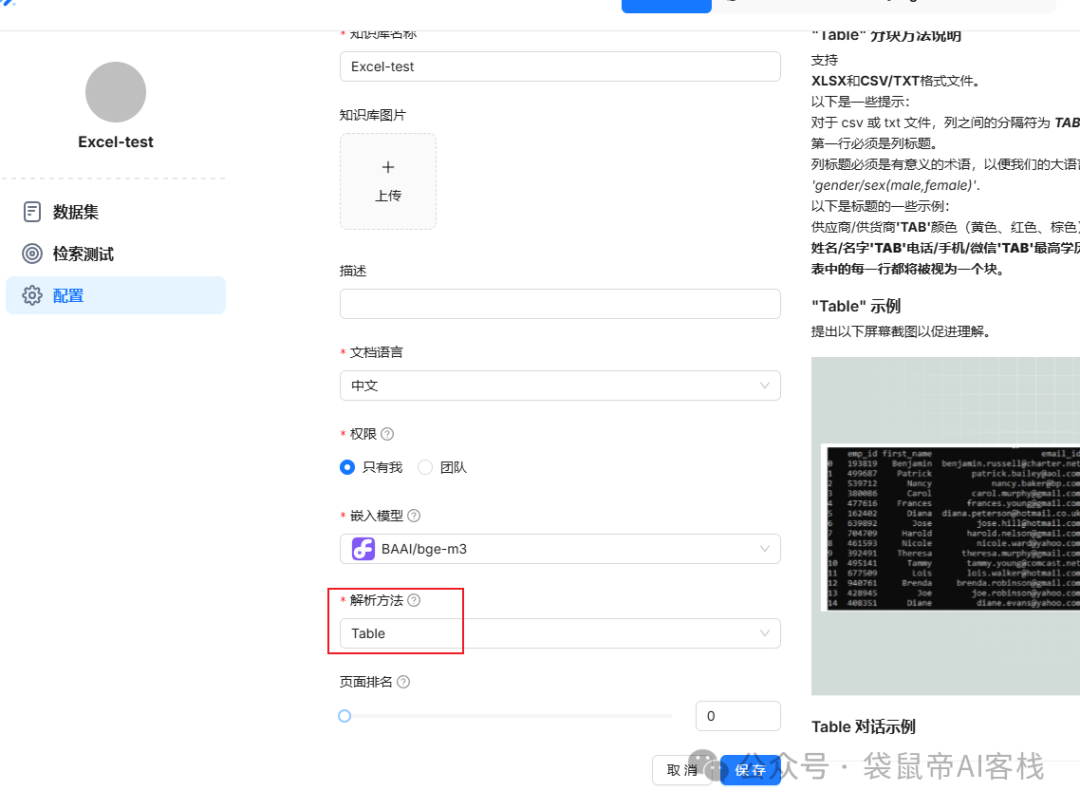
ragflow的解析方法有11种,每种选中之后,在右边都会展示其适用的文件、数据类型,根据需求进行灵活选择最适配的解析方法。
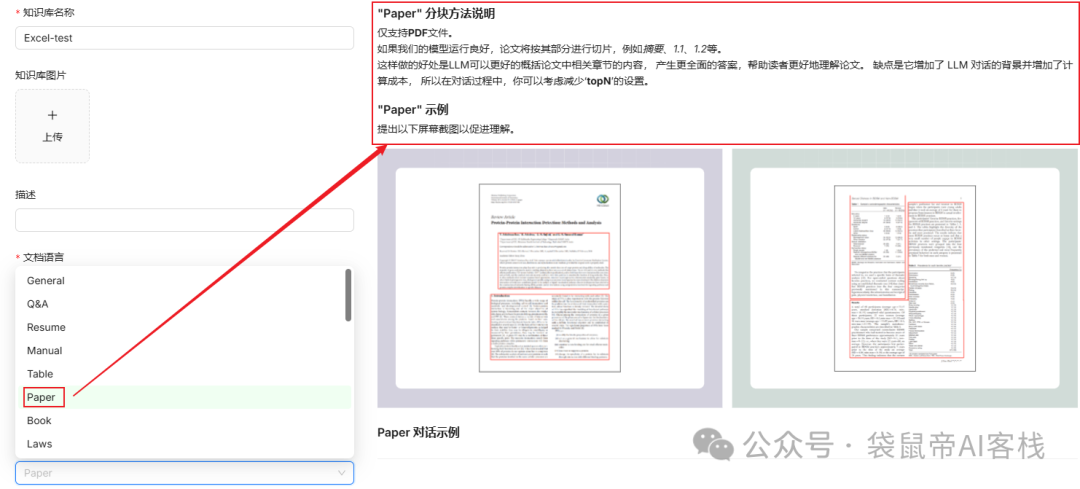
模型方面,我图方便就都选择硅基流动的模型了,解析方法采用了简单的分块方法。因为su7 ultra的参数配置pdf里面主要就是一些车辆参数,简单分块即可,不存在上下文丢失等问题
