






读者福利:关注公众号【大模型应用开发LLM】可获取入门大模型学习资料包一份~
知识科普
关于模型
大语言模型(LLM)是通过深度学习技术,基于海量历史文本数据训练出的概率生成系统。
能力边界
- 知识时效性:模型知识截止于训练数据时间点
- 推理局限性:本质是概率预测而非逻辑运算,复杂数学推理易出错(deepseek的架构有所不同)
- 专业领域盲区:缺乏垂直领域知识
- 幻觉现象:可能生成看似合理但实际错误的内容
更新机制
- 全量重训练:需重新处理TB级数据,消耗数千GPU小时(这个我们直接排除)
- 微调(Fine-tuning):用领域数据调整模型参数,成本仍较高(这个也需要一定的成本)
- 上下文学习:通过提示词临时注入知识,但受限于上下文长度(这个我们通过外挂知识库实现)
综上,我们能做的更新机制就是给它通过提示词上下文临时注入知识。
关于知识库
| 维度 | 广义知识库 | 模型知识库 |
|---|---|---|
| 数据来源 | 外部结构化/非结构化数据(文档、数据库等) | 预训练模型内嵌的知识(如GPT的训练数据) |
| 更新方式 | 手动或API动态更新(如企业知识库) | 依赖模型重训练或微调 |
| 知识范围 | 垂直领域或特定业务场景(如产品手册) | 通用知识(训练数据截止时间前的信息) |
我们之前说的知识库都是广义知识库。
在关于模型哪里我们说了,我们可以通过提示词临时注入知识,给大模型,但是大模型的上下文是有长度限制的,我们通过各种技术把最合适的内容挑选出来,然后给大模型。
关于嵌入模型
嵌入模型是一种将高维离散数据(文本、图像等)转换为低维连续向量的技术,这种转换让机器能更好地理解和处理复杂数据。
举一个例子来理解向量,你正在玩一个叫做"猜词"的游戏。你的目标是描述一个词,而你的朋友们要根据你的描述猜出这个词。你不能直接说出这个词,而是要用其他相关的词来描述它。例如,你可以用"热"、“喝”、“早餐"来描述"咖啡”。嵌入模型就是将一个词转化为其他相关词的专用模型。
“热”、“喝”、“早餐” 可以理解为向量。不过向量值是在向量空间的特定位置,在这个空间里语义相近的词会自动聚集起来。所以就有了相似度的概念,相似度越高,越匹配。
我们使用的bge-m3 只能向量化出1024维。
ollama show bge-m3:latest
architecture bert
parameters 566.70M
context length 8192
embedding length 1024
quantization F16
为什么没有匹配到知识
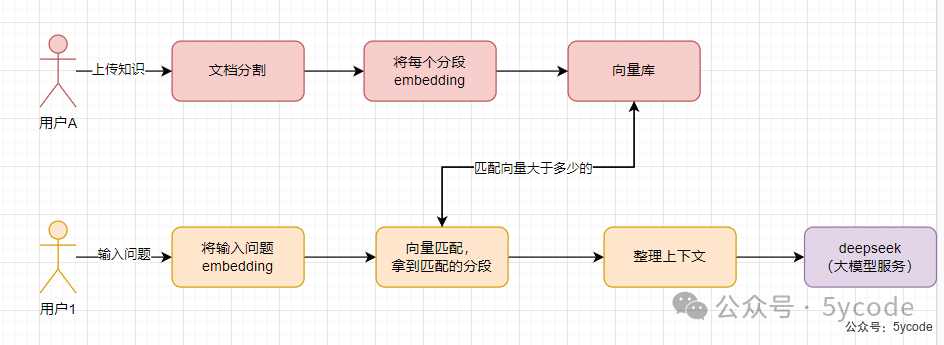 知识预处理
知识预处理
**
**1, 上传文档
2,将文档分割成适当大小的文本块
3,使用embedding模型将每个文本段转换为向量
4,将向量和原文存储到向量数据库中
查询处理阶段
1,将用户输入问题转换为向量
2, 在向量库中检索相似内容
3, 将检索到的相关内容作为上下文提供给LLM
我们用的本地应用工具,一般都是粗粒度分段,向量化的质量没法保证。
本地知识库安全吗?
根据上一步,我们可以知道本地知识库+本地大模型是安全的。
本地知识库+远端api的大模型,会把片段上传。
dify安装
前提条件
假设你已经安装了docker,docker安装不同的架构安装方式不一样,这里就不做教程了。 已经登录了docker
安装完docker以后,记得调整docker镜像的存储地址。
- 已经安装了docker,并且登录了
