









 本文介绍了GPU系列的不同类型,如Quadro、GeForce和Tesla,着重讲解了CUDACore、TensorCore和RTCore的功能与应用,特别是它们在深度学习和光线追踪中的优势,并提到了A100和H100等高端芯片。同时,还涉及了如何搭建深度学习所需的硬件和软件环境。
本文介绍了GPU系列的不同类型,如Quadro、GeForce和Tesla,着重讲解了CUDACore、TensorCore和RTCore的功能与应用,特别是它们在深度学习和光线追踪中的优势,并提到了A100和H100等高端芯片。同时,还涉及了如何搭建深度学习所需的硬件和软件环境。
GPU系列介绍
-
Quadro类型: Quadro系列显卡一般用于特定行业,比如设计、建筑等,图像处理专业显卡,比如CAD、Maya等软件。
-
GeForce类型: 这个系列显卡官方定位是消费级,常用来打游戏。但是它在深度学习上的表现也非常不错,很多人用来做推理、训练,单张卡的性能跟深度学习专业卡Tesla系列比起来其实差不太多,但是性价比却高很多。
-
Tesla类型: Tesla系列显卡定位并行计算,一般用于数据中心,具体点,比如用于深度学习,做训练、推理等。Tesla系列显卡针对GPU集群做了优化,像那种4卡、8卡、甚至16卡服务器,Tesla多块显卡合起来的性能不会受>很大影响,但是Geforce这种游戏卡性能损失严重,这也是Tesla主推并行计算的优势之一。