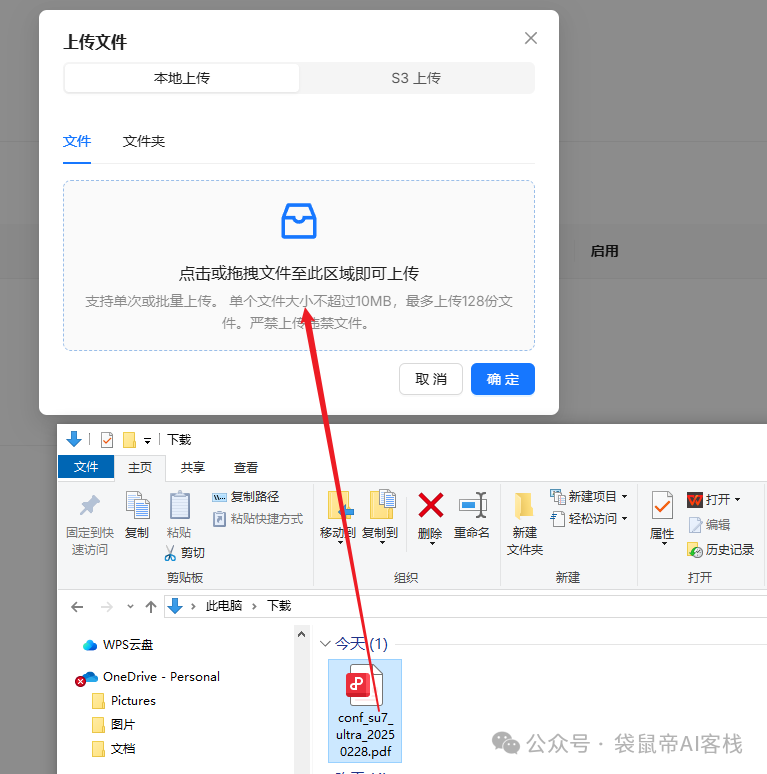
数据集->上传文件,直接上传
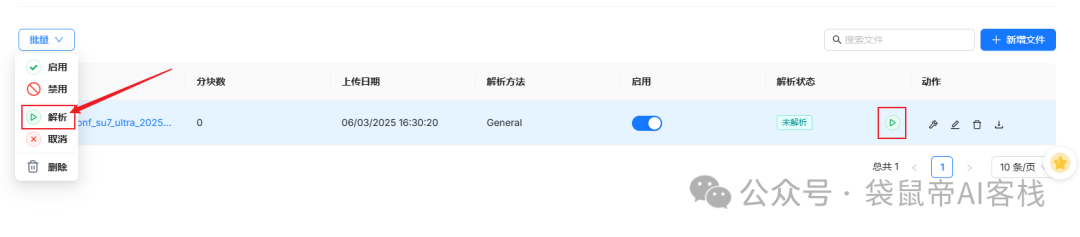
上传成功之后ragflow不是自动解析的,需要手动解析可以全选之后批量解析,或者选择单个文件进行解析
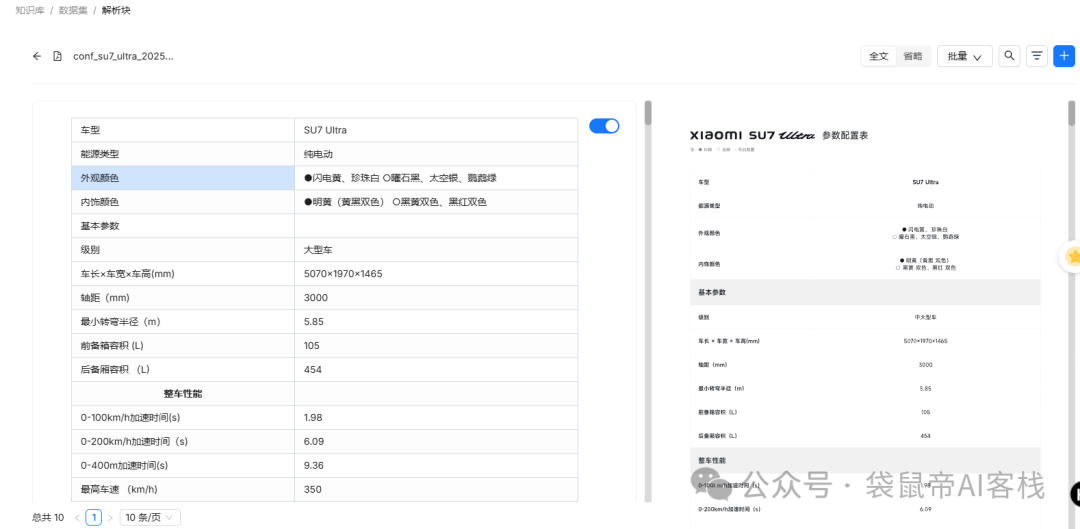
3分钟内解析完毕,查看详情,分了10个块,看效果感觉解析的还不错。
在聊天->新建助理->可以创建一个bot来关联su7 ultra参数知识库