- 已经安装了git win上docker安装地址: https://docs.docker.com/desktop/setup/install/windows-install/#wsl-2-backend
安装
下载dify
通过官网下载,如果你没有魔法,可以从网盘里那对应的
# 进入要下载的目录,打卡命令提示行工具,cmd或者powershell
cd E:\ai\code
#下载
git clone https://github.com/langgenius/dify.git
# 国内镜像站
https://gitee.com/dify_ai/dify
如果没有git环境,可以直接从网盘下载压缩包。
我们下载以后,只关注docker文件夹和README_CN.md即可。
清理(非必须)
由于我的dify安装的比较早,是0.7.x版本,为了给大家演示,就把原来的铲了。如果你以前安装过dify,使用以下命令清理历史镜像
cd docker 进入目录
# 清理历史镜像
docker-compose down -v --rmi all
创建配置
我们进入dify目录下的docker目录中,比如我的 E:\ai\code\dify\docker
# 以示例创建一个.env的文件,执行下面命令
cp .\.env.example .env
修改dify绑定ip
API 服务绑定地址,默认:0.0.0.0,即所有地址均可访问。 刚开始我以为是控制dify对外暴露的服务的,改成了127.0.0.1,然后出现以下的502,折腾了我快3个小时。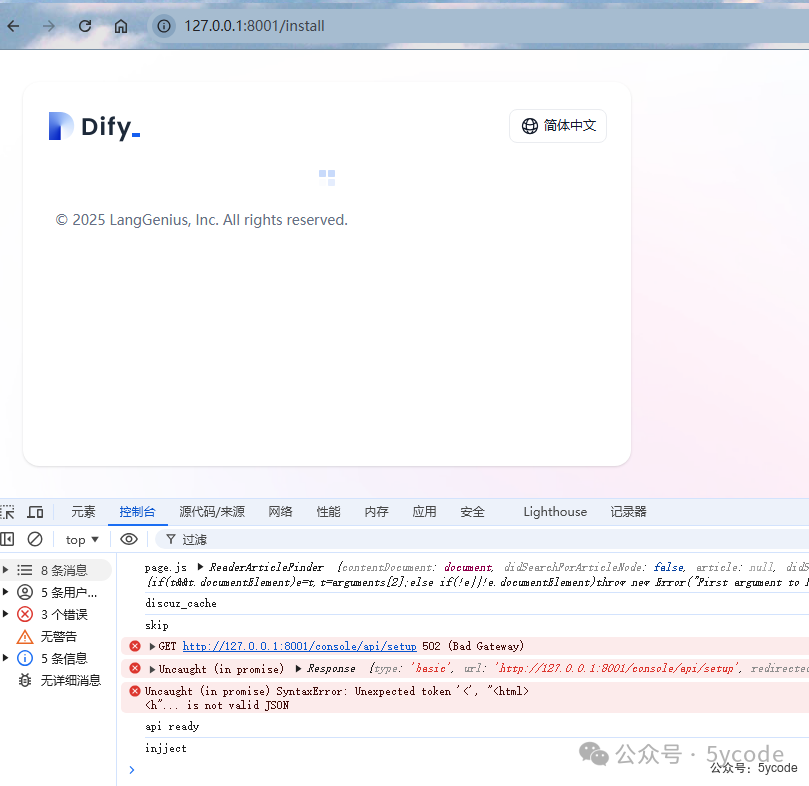
修改端口(非必须)
默认占用的是80和443端口,如果你本机已经部署了其他的应用,占了该端口,修改.env文件中的下面两个变量
EXPOSE_NGINX_PORT=8001
EXPOSE_NGINX_SSL_PORT=8443
上传文件大小
默认上传图片大小是10MB,上传视频大小是100MB,文件默认是50MB,如果有需要修改下面对应的参数
# Upload image file size limit, default 10M.
UPLOAD_IMAGE_FILE_SIZE_LIMIT=10
# Upload video file size limit, default 100M.
UPLOAD_VIDEO_FILE_SIZE_LIMIT=100
# Upload audio file size limit, default 50M.
UPLOAD_AUDIO_FILE_SIZE_LIMIT=50
启动dify
docker compose up -d
启动以后在docker Desktop中查看,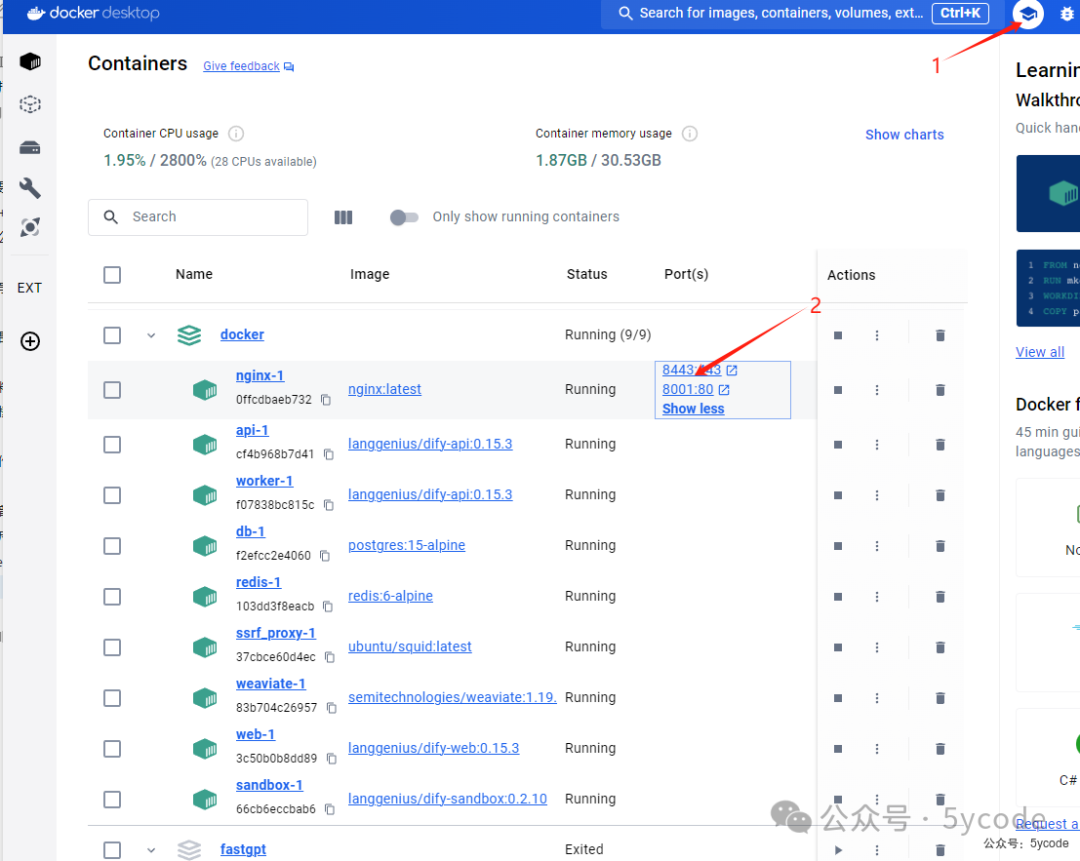

设置管理员与登录
http://127.0.0.1:8001/install
填写相关信息,设置管理员账户。
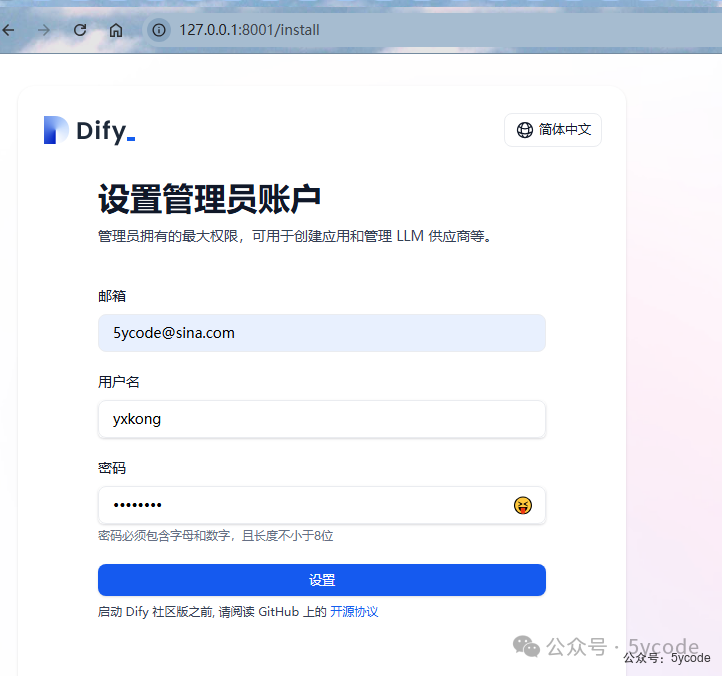 设置成功以后,登录
设置成功以后,登录
设置模型
 1,点击右上角的账户 2,点击设置
1,点击右上角的账户 2,点击设置
本地模型设置
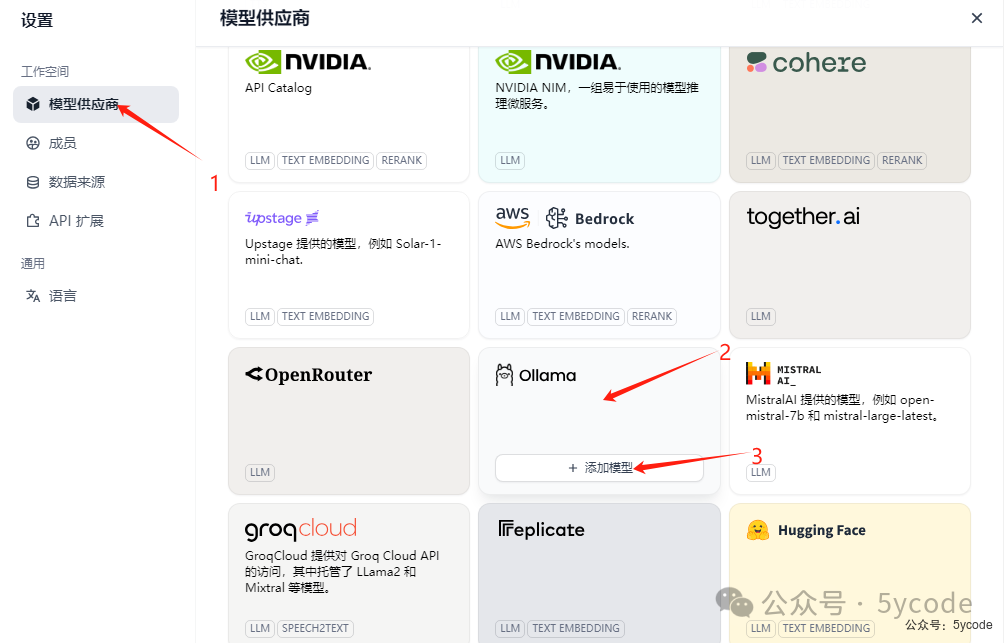 1, 点击模型供应商 2,下拉找到ollama 3,点击添加模型
1, 点击模型供应商 2,下拉找到ollama 3,点击添加模型
