






自ChatGPT在2023年初掀起人工智能风暴🌪️,短短两年间,全球大模型赛道已然演变为硝烟弥漫的技术战场。当AI浪潮从概念颠覆迈向产业深耕,2025年的全球大模型生态究竟呈现出怎样的发展图景?本文将从技术突破、生态布局、区域竞争等维度,深度解析当前国内外大模型的发展现状与演进趋势!
一、国际头部阵营:技术迭代引领代际跃迁💥
以OpenAI、Google、Anthropic为核心的国际巨头,在技术创新维度持续构建代际优势:
1. *生成式AI全栈突破*
- 视觉生成:DALL·E 3与Imagen 3在图像创意领域形成双雄格局🖼️,Meta凭借免费策略快速抢占用户市场
- 音视频生成:Suno AI实现从歌词到编曲的全流程创作🎵,DeepMind的V2A技术达成视频配乐毫秒级精准匹配
- 视频生成:Runway Gen-4通过角色行为建模提升叙事连贯性🎬,Meta Movie Gen Video以30B参数实现影视级画面生成
2. *语言模型三强争霸*
- ChatGPT:OpenAI通过GPT-4.1与o3-mini-high推理引擎的协同优化,在上下文理解精度与推理效率间实现突破性平衡⚖️
- Claude:Anthropic推出的3.7 Sonnet Extended版本,凭借200K token处理能力在长文本处理领域占据领先地位📜,其代码生成准确率持续超越LMSYS基准测试
- Gemini:Google的2.5 Pro Experimental版本突破多模态交互极限,实现语音、视频、图像的实时解析🎥,其OCR与翻译能力达到业界最优水平(SOTA)
3. *开源生态新势力*
- Llama 4.0:Meta创新采用三维参数矩阵架构,在资源效率与性能表现间实现灵活平衡⚖️
- Gemma 3:DeepMind专为边缘设备优化,提供1B-27B梯度参数配置,显著降低推理能耗🔋
- Nemotron-4 340B:NVIDIA通过98%合成数据训练的超大规模模型,开创数据生成技术新范式✨
二、中国大模型:从跟跑到局部领跑的跨越式发展🏃♂️
国内AI产业实现"跟跑-并跑-局部领跑"的三级跳,在中文处理与垂直领域展现独特优势:
1. *垂直领域深度应用*
- 教育科技:字节Seed-Thinking模型首创"边搜边想"模式,提升K12知识图谱检索效率37%📖
- 智慧医疗:百川智能垂类模型在电子病历解析和影像诊断中达到专家级准确率🩺
- 文创产业:快手可图2.0实现4K超清图像生成,在国风绘画领域形成差异化优势🎨