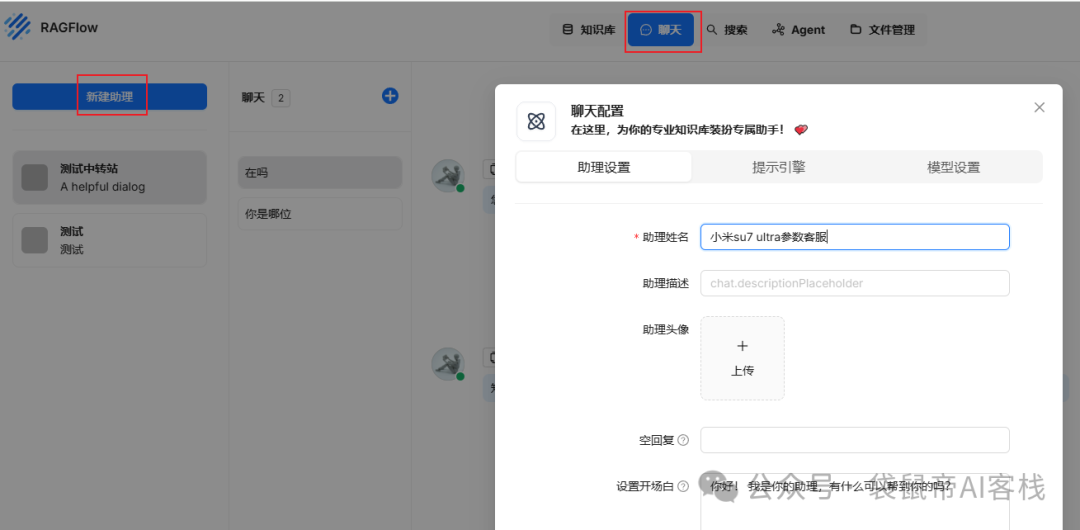
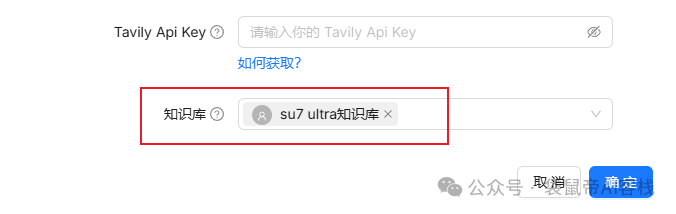
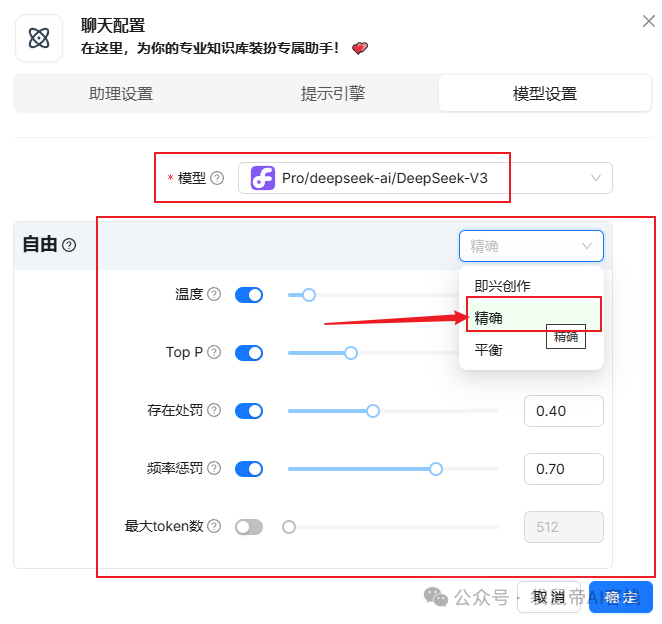
模型设置这边可以指定模型,以及模型的参数,由于是需要检索回答su7 ultra的车辆参数,是个很严谨的场景,所以模型设置**“精确”**。
在下图,可以自定义系统提示词,不过ragflow会给个默认的。