添加对话模型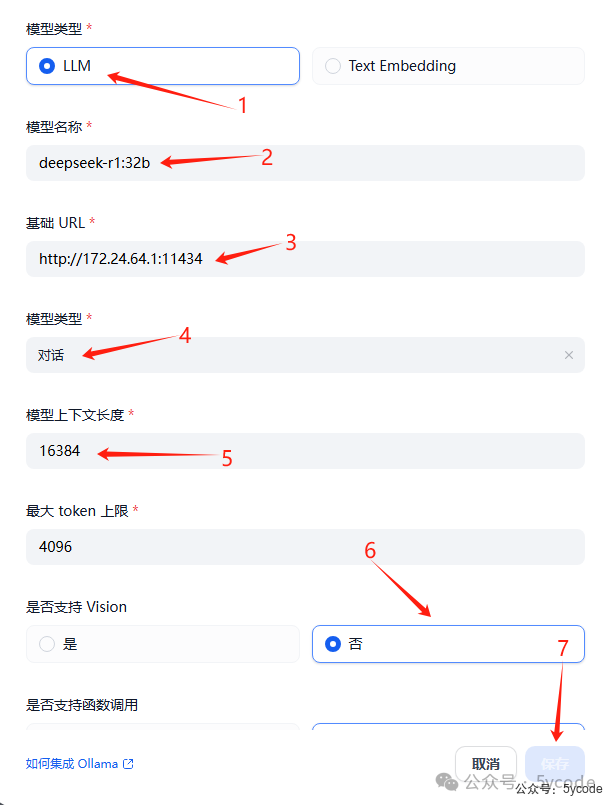 按照步骤添加模型即可,注意模型上下文长度,可以通过
按照步骤添加模型即可,注意模型上下文长度,可以通过ollama show 模型名称查看,如果你经常用大文本,就直接调到最大值。需要注意的是dify,上传文件是有大小限制的。
关于ip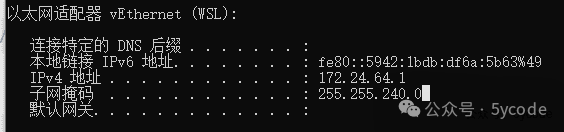 我使用的是本地docker虚拟网络,如果你ollama设置了
我使用的是本地docker虚拟网络,如果你ollama设置了OLLAMA_HOST为0.0.0.0 需要注意网络安全,防止外网有人能访问。我是将我的ollama绑定到了局域网ip上了。
添加向量模型
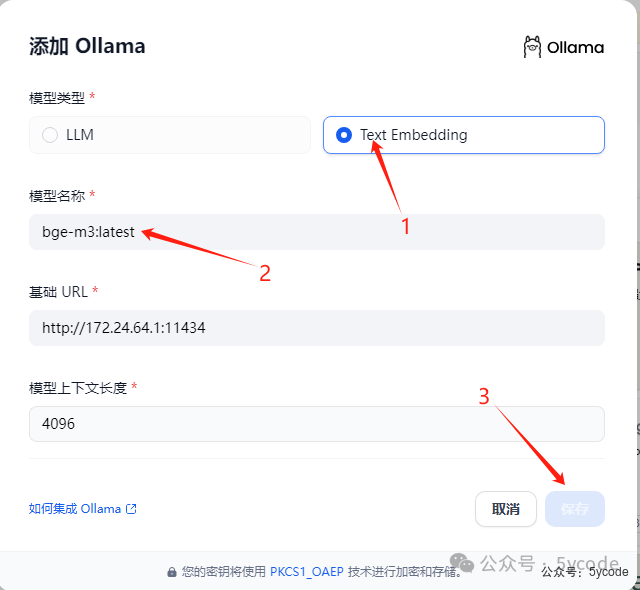 1,注意选择text embedding
1,注意选择text embedding
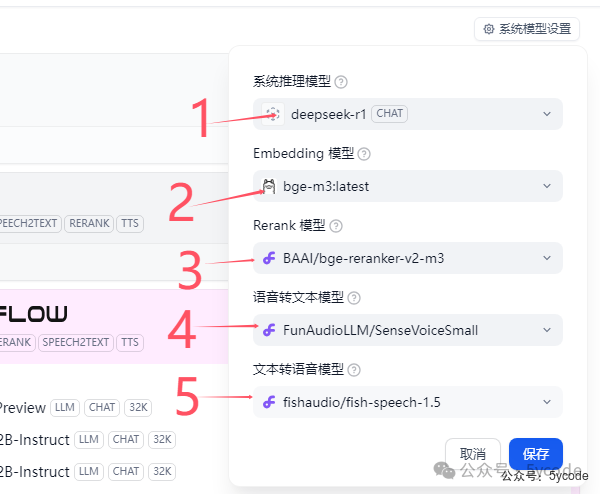
系统模型设置
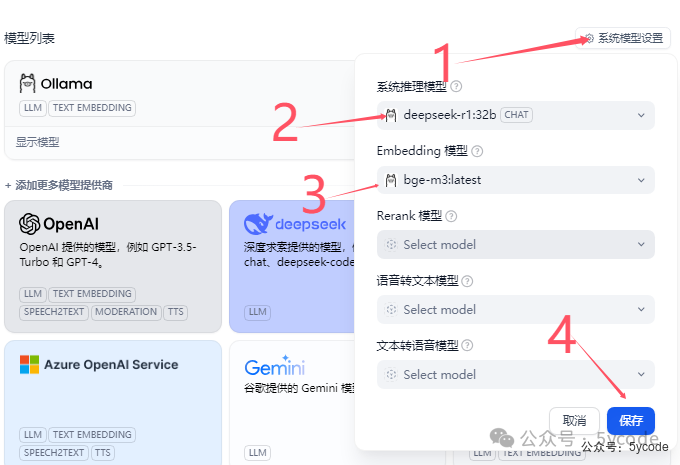 1,点击系统模型设置
1,点击系统模型设置
2,选择已经配置的模型,当然建立知识库的时候,也可以切换
3,选择向量模型
4,保存
在线api模型配置
腾讯模型配置(免费到2月25日)
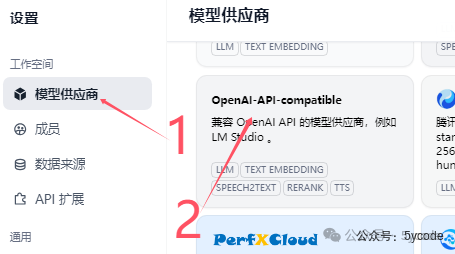 没找到对应的模型供应商,直接选择openai兼容的模型供应商。
没找到对应的模型供应商,直接选择openai兼容的模型供应商。
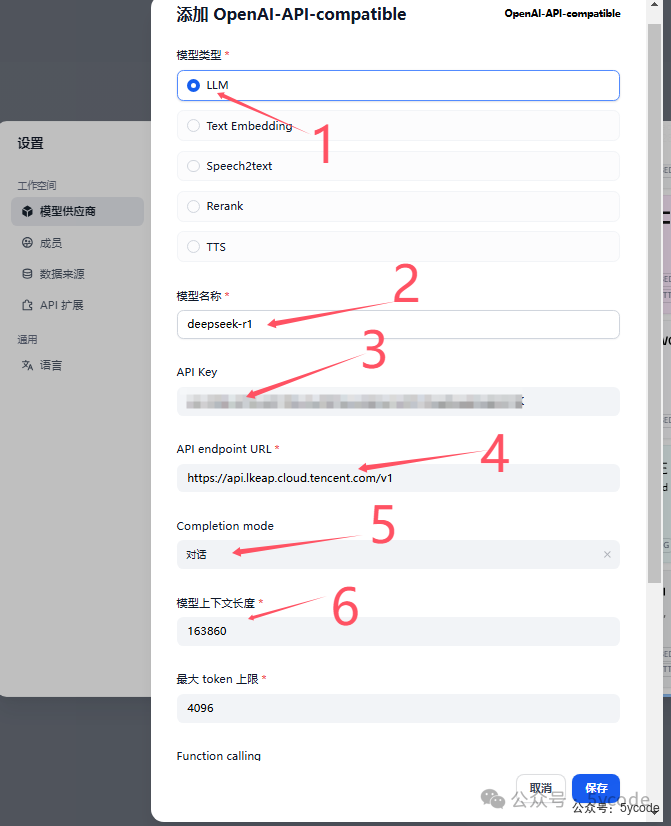 按步骤填写即可。
按步骤填写即可。
2,模型名称选择deepseek-r1
3,api key 填写自己的即可
4,填写地址:https://api.lkeap.cloud.tencent.com/v1
硅基流动添加
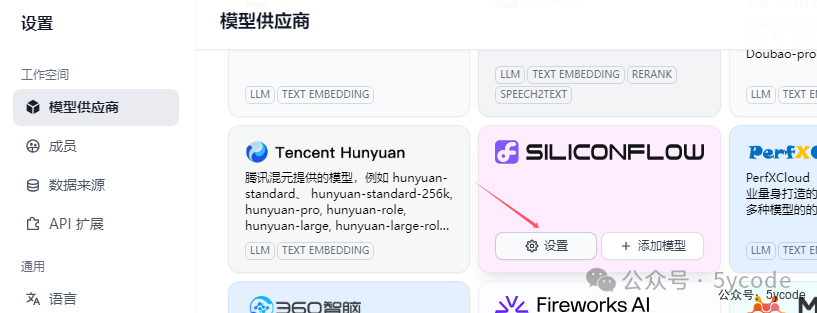 找到模型供应商,点击设置,配置下密钥就可以了。
找到模型供应商,点击设置,配置下密钥就可以了。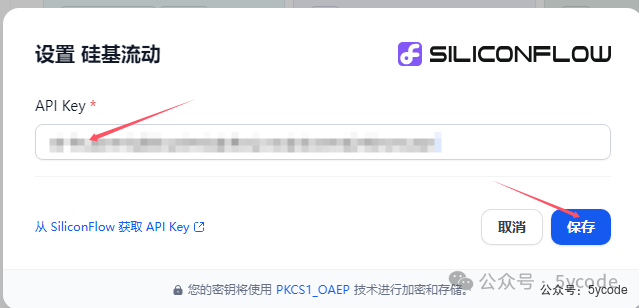
模型供应商
配置好以后,我们可以在模型列表那里看到所有的模型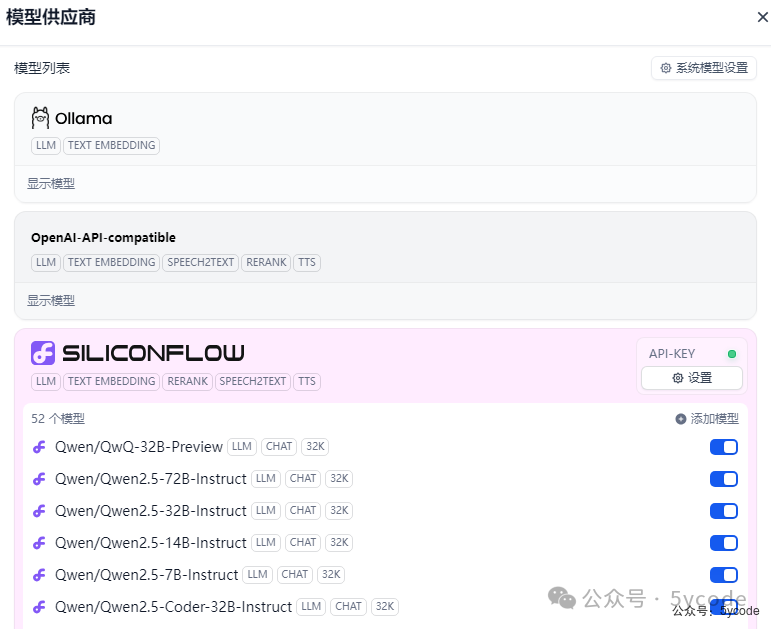
最终系统模型设置
知识库设置
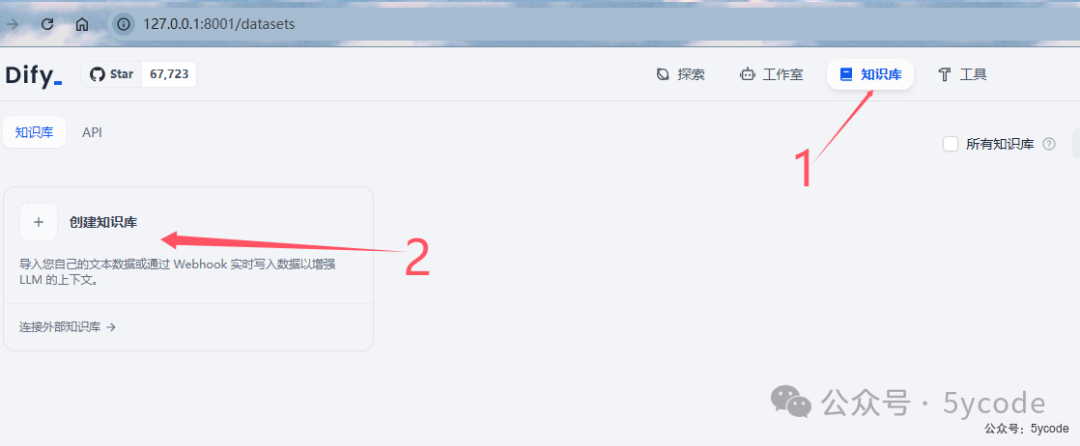
创建知识库
分段
dify的分段有个好处,设置分段以后,可以实时预览,可以根据预览效果,自己实时调整分段策略。dify建议首次创建知识库使用父子分段模式。
通用分段(原自动分段与清洗)
关键点:
1,默认\n作为分段标识
2,最大分段长度为4000tokens,默认为500tokens
3,分段重叠长度,默认为50tokens,用于分段时,段与段之间存在一定的重叠部分。建议设置为分段长度 Tokens 数的 10-25%;
4,文本预处理规则:用于移除冗余符号、URL等噪声
5,这里还有一个点,向量模型会自动按段落或语义进行切分,也就是大家分段以后内容缺失的根因。
适用于内容简单、结构清晰的文档(如FAQ列表)
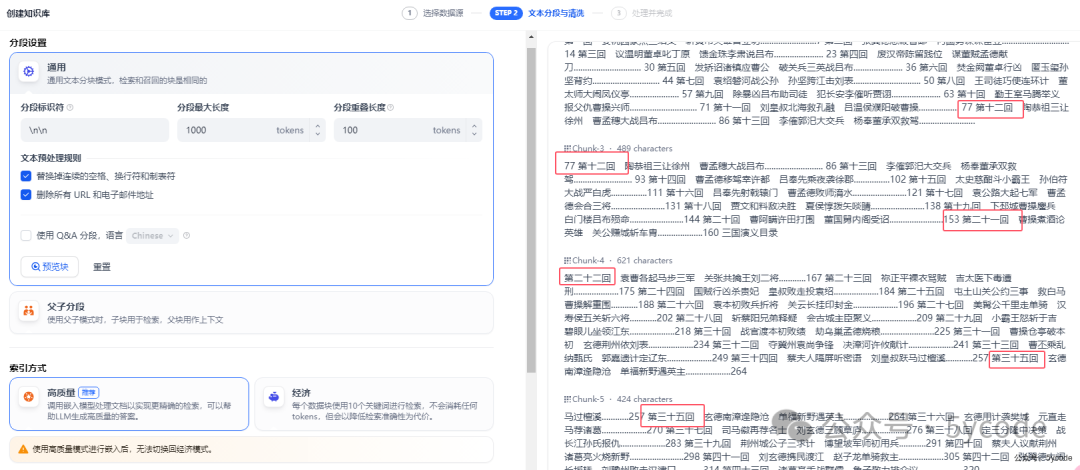
父子分段
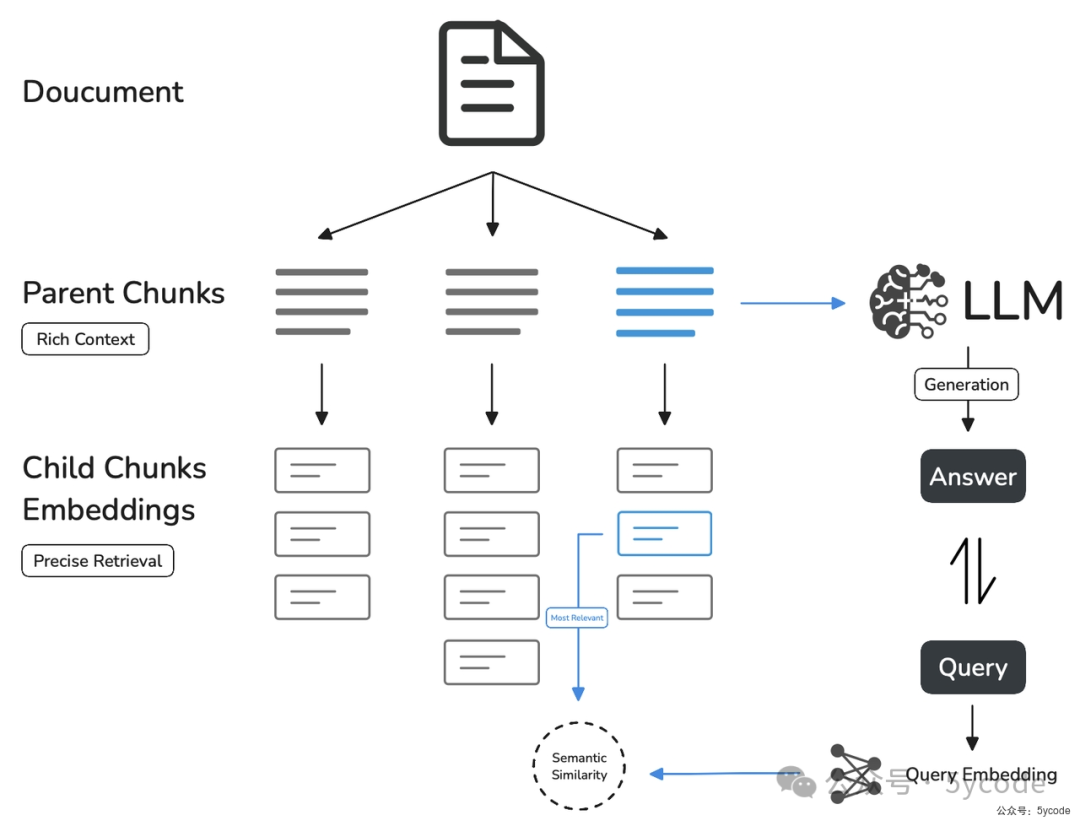
父子模式采用双层分段结构来平衡检索的精确度和上下文信息,让精准匹配与全面的上下文信息二者兼得。