2. *闭源模型创新突破*
- 智谱清言:ChatGLM 4.0集成RAG检索与多模态生成能力,GLM-Z1推理引擎在复杂问题解决中展现深度逻辑推理优势🧠
- 通义千问:2.5 Max版本在多项AIGC测评中超越国际竞品🏆,QvQ-Max视觉推理模型实现像素级场景理解
- 快手可灵:2.0视频生成引擎支持专业运镜术语解析🎥,在动态场景一致性生成方面达到国际领先水平
3. *开源生态蓬勃发展*
- 深度求索:DeepSeek R1推理模型在数理逻辑任务中表现卓越🧮,激活参数量优化技术降低40%资源消耗
- 智谱GLM:4.0 Plus系列提供9B-32B梯度参数选择,支持语言、视觉、视频全栈微调🎯
- 腾讯混元:Hunyuan-Large通过52B激活参数实现长文本处理优势📚,其视频生成分支在动态场景建模独具特色
三、技术与伦理的平衡木:AI治理的全球突围战🔍
在大模型技术狂飙突进的同时,数据隐私、算法偏见、内容安全等伦理问题逐渐成为行业发展的潜在风险,全球正掀起一场AI治理的突围战。
1. *法规先行:全球监管框架初现*
欧盟《人工智能法案》正式生效,将大模型按照风险等级划分为"不可接受风险"“高风险”“有限风险”"最小风险"四类,对高风险模型实施严格的合规审查🧾。美国白宫发布《人工智能权利法案蓝图》,聚焦算法透明度与数据隐私保护。中国也出台《生成式人工智能服务管理暂行办法》,建立安全评估、算法备案等制度,构建本土化AI治理体系。
2. *行业自律:企业责任边界探索*
OpenAI成立独立审查委员会,对模型输出内容进行伦理审核;Google推出AI原则与伦理委员会,从研发源头规避技术滥用风险。国内企业积极响应,百度建立AI伦理委员会,制定《百度人工智能伦理规范》;商汤科技发布《人工智能伦理白皮书》,探索算法可解释性与公平性解决方案🤝。
3. *技术赋能:伦理审查工具迭代*
Anthropic研发的宪法AI(Constitutional AI)技术,通过内置道德规则约束模型输出;DeepSeek推出的AI内容检测工具,可快速识别生成式内容中的有害信息。这些技术工具正成为平衡创新与伦理的关键抓手🔑。
四、未来趋势:从技术竞争到生态博弈🌐
当前全球AI竞争已从单一模型能力比拼,升级为"基础模型-开发工具-应用场景"的全栈生态较量:
- 竞争格局演变:国际巨头凭借先发优势与生态壁垒巩固领导地位,中国团队则在垂直领域深耕与商业化落地中形成独特竞争力💪
- 技术决胜关键:数据闭环构建速度、多模态融合创新深度、伦理框架下的技术可控性将成为未来竞争核心🔑