**相似度阈值:**只有相似度分数高于这个阈值的文本块才会被保留;
关键字相似度权重:当设置为 0.7 时,关键词相似度的影响占 70%,剩余的 0.3(30%)则分配给向量相似度或重排序分数;
top N:大模型最终只能接收到前N个块的信息。
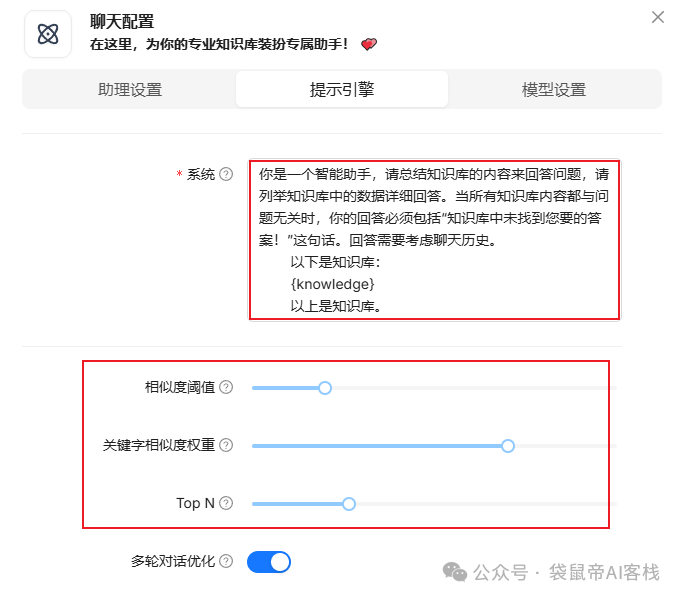
设置完成之后点击确定即可。接下来就开始测试啦~
效果如下图,说实话,随便测试了一些问题,回答是相当准确,当没有在知识库中找到答案时,也不会胡乱回答,非常精准。
特别是最后一段总结,我感觉确实把这辆车的亮点总结得非常到位!