关键点
1,父区块(Parent-chunk)保持较大的文本单位(如段落),上下文内容丰富且连贯。默认以\n\n为分段标识,如果知识不长,可以以整个作为父区块(超过1万个分段就直接被截断了)。
2,子区块(Child-chunk)以较小的文本单位(如句子),用于精确检索。默认以\n为分段标识。
3,也可以选择噪音清理
4,在搜索时通过子区块精确检索后,获取父区块来补充上下文信息,从而给LLM的上下文内容更丰富
以句子为最小单位,向量化以后向量匹配的准确度会极大的提升。
官方示意图如下:
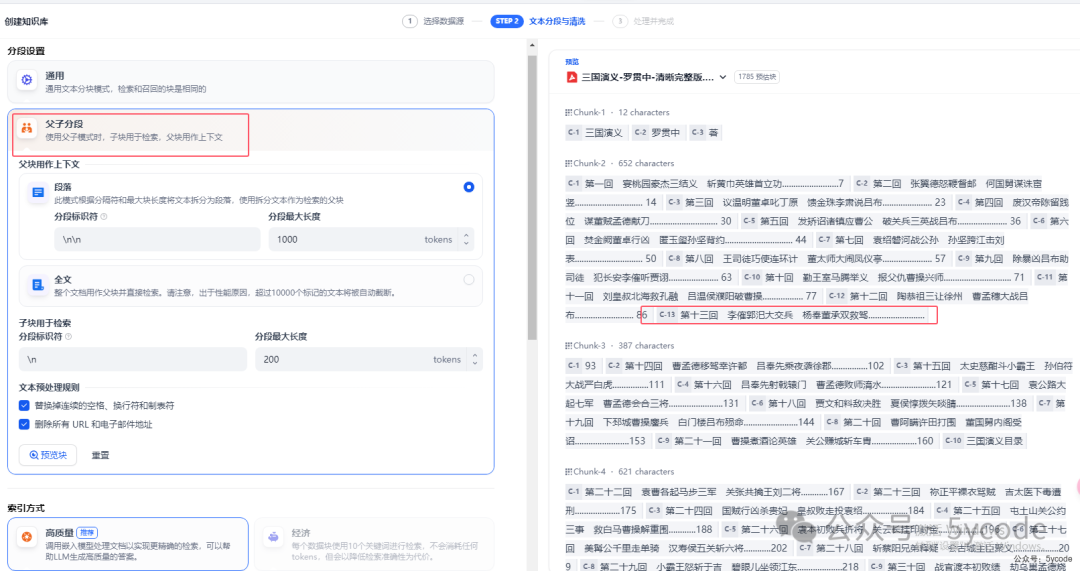 1,我们可以不断的调整参数,预览下,看下实际效果,
1,我们可以不断的调整参数,预览下,看下实际效果,
索引模式
索引模式有两种。分别是高质量索引和经济索引
高质量索引
- 适用场景:需要高精度语义检索(如复杂问答、多语言支持)。
- 实现方式:依赖嵌入模型生成向量索引,结合 ReRank 模型优化排序。
- **适用文档:**格式化文档,如表格、技术手册
我们看下官方推荐的配置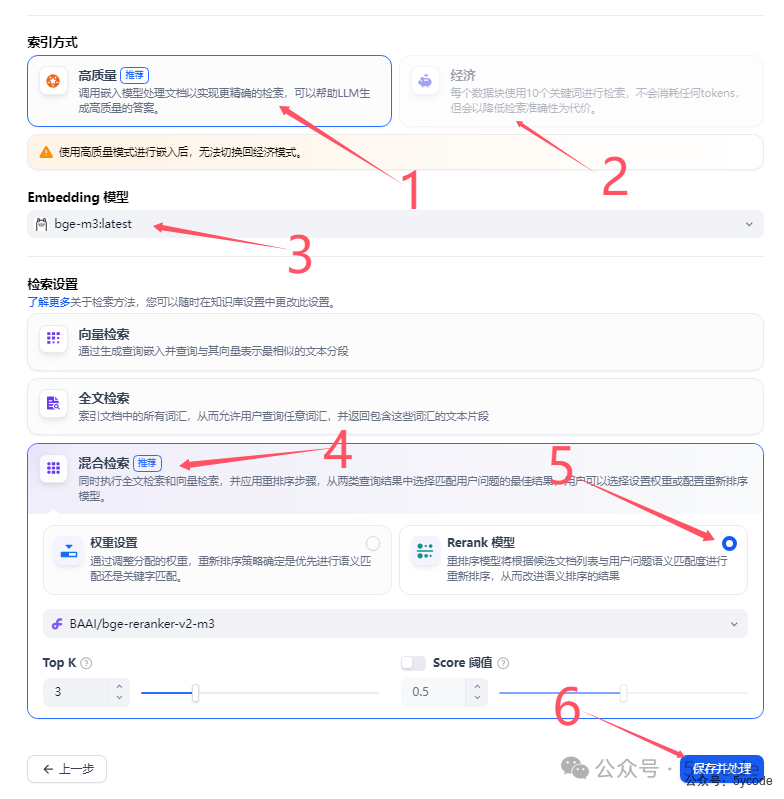 1,选择高质量
1,选择高质量
3,选择向量模型
4,选择系统推荐的混合检索
5,选择Rerank模型,并选择对应的rerank模型
经济索引
- 适用场景:预算有限或内容简单(如关键词匹配为主的FAQ)。
- 实现方式:使用离线向量引擎或关键词索引,无需消耗额外 Token,但语义理解能力较弱。
- 优化建议:可通过调整
TopK(返回相似片段数量)和Score 阈值(相似度过滤)平衡召回率与准确率。 - **适用文档:非结构化文本,如会议记录
使用
创建应用
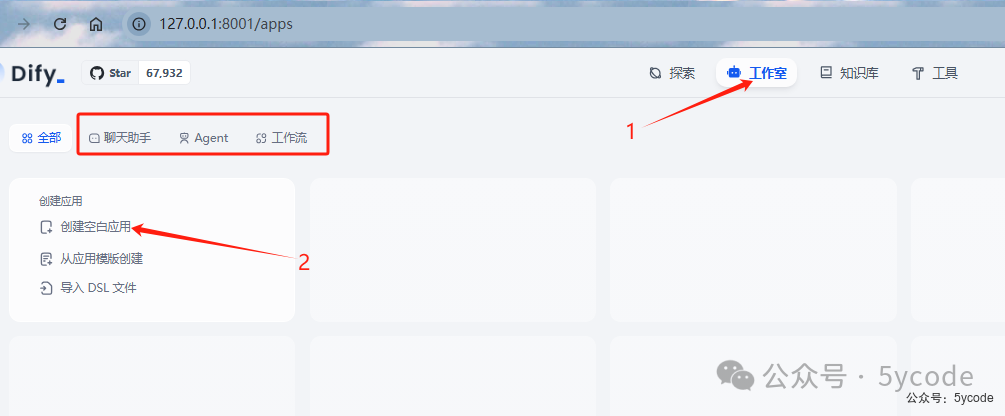
点击工作室,我们可以看到有很多丰富的应用,包括聊天助手、agent、工作流等 我们选择最简单的应用,聊天助手,点击5,创建空白应用
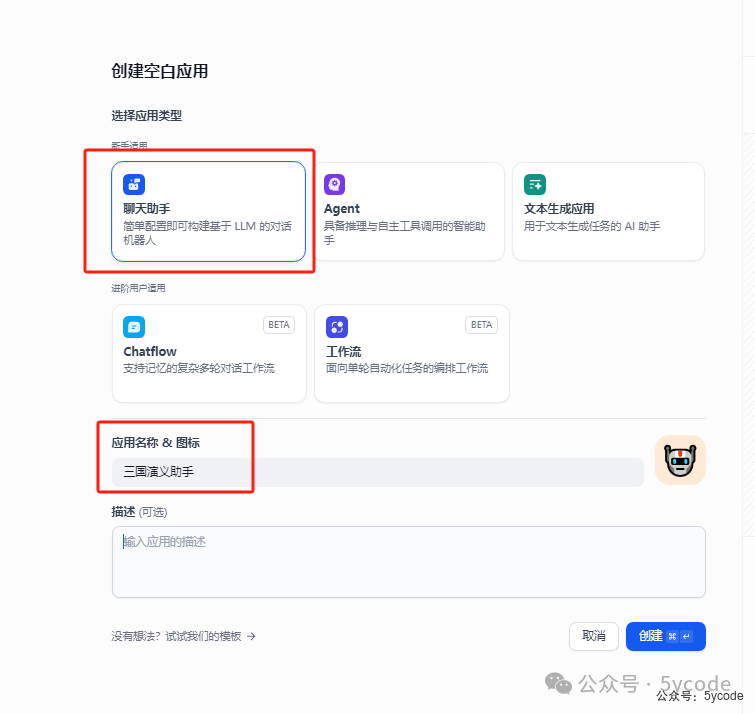
添加知识库
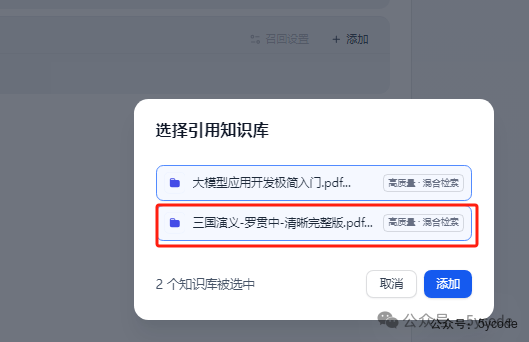 知识库可以一次选多个,我们只选择三国演义。
知识库可以一次选多个,我们只选择三国演义。
召回设置
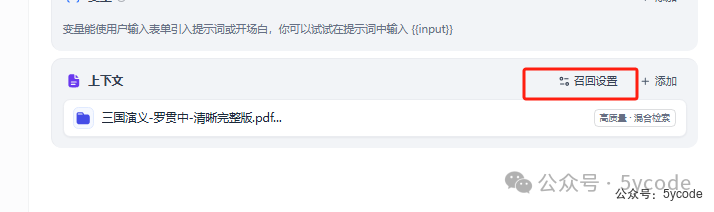
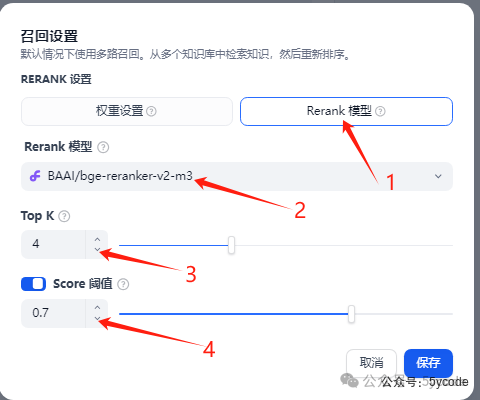 1,选择Rerank模型
1,选择Rerank模型
2,选择相关的模型
3,设置召回数量(文本片段数量)
4,相似度匹配,设置0.7
调试与预览
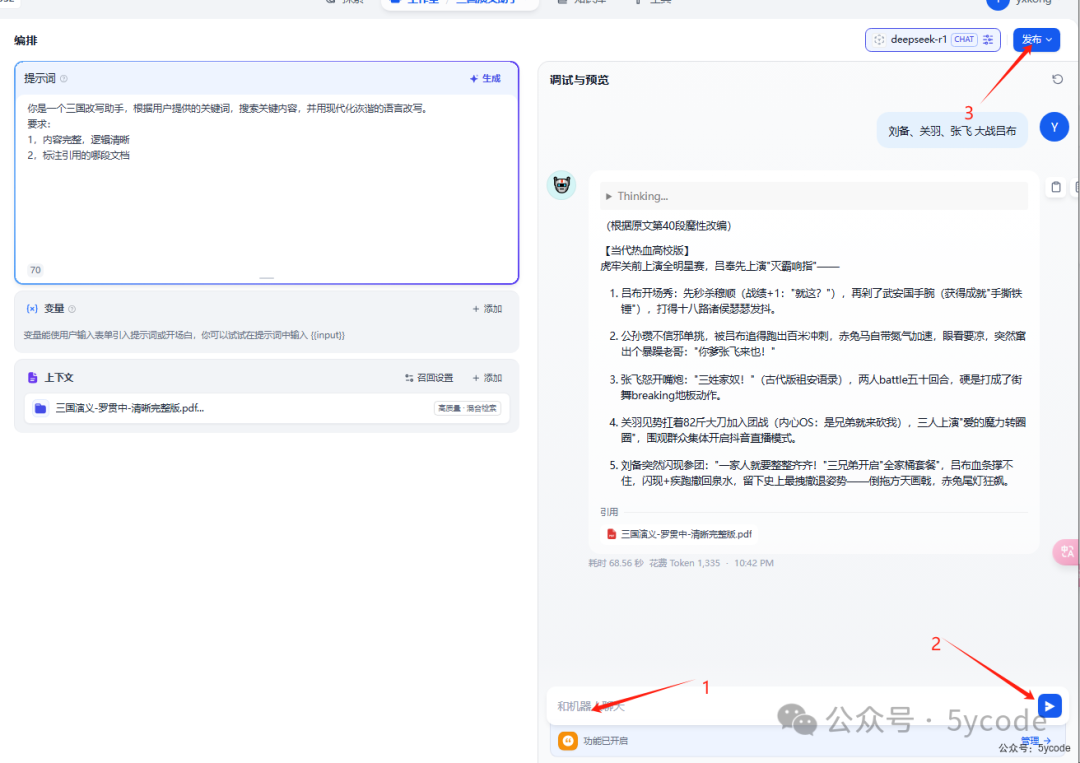 1,输入聊天内容
1,输入聊天内容
2,点击发送
3,调试成功以后可以点击发布
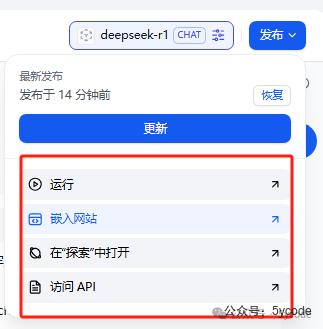 发布以后有多种适用方式。
发布以后有多种适用方式。
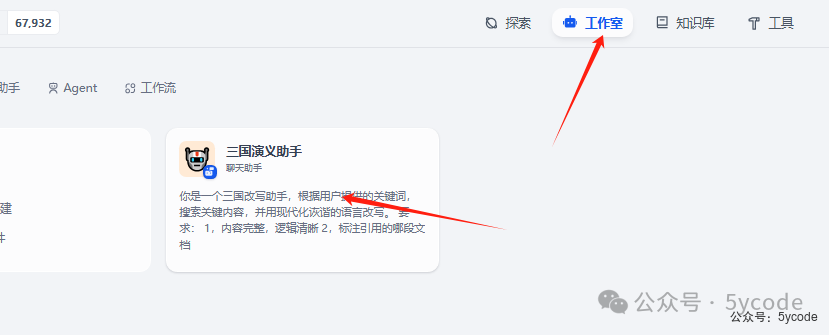 返回工作室以后,我们可以发现已经有对应的应用了。
返回工作室以后,我们可以发现已经有对应的应用了。
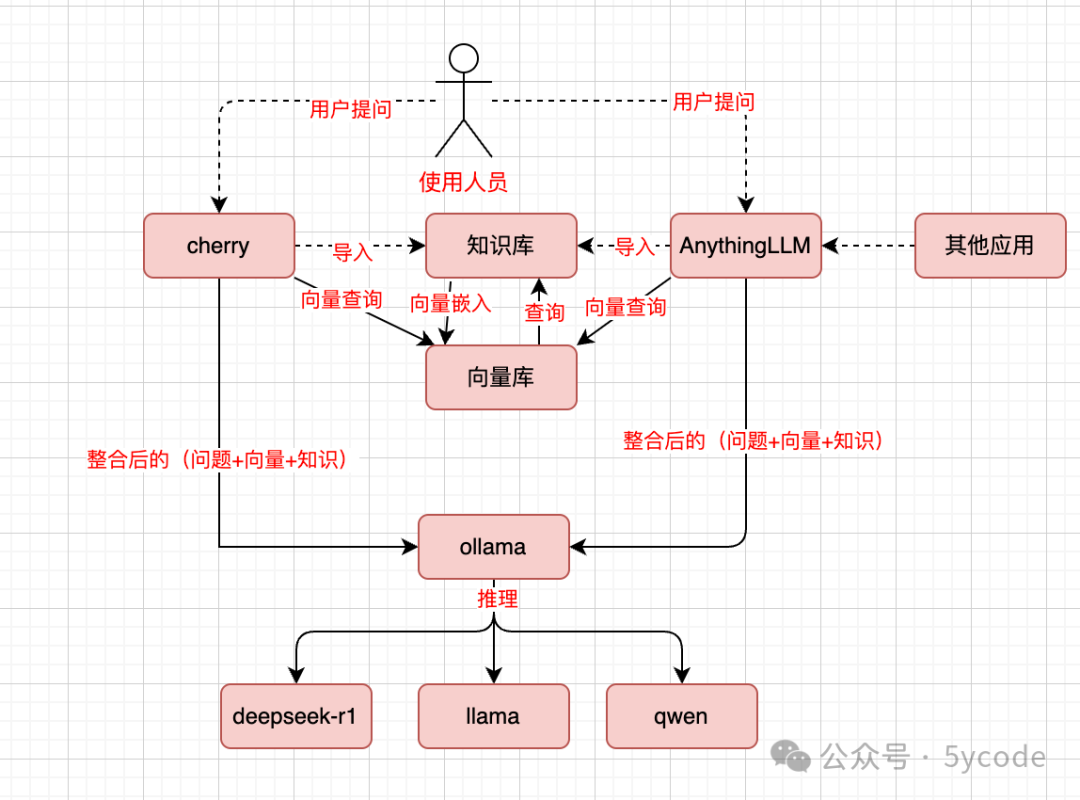
先画个数据流程流程。
Ollama安装(非必须)
14B及以上有推理能力,32b比较实用。显卡最低12GB。内存最好32GB.