- 产业变革影响:这场智能革命正在重塑全球数字经济版图,推动各行业加速向智能化转型🚀
随着技术创新、伦理治理与产业应用的深度融合,全球大模型竞争已进入生态构建与价值创造的新阶段。在这场没有终点的智能革命中,谁能率先突破技术瓶颈、构建完整生态,谁就将掌握未来数字经济的发展主动权🌟!
大模型岗位需求
大模型时代,企业对人才的需求变了,AIGC相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把全套AI技术和大模型入门资料、操作变现玩法都打包整理好,希望能够真正帮助到大家。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
零基础入门AI大模型
今天贴心为大家准备好了一系列AI大模型资源,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
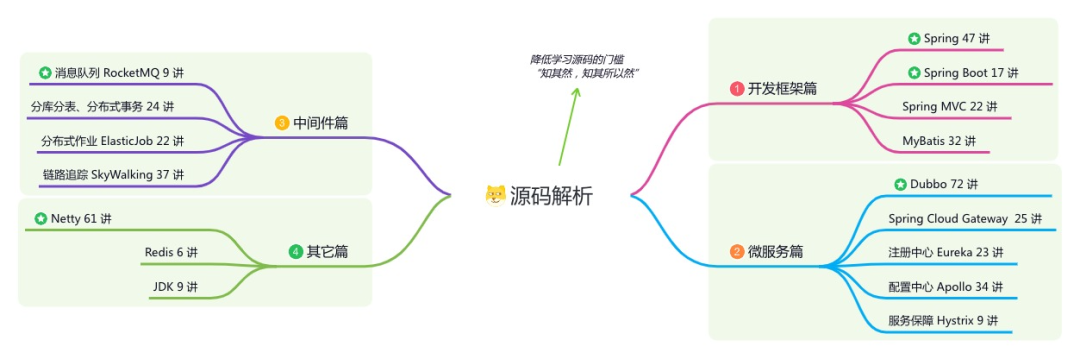
内容包括:项目实战、面试招聘、源码解析、学习路线。
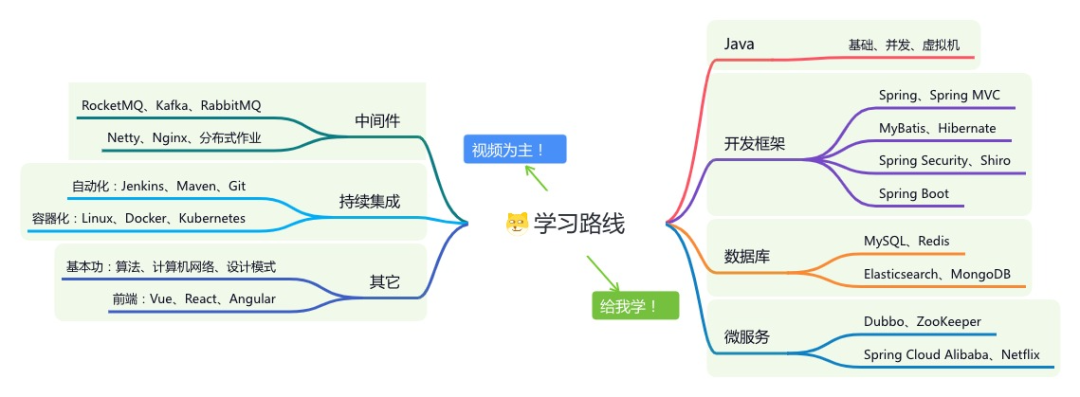
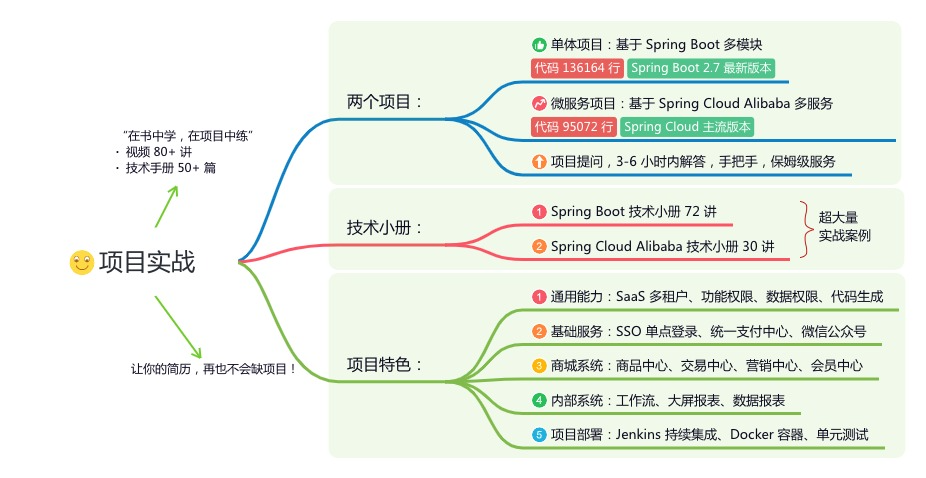
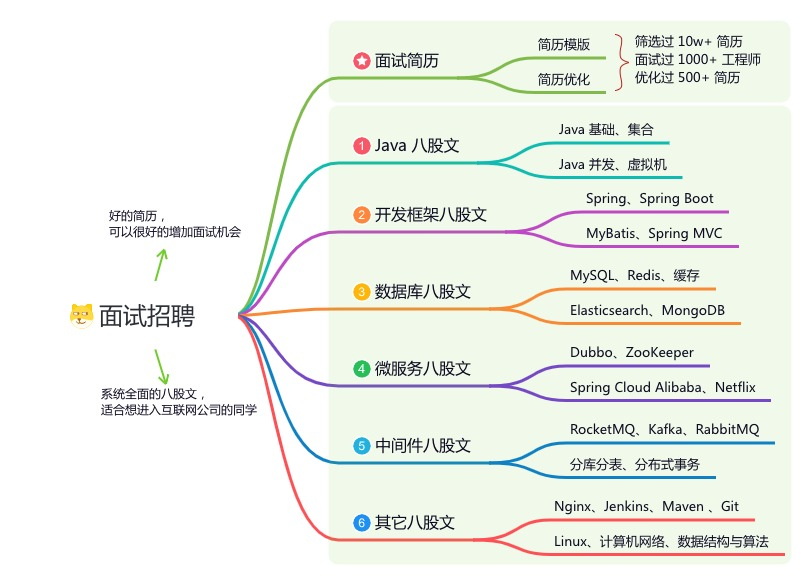
如果大家想领取完整的学习路线及大模型学习资料包,可以扫下方二维码获取

👉2.大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。(篇幅有限,仅展示部分)

大模型教程
👉3.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(篇幅有限,仅展示部分,公众号内领取)

电子书
👉4.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(篇幅有限,仅展示部分,公众号内领取)

大模型面试
**因篇幅有限,仅展示部分资料,**有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
**或扫描下方二维码领取 **


















 813
813

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