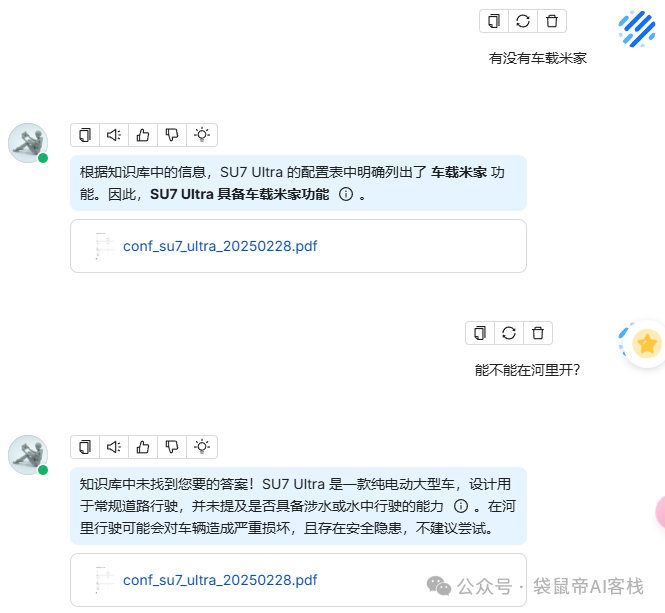

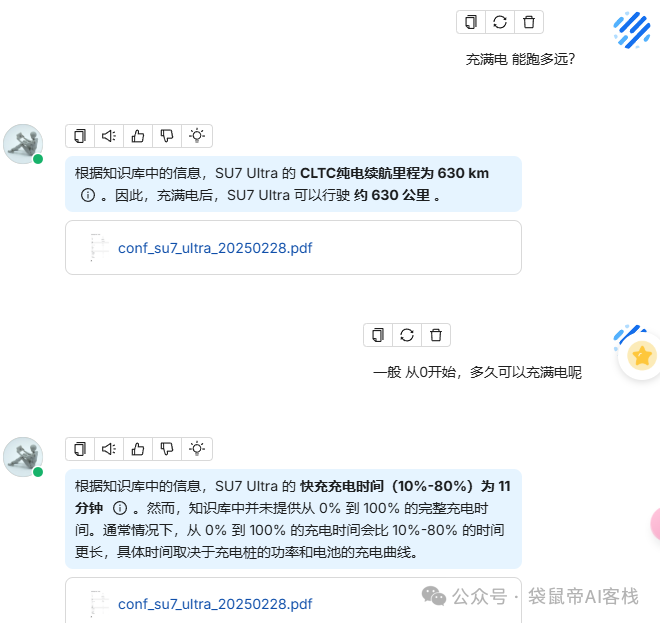

最后一段总结,说得我都想买了 哈哈哈
但就是每句话都会说根据知识库内容xxxx然后回答的非常简短,以及机器味儿浓厚。
不过这肯定是系统提示词的问题,调一下会改善很多(不是今天的重点)。
说实话,ragflow的知识库效果确实惊艳,而且这还是在我没有调整任何参数的情况下,有点太恐怖了!
Excel知识库
测试了pdf,我们接下来试试用Excel看看效果。Excel的知识库配置,只需要特别把解析方法换成Table即可(别忘了点保存)。
我准备了一个表格,对应淘宝上 搜索“内存条”的前三页商品信息
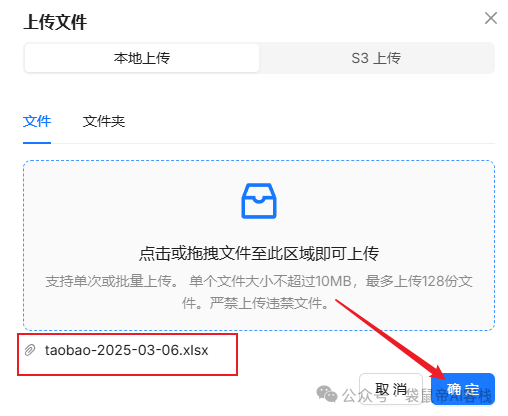
表格原始内容,格式如下
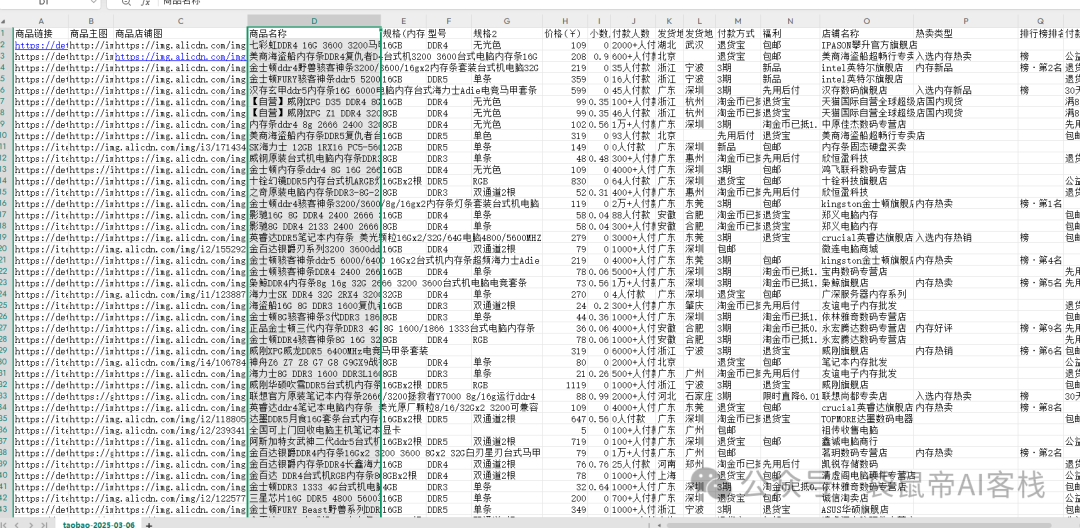
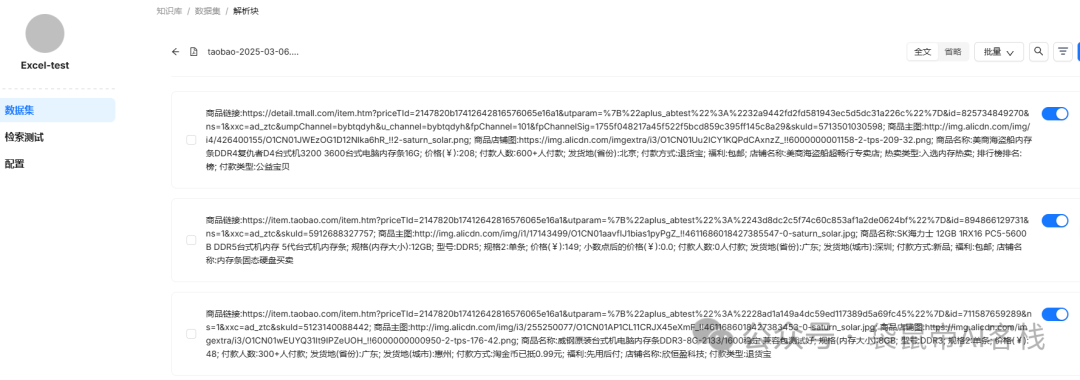
上传之后,解析

挺快的,20秒内解析完毕,解析效果如下(按照一行一个块)表格中每列的列标题非常重要,一定要准确的描述清楚每一列所代表的含义!