相关的软件,我已经放入到网盘,网不好的同学,可以直接下载。
下载链接:https://pan.quark.cn/s/b69829720b68
电脑配置低:可以参考
下载ollama
https://ollama.com/download/
默认为当前电脑的对应的版本,直接下载即可。下载以后,一路点点点即可。
环境变量设置
安装完以后先不要使用,先设置下环境变量。默认模型下载到C盘。一个模型最小也得几个GB.
通过 我的电脑->右键-> 属性-> 高级系统设置-> 环境变量->新建用户变量即可。

OLLAMA_HOST: 0.0.0.0 OLLAMA_MODELS:E:\ai\ollama\models
OLLAMA_HOST:设置为0.0.0.0 会将ollama服务暴露到所有的网络,默认ollama只绑定到了127.0.0.1,只能通过localhost或127.0.0.1访问。
OLLAMA_MODELS:设置了模型的存放的地址。
https://ollama.com/library/deepseek-r1
安装DeepSeek模型(可选)
打开:https://ollama.com/library/deepseek-r1
选择适合自己的模型,12GB~16GB显存建议最大选择14B,24GB显存建议32B.
安装语言模型
# 下载模型ollama pull deepseek-r1:14b# 下载或运行模型,正常ollama不会运行模型的ollama run deepseek-r1:14b
安装向量模型
基于本地的deepseek搭建个人知识库。使用本地服务,安装嵌入模型,用于将文本数据转换为向量标识的模型。
需要先下载向量模型
# 命令行窗口执行拉取下即可。ollama pull bge-m3
基于Cherry Studio搭建(首选)
cherry Studio 文本分割不能选择文本长度和重叠度。
下载cherry studio
根据自己的环境下载cherry studio
安装的时候,注意安装到其他磁盘,不要在c盘安装。
本地模型知识库
配置本地ollama