然后,还是跟刚才一样,创建一个对话bot,将Excel知识库与之关联,就不重复赘述了。测试效果如下:
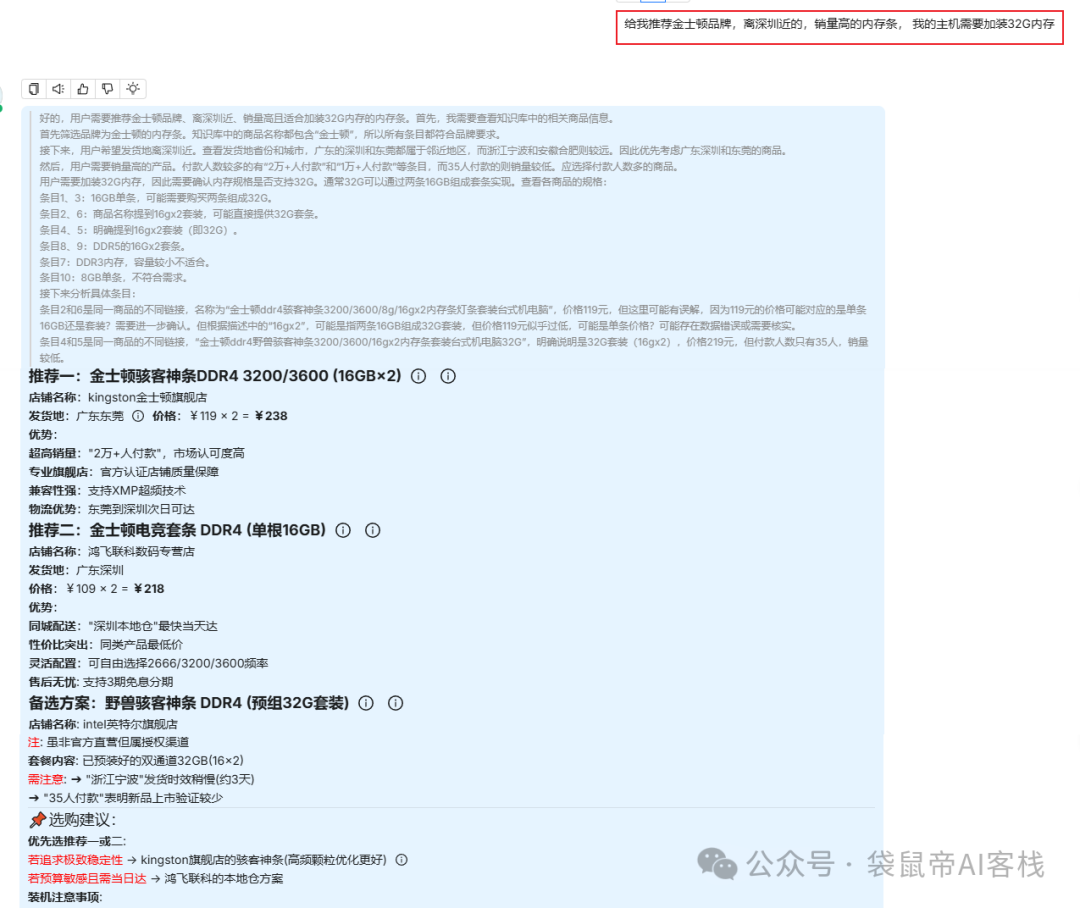
测试之后,我发现Table格式的知识库,需要更强大、智能的模型来支撑,比如DeepSeek R1、Claude3.7等。
因为表格的数据维度太多了,实测用DeepSeek V3效果不佳,无法智能的推荐商品。
并且相似度阈值和关键字相似度权重需要设置低一些(低于0.5),这样能拿到尽可能多的数据,给大模型判断。

三、ragflow的权限管理

我发现ragflow的权限管理很简单点击右上角头像->团队->邀请,要求填写被邀请对象的邮箱
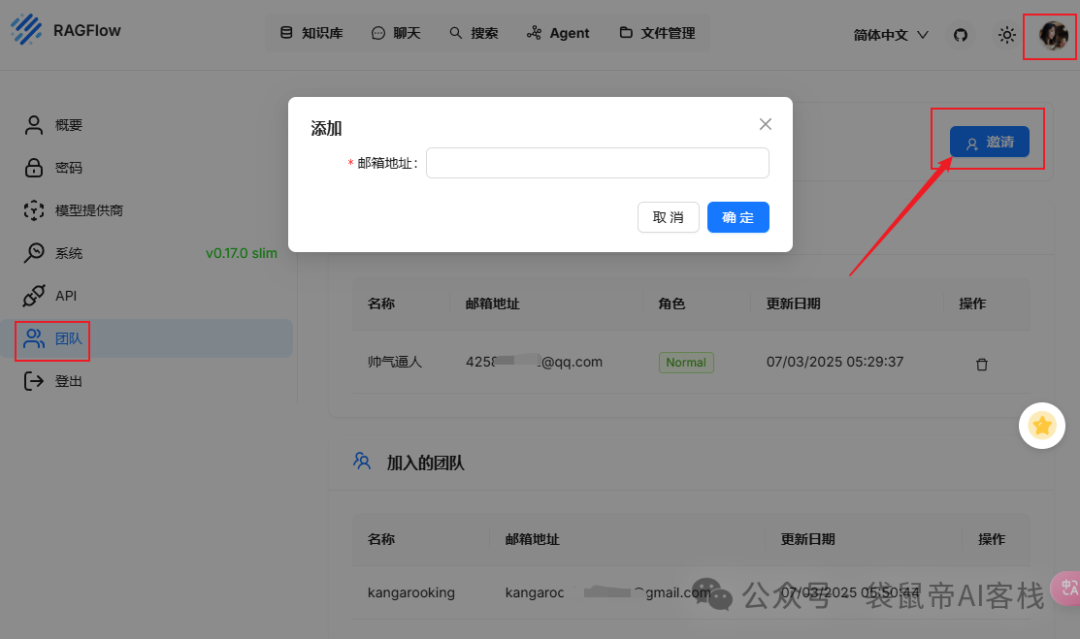
这里需要填写已经在ragflow注册的邮箱账号。
点击确定后,被邀请人需要在团队页面点击同意,才会加入你的团队空间。
但是你作为团队管理员,并不能设置团队成员角色,默认只有一个normal角色。。。
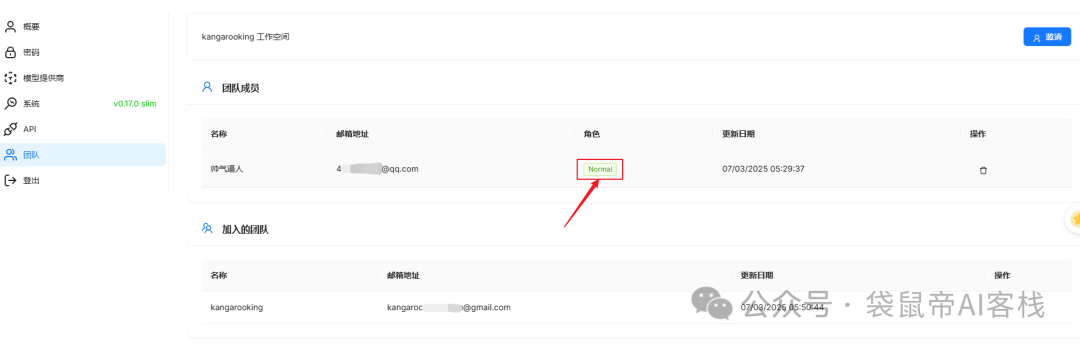
而团队成员是无法看到管理员创建的bot,agent。
管理员也无法看到成员创建的bot、agent。
只有知识库能设置私有、或者团队。
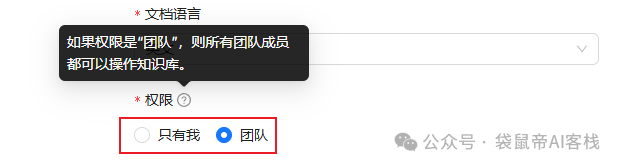
如果设置为团队,那么团队所有成员都能共用这个知识库。
链图片转存中…(img-9iejRNdl-1746157447353)]
这里需要填写已经在ragflow注册的邮箱账号。
点击确定后,被邀请人需要在团队页面点击同意,才会加入你的团队空间。
但是你作为团队管理员,并不能设置团队成员角色,默认只有一个normal角色。。。
[外链图片转存中…(img-7RO2Afd0-1746157447353)]
而团队成员是无法看到管理员创建的bot,agent。
管理员也无法看到成员创建的bot、agent。
只有知识库能设置私有、或者团队。
[外链图片转存中…(img-kACD3SxQ-1746157447353)]
如果设置为团队,那么团队所有成员都能共用这个知识库。
总结一下, ragflow的权限控制并不细,无法控制单个bot、或者agent的权限。bot、agent是完全隔离的,只有知识库可控制私有或者共享。
如何学习AI大模型?
大模型的发展是当前人工智能时代科技进步的必然趋势,我们只有主动拥抱这种变化,紧跟数字化、智能化潮流,才能确保我们在激烈的竞争中立于不败之地。
那么,我们应该如何学习AI大模型?
对于零基础或者是自学者来说,学习AI大模型确实可能会感到无从下手,这时候一份完整的、系统的大模型学习路线图显得尤为重要。
它可以极大地帮助你规划学习过程、明确学习目标和步骤,从而更高效地掌握所需的知识和技能。
这里就给大家免费分享一份 2025最新版全套大模型学习路线图,路线图包括了四个等级,带大家快速高效的从基础到高级!




如果大家想领取完整的学习路线及大模型学习资料包,可以扫下方二维码获取

👉2.大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。(篇幅有限,仅展示部分)

大模型教程
👉3.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(篇幅有限,仅展示部分,公众号内领取)

电子书
👉4.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(篇幅有限,仅展示部分,公众号内领取)

大模型面试
**因篇幅有限,仅展示部分资料,需要的扫描下方二维码领取 **


















 1811
1811

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