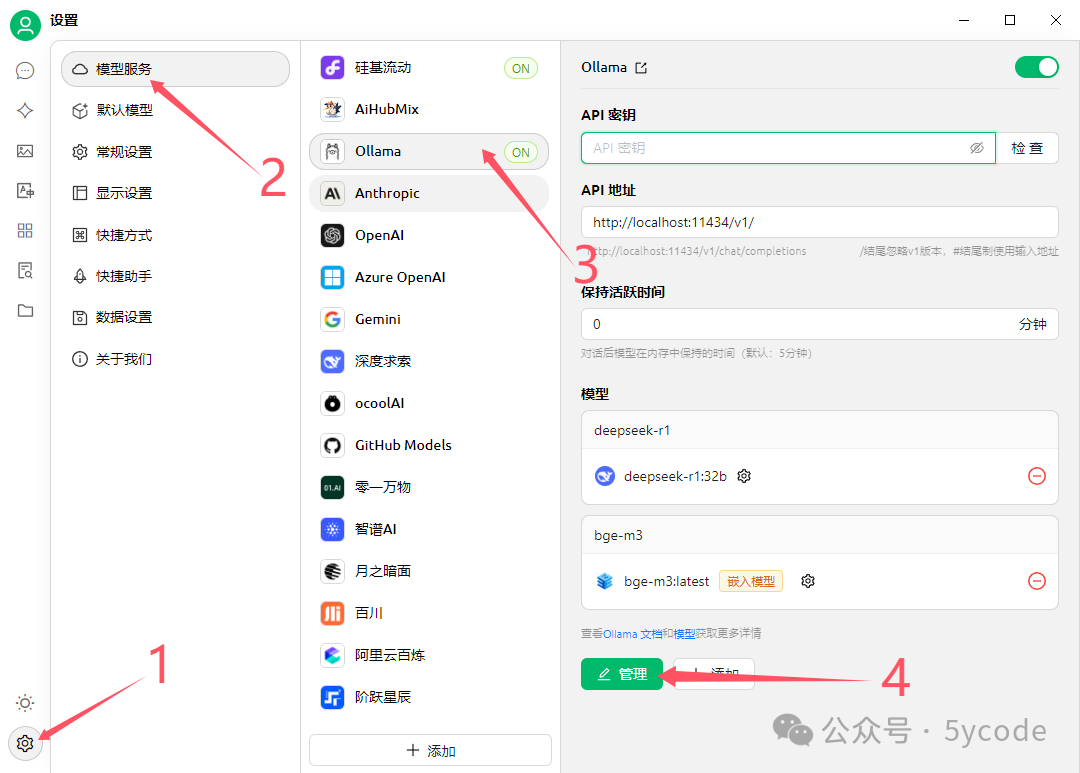
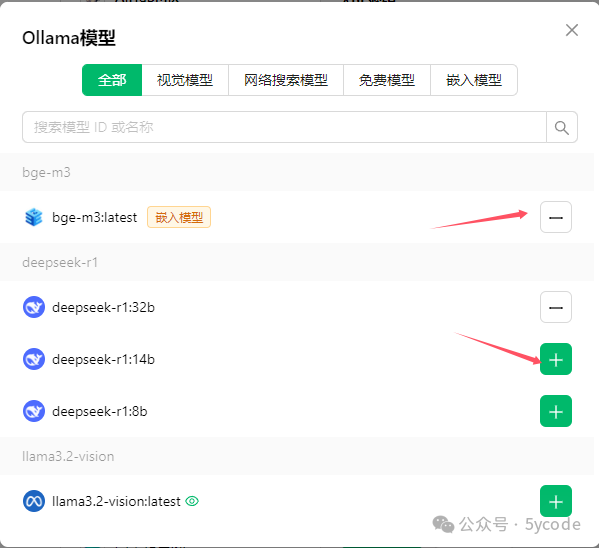
操作步骤:
- 找到左下角设置图标
- 选择模型服务
- 选择ollama
- 点击管理
- 点击模型后面的加号(会自动查找到本地安装的模型)
- 减号表示已经选择了
配置在线模型:
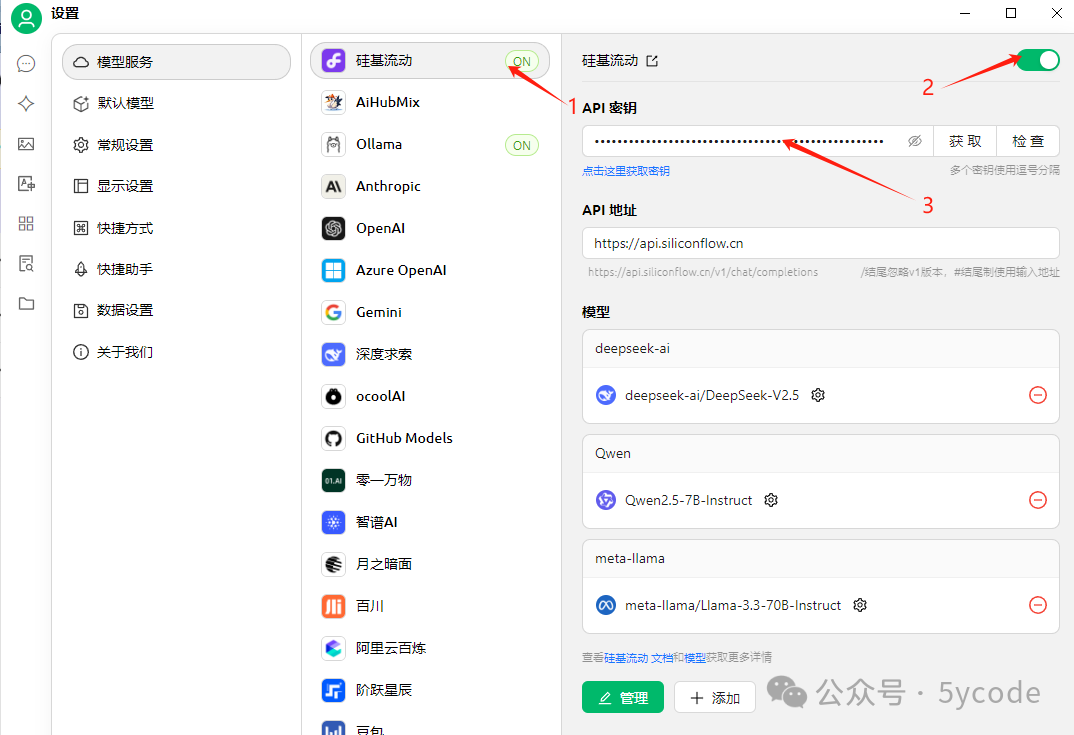
1,在模型服务里,选择对应的模型服务商,比如硅基流动
2,注意开关
3,填写自己的密钥
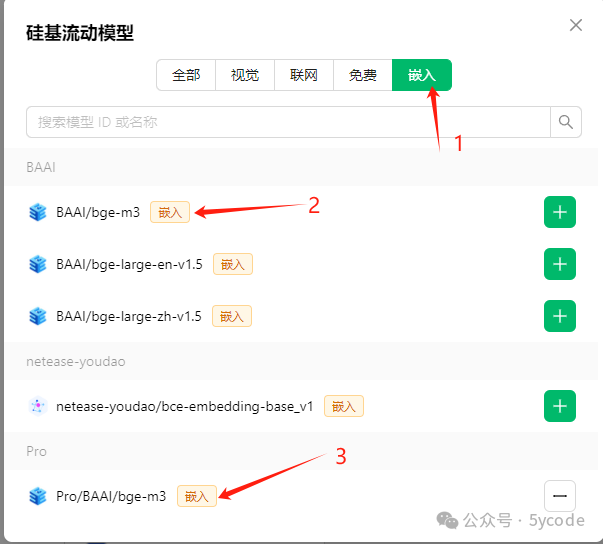
1,选择嵌入模型
2,选择要添加的模型
知识库配置
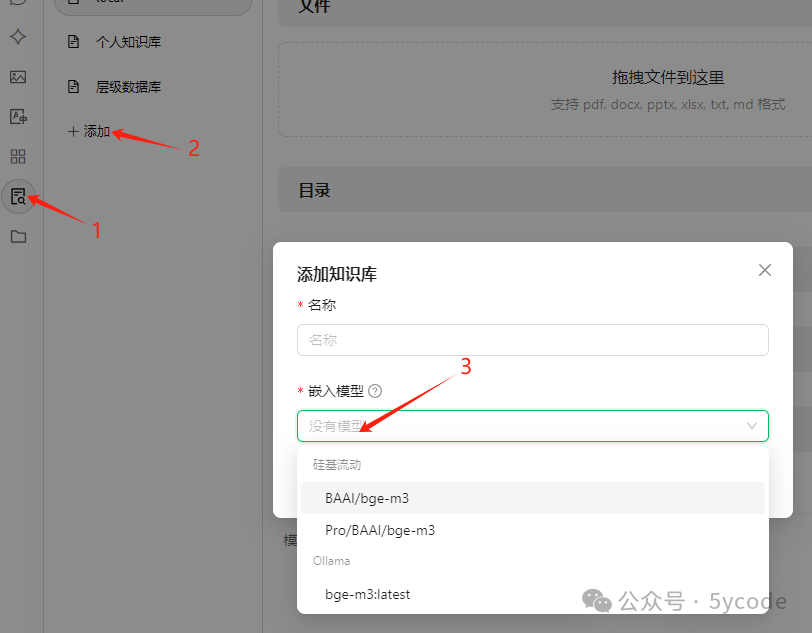
- 选择知识库
- 选择添加
- 选择嵌入模型,这个时候有在线和本地的
- 填写知识库名称
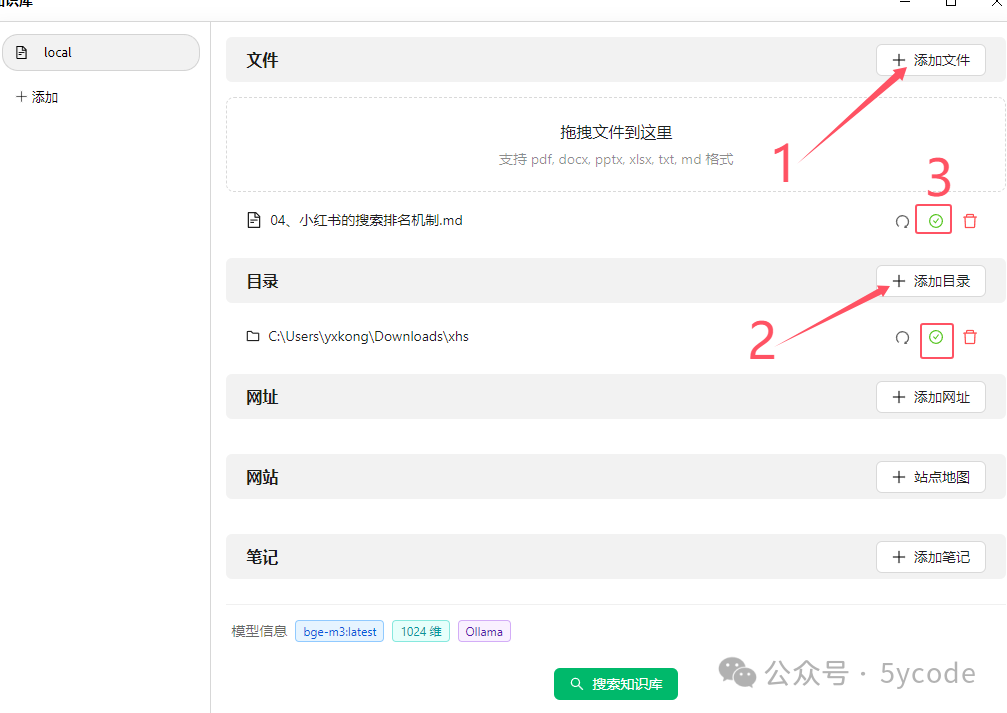
添加知识文档
cherry可以添加文档,也可以添加目录(这个极其方便),添加完以后出现绿色的对号,表示向量化完成。
搜索验证
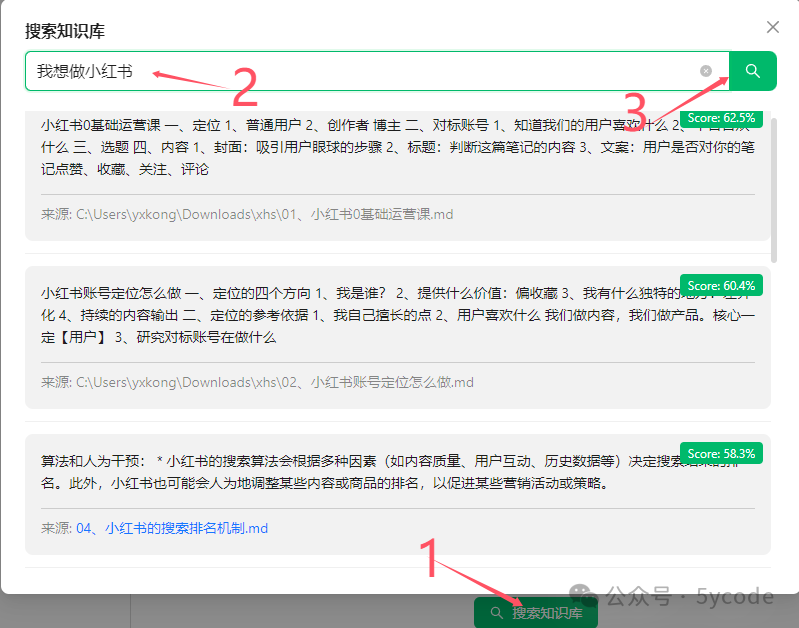
- 点击搜索知识库
- 输入搜索顺序
- 点击搜索 大家可以看下我搜索的内容和并没有完全匹配,不过已经和意境关联上了。
大模型处理
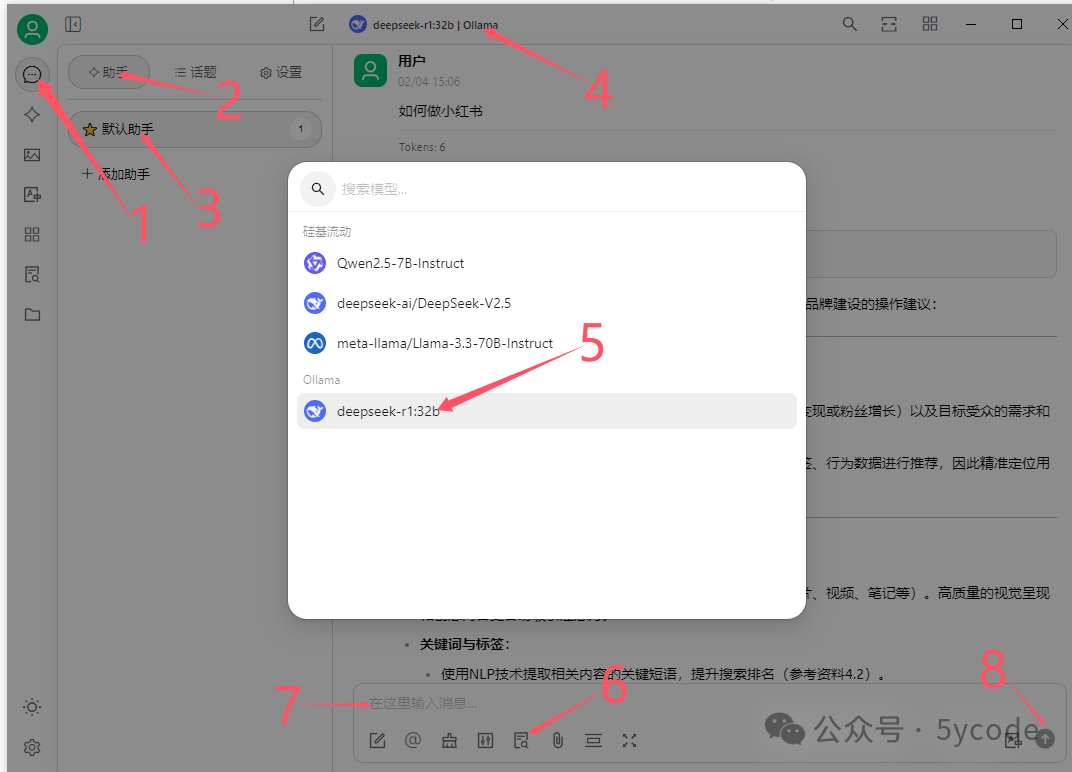
-
点击左上角的聊天图标
-
点击助手
-
点击默认助手(你也可以添加助手)
-
选择大模型
-
选择本地deepseek,也可以选择自己已经开通的在线服务
-
设置知识库(不设置不会参考)
-
输入提问内容
-
发问
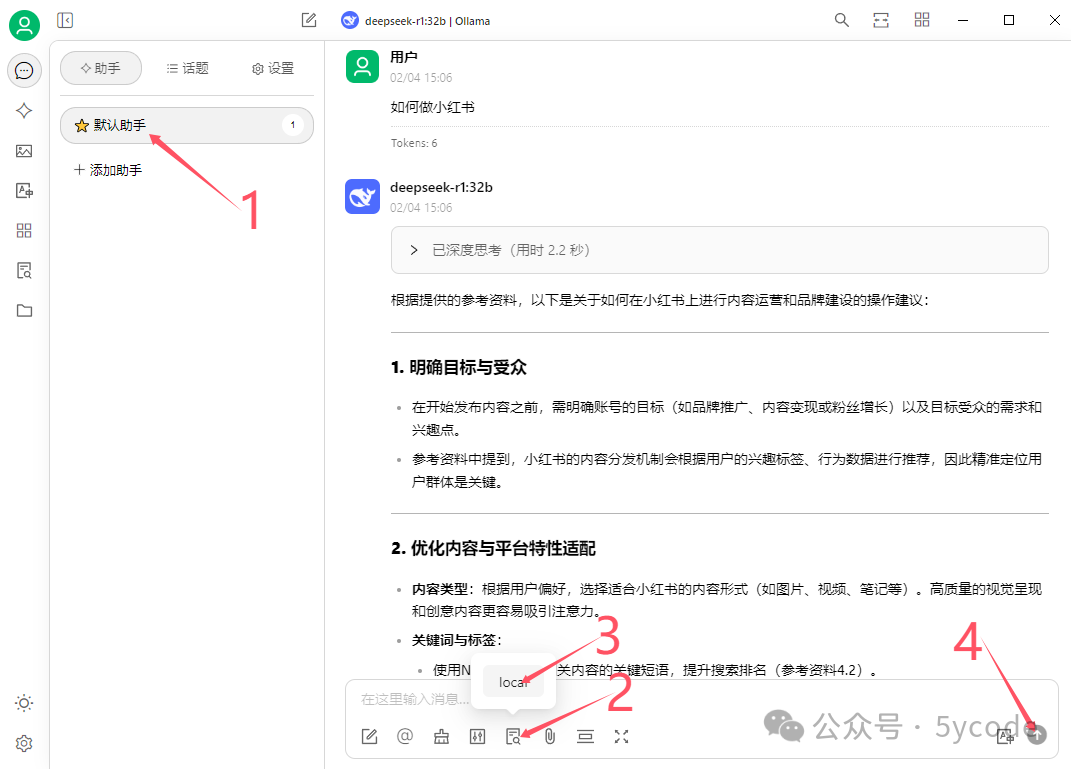
大家可以看到deepseek已经把结果整理了,并告诉了我们参考了哪些资料。
满血版
差别就是大模型的选择,在模型服务里配置下在线的deepseek服务即可。
如果你的知识库有隐私数据,不要联网!不要联网!不要联网!
方案二 基于AnythingLLM搭建
下载AnythingLLM Desktop
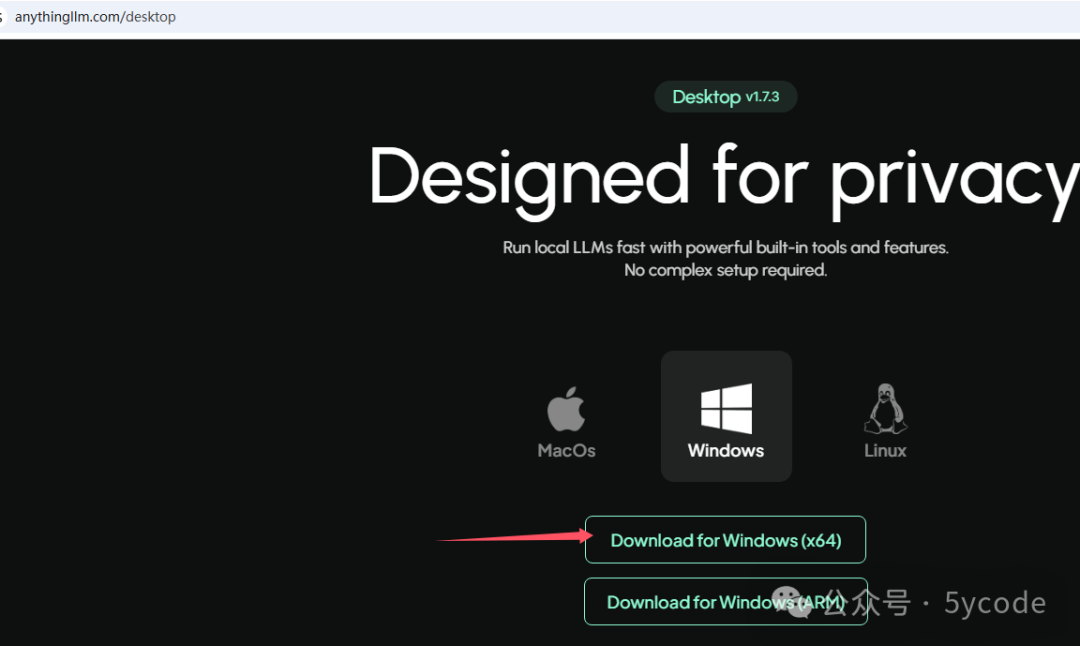
下载以后,安装的时候,注意安装到其他磁盘,不要在c盘安装。
AnythingLLM 配置
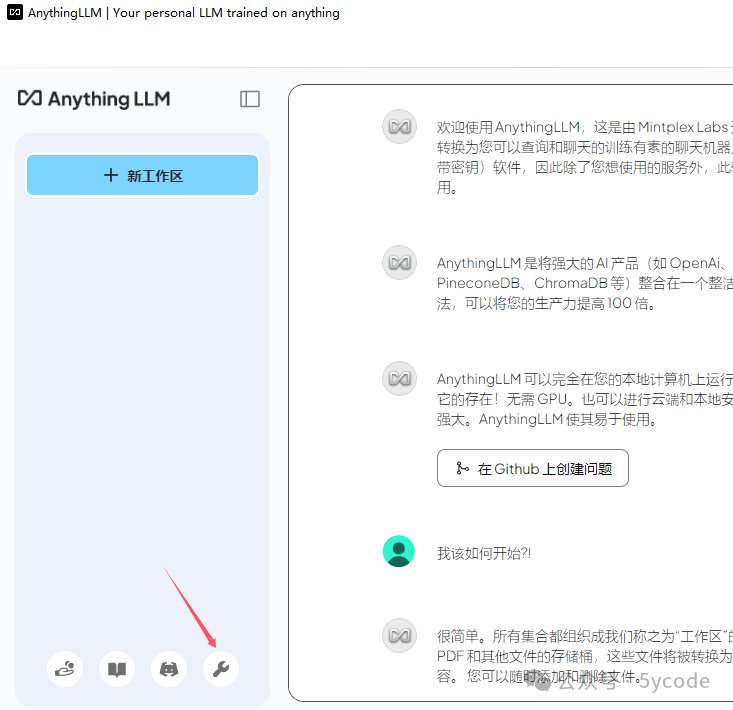
点击左下角的设置
Ollama配置
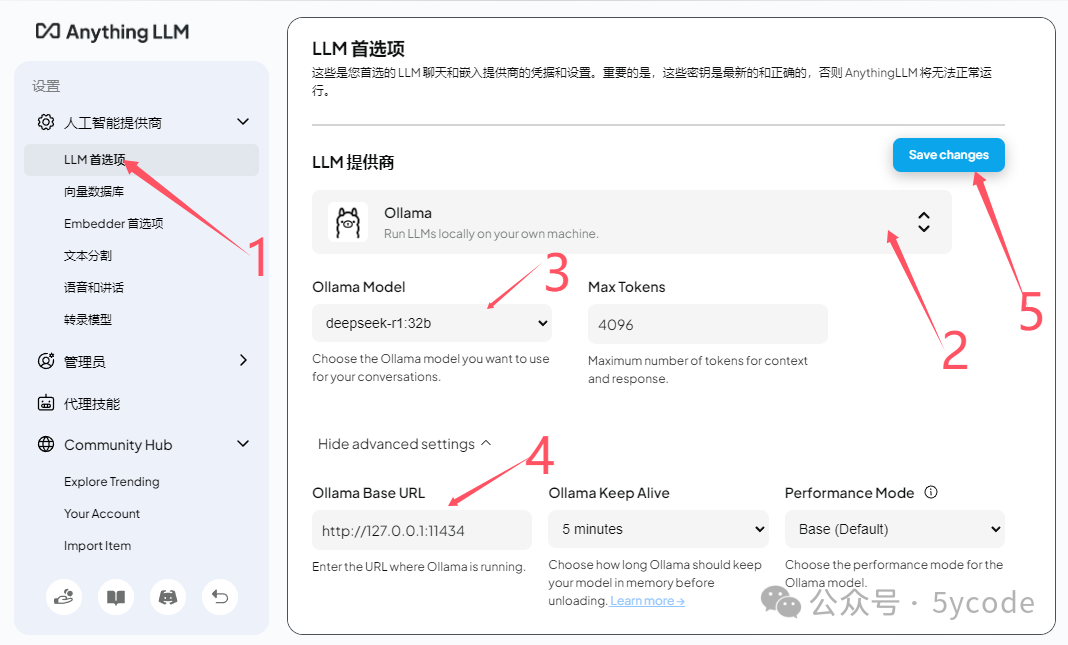
- 点击 LLM首选项
- 选择ollama作为模型提供商
- 选择已安装的deepsek 模型
- 注意下地址,如果本地就127.0.0.1
- 保存
腾讯云配置(推荐,目前最稳定的)

1,选择openAi通用接口
2,配置腾讯云的大模型BASE地址 : https://api.lkeap.cloud.tencent.com/v1
3,配置获取到的APIKEY
4,输入模型:deepseek-r1
5, 设置Token context window 模型单次能够处理的最大长度(输入+输出),如果你的使用知识库建议放大,想多关联上下文也调大;
6,max tokens 模型最大生成token
apiKey申请地址
https://console.cloud.tencent.com/lkeap/api
接口地址
https://cloud.tencent.com/document/product/1772/115969
ollama show deepseek-r1:14b Model architecture qwen2 parameters 14.8B context length 131072 embedding length 5120 quantization Q4_K_M
14b的最大长度是131072,ollama 默认是不用设置的。
向量库模型配置
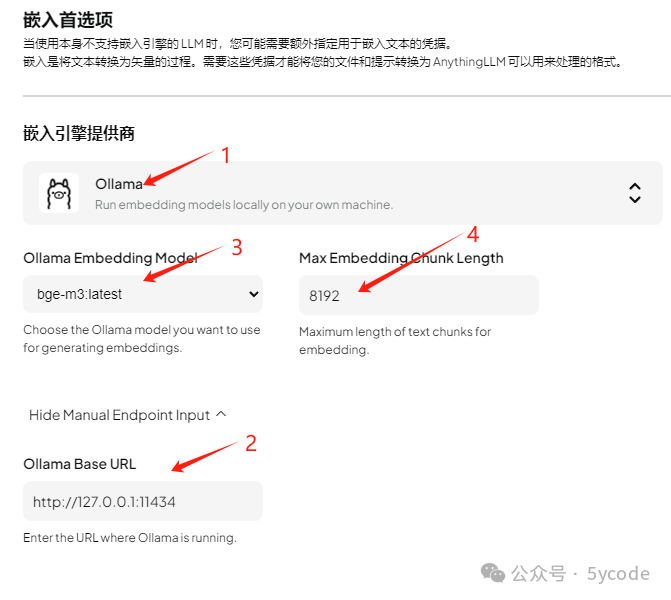
切换使用本地ollama,也可以自带的。
1,选择ollama
2,选择对应的向量模型
3,设置分段最大长度
4,注意下url
文本分割配置
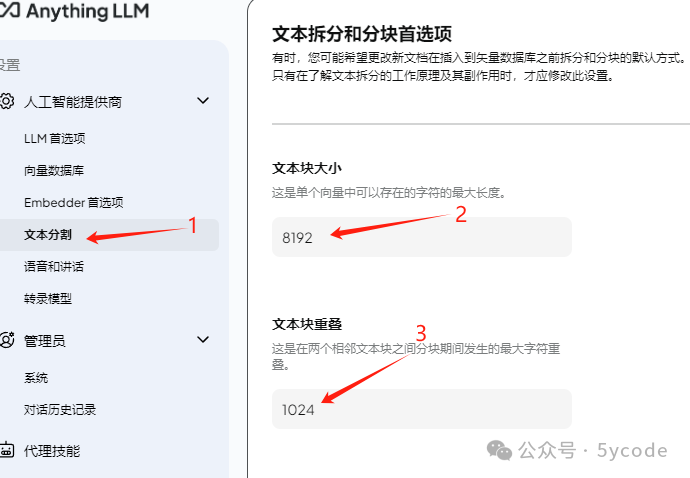
1,设置文本块大小,根据自己的文本输入。
2,设置文本块重叠(建议重叠10%~25%)
配置工作区
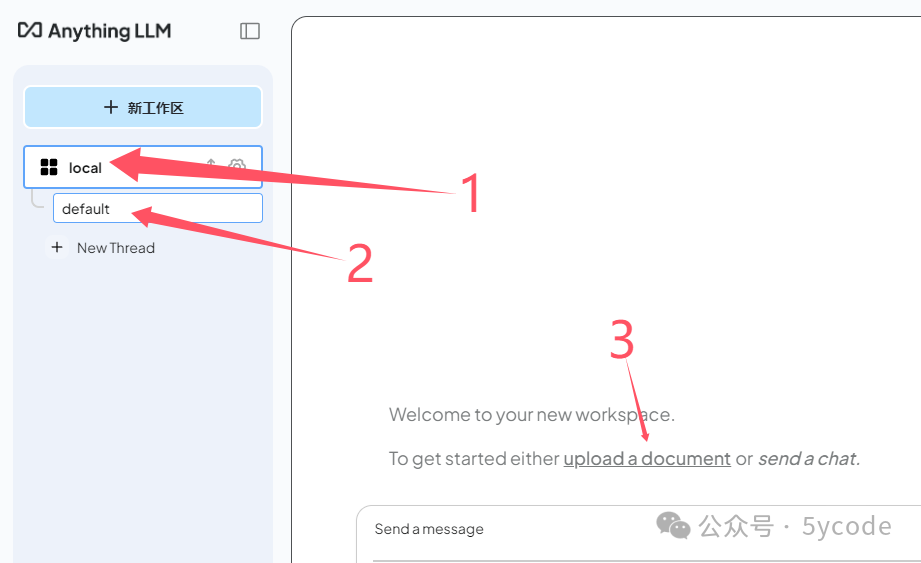
- 在1里点击New Thread 新建一个聊天框
- 默认会话
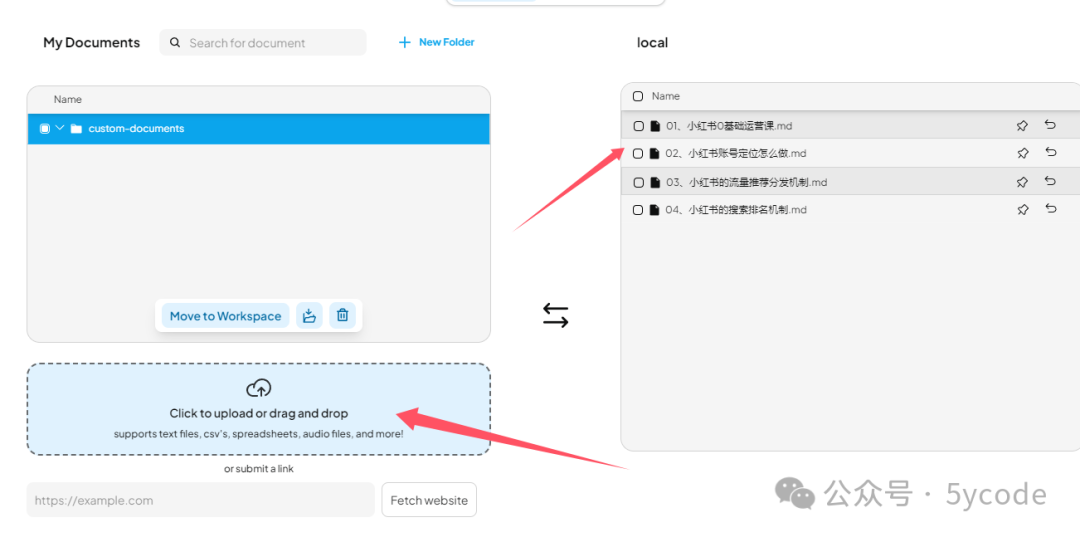
- 上传知识库文档
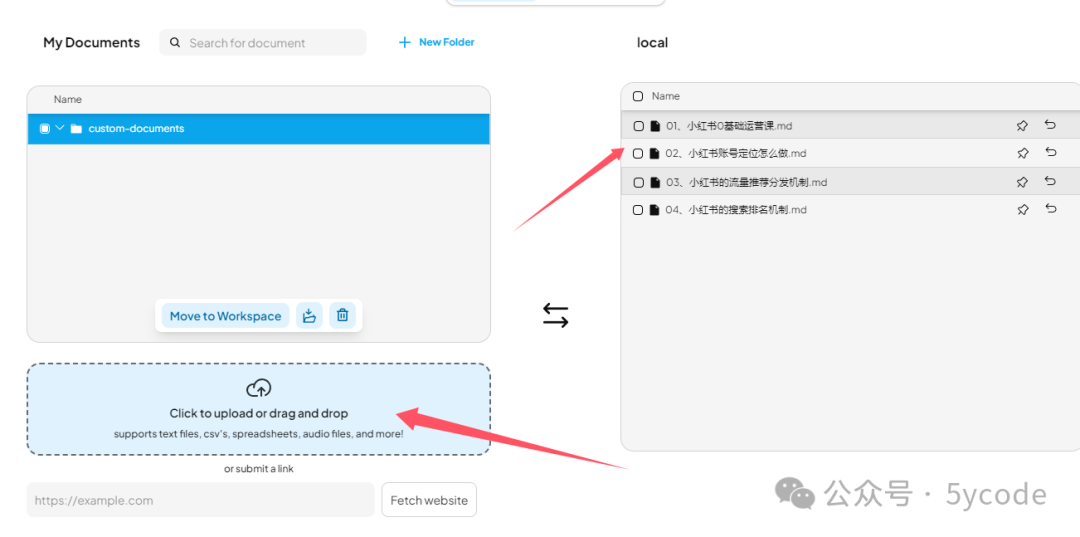
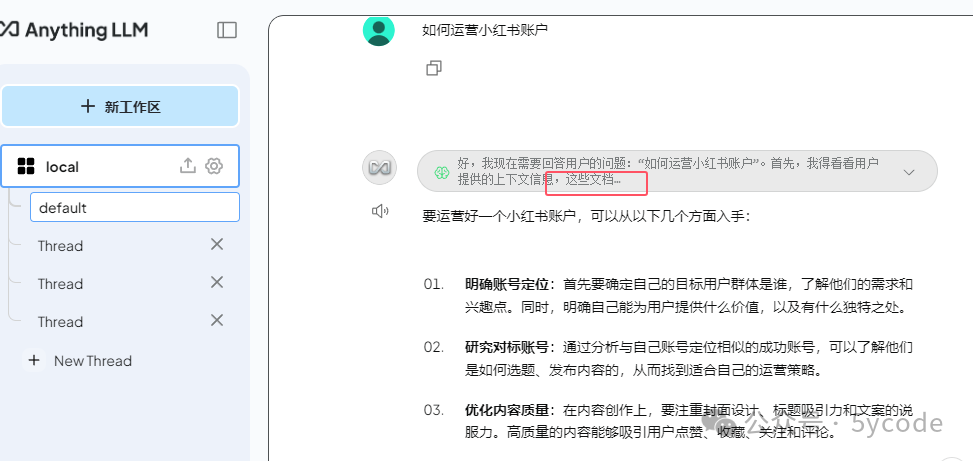
将文档拖拽到上传框。ps: 只需要拖拽一次就行了,它在聊天框能看到。不知道为什么,我这拖拽以后,没看到上传成功,然后又拖拽了几次。然后聊天框就好多份。
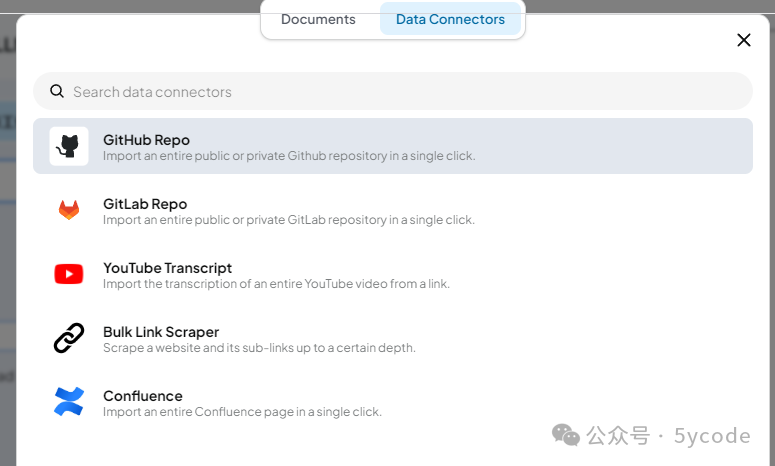
当然你可以配置远程文档,confluence、github都可以。
ps: 需要注意的是文档在工作区间内是共用的。
api功能
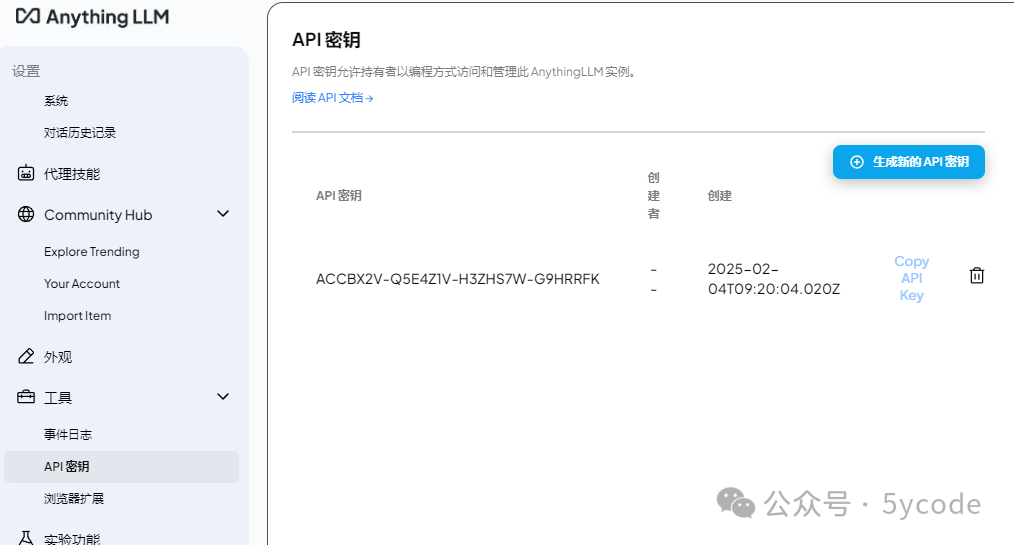
AnythingLLM 可以提供api访问的功能,这个可以作为公共知识库使用。
总结
整个操作下来,AnythingLLM 的体验没有cherry好。AnythingLLM就像一个包壳的web应用(后来查了下,确实是)。AnythingLLM 得具备一定的程序思维,给技术人员用的。非技术人员还是使用cherry吧。作为喜欢折腾的开发人员,我们可以结合dify使用。
最后
个人知识库+本地大模型的优点
- 隐私性很好,不用担心自己的资料外泄、离线可用
- 在工作和学习过程中对自己整理的文档,能快速找到,并自动关联
[外链图片转存中…(img-wGdEihxy-1746157500949)]
将文档拖拽到上传框。ps: 只需要拖拽一次就行了,它在聊天框能看到。不知道为什么,我这拖拽以后,没看到上传成功,然后又拖拽了几次。然后聊天框就好多份。
[外链图片转存中…(img-dK91Di0y-1746157500949)]
[外链图片转存中…(img-tdkfEMRp-1746157500949)]
当然你可以配置远程文档,confluence、github都可以。
[外链图片转存中…(img-9EKGlpxt-1746157500949)]
ps: 需要注意的是文档在工作区间内是共用的。
api功能
AnythingLLM 可以提供api访问的功能,这个可以作为公共知识库使用。
[外链图片转存中…(img-wq62JxmX-1746157500949)]
总结
整个操作下来,AnythingLLM 的体验没有cherry好。AnythingLLM就像一个包壳的web应用(后来查了下,确实是)。AnythingLLM 得具备一定的程序思维,给技术人员用的。非技术人员还是使用cherry吧。作为喜欢折腾的开发人员,我们可以结合dify使用。
最后
个人知识库+本地大模型的优点
- 隐私性很好,不用担心自己的资料外泄、离线可用
- 在工作和学习过程中对自己整理的文档,能快速找到,并自动关联
- 在代码开发上,能参考你的开发习惯,快速生成代码
如何学习AI大模型?
大模型的发展是当前人工智能时代科技进步的必然趋势,我们只有主动拥抱这种变化,紧跟数字化、智能化潮流,才能确保我们在激烈的竞争中立于不败之地。
那么,我们应该如何学习AI大模型?
对于零基础或者是自学者来说,学习AI大模型确实可能会感到无从下手,这时候一份完整的、系统的大模型学习路线图显得尤为重要。
它可以极大地帮助你规划学习过程、明确学习目标和步骤,从而更高效地掌握所需的知识和技能。
这里就给大家免费分享一份 2025最新版全套大模型学习路线图,路线图包括了四个等级,带大家快速高效的从基础到高级!




如果大家想领取完整的学习路线及大模型学习资料包,可以扫下方二维码获取

👉2.大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。(篇幅有限,仅展示部分)

大模型教程
👉3.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(篇幅有限,仅展示部分,公众号内领取)

电子书
👉4.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(篇幅有限,仅展示部分,公众号内领取)

大模型面试
**因篇幅有限,仅展示部分资料,需要的扫描下方二维码领取 **


















 1033
1033

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