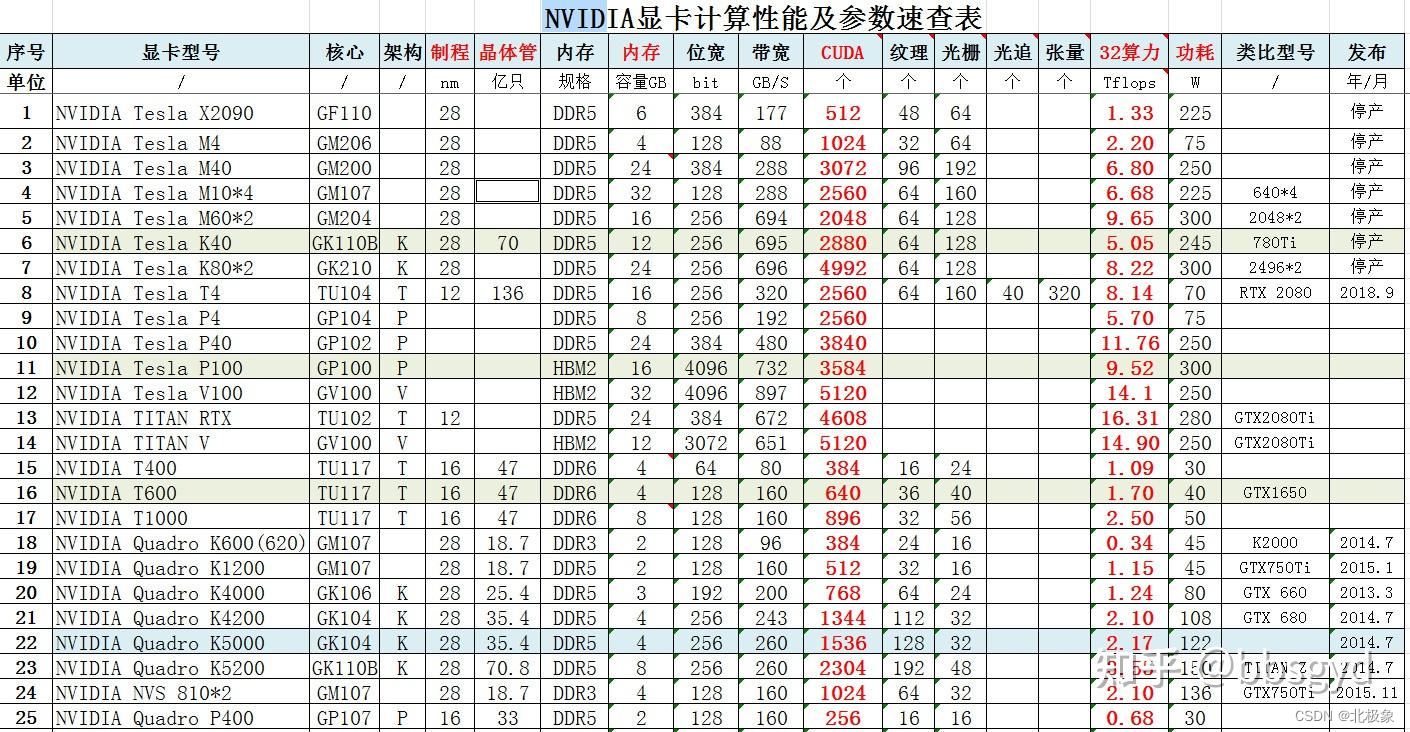
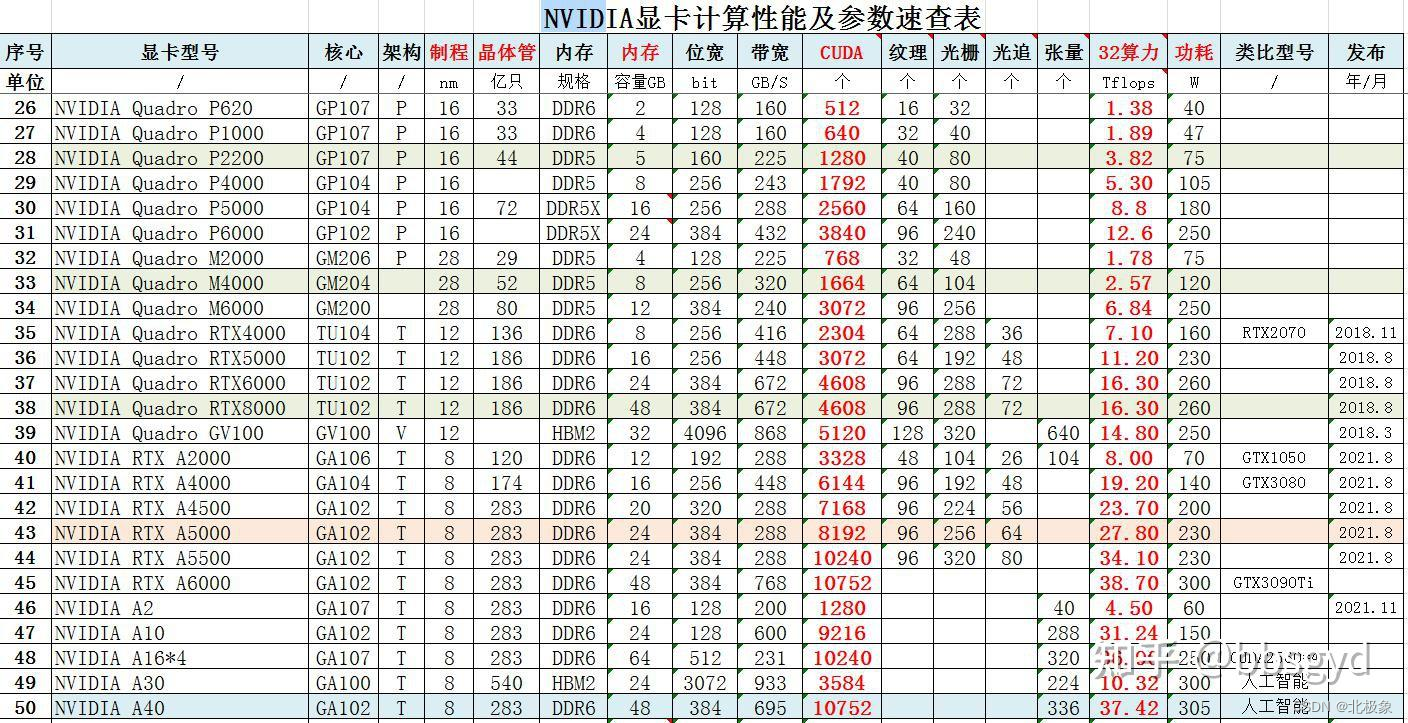
Quadro类型分为如下几个常见系列:
- NVIDIA RTX Series系列: RTX A2000、RTX A4000、RTX A4500、RTX A5000、RTX A6000
- Quadro RTX Series系列: RTX 3000、RTX 4000、RTX 5000、RTX 6000、RTX 8000
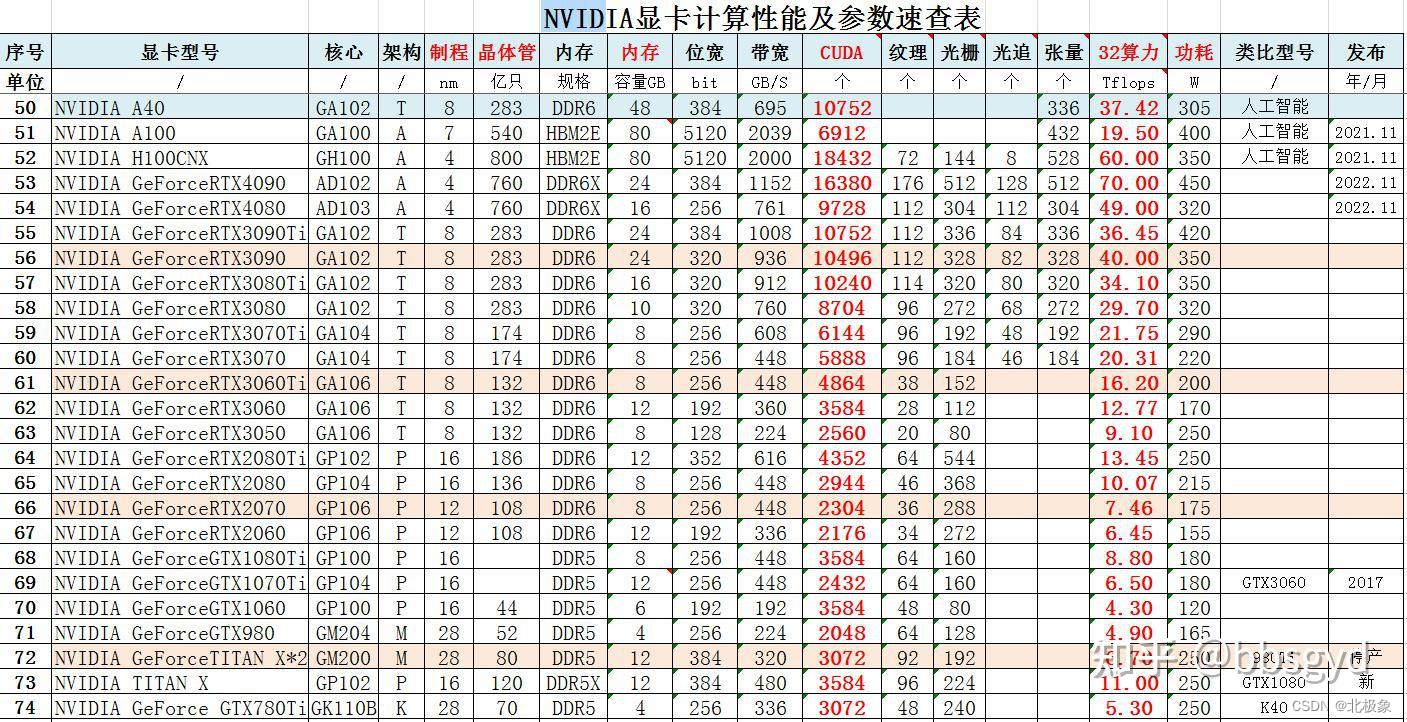
GeForce类型分为如下几个常见系列:
- Geforce 10系列: GTX 1050、GTX 1050Ti、GTX 1060、GTX 1070、GTX 1070Ti、GTX 1080、GTX 1080Ti
- Geforce 16系列:GTX 1650、GTX 1650 Super、GTX 1660、GTX 1660 Super、GTX 1660Ti
- Geforce 20系列:RTX 2060、RTX 2060 Super、RTX 2070、RTX 2070 Super、RTX 2080、RTX 2080 Super、RTX 2080Ti
- Geforce 30系列: RTX 3050、RTX 3060、RTX 3060Ti、RTX 3070、RTX 3070Ti、RTX 3080、RTX 3080Ti、RTX 3090 RTX 3090Ti
Tesla类型分为如下几个常见系列:
- A-Series系列: A10、A16、A30、A40、A100
- T-Series系列: T4
- V-Series系列: V100
- P-Series系列: P4、P6、P40、P100
- K-Series系列: K8、K10、K20c、K20s、K20m、K20Xm、K40t、K40st、K40s、K40m、K40c、K520、K80

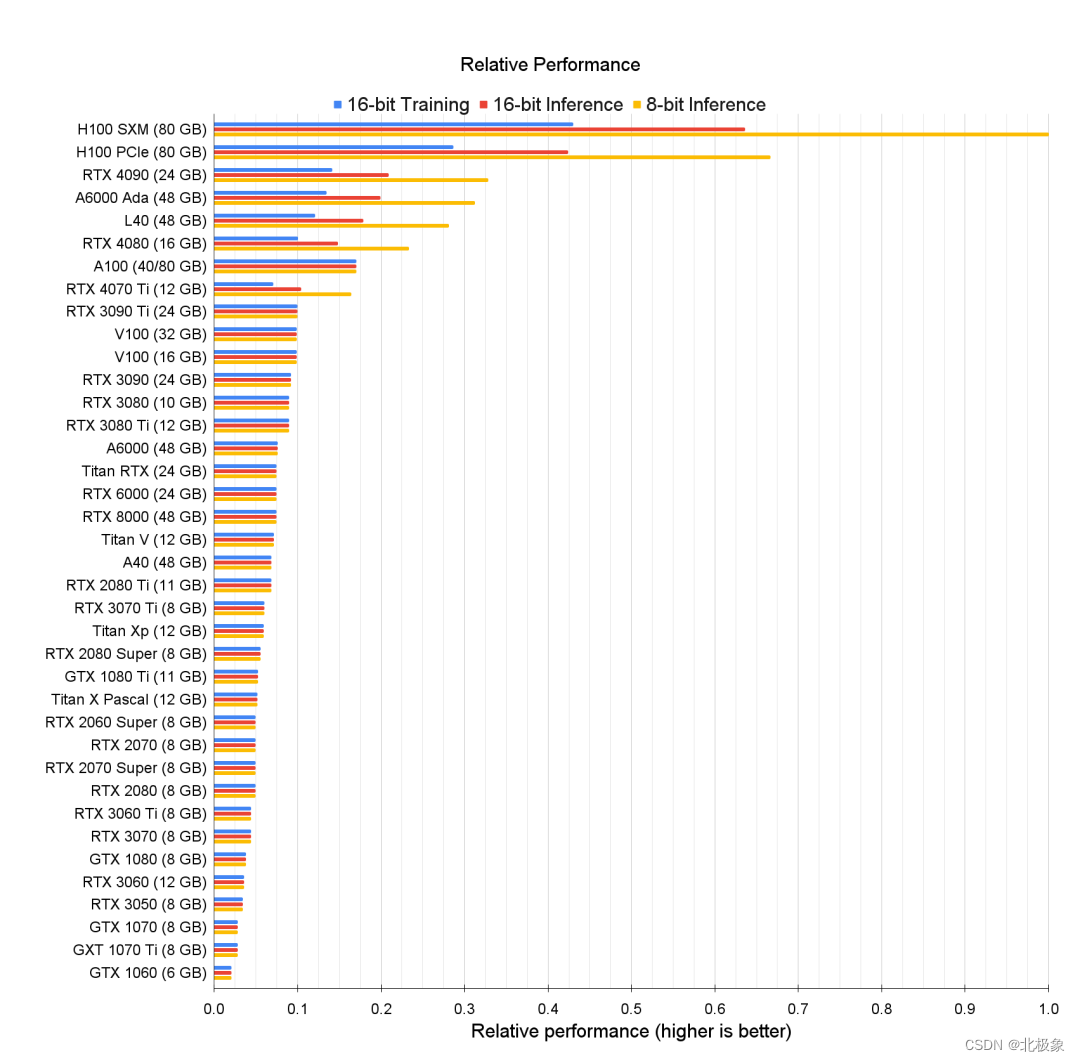
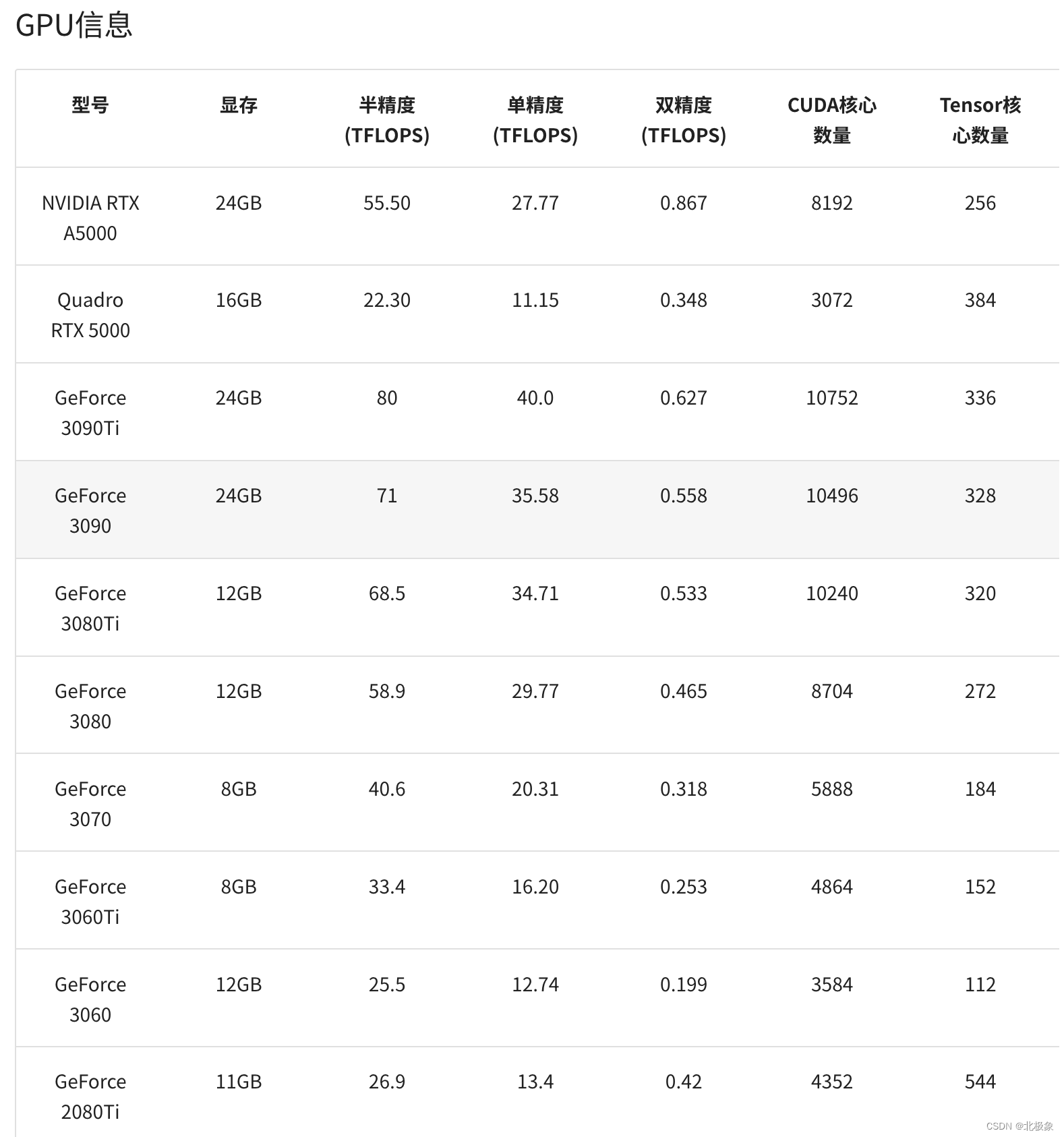
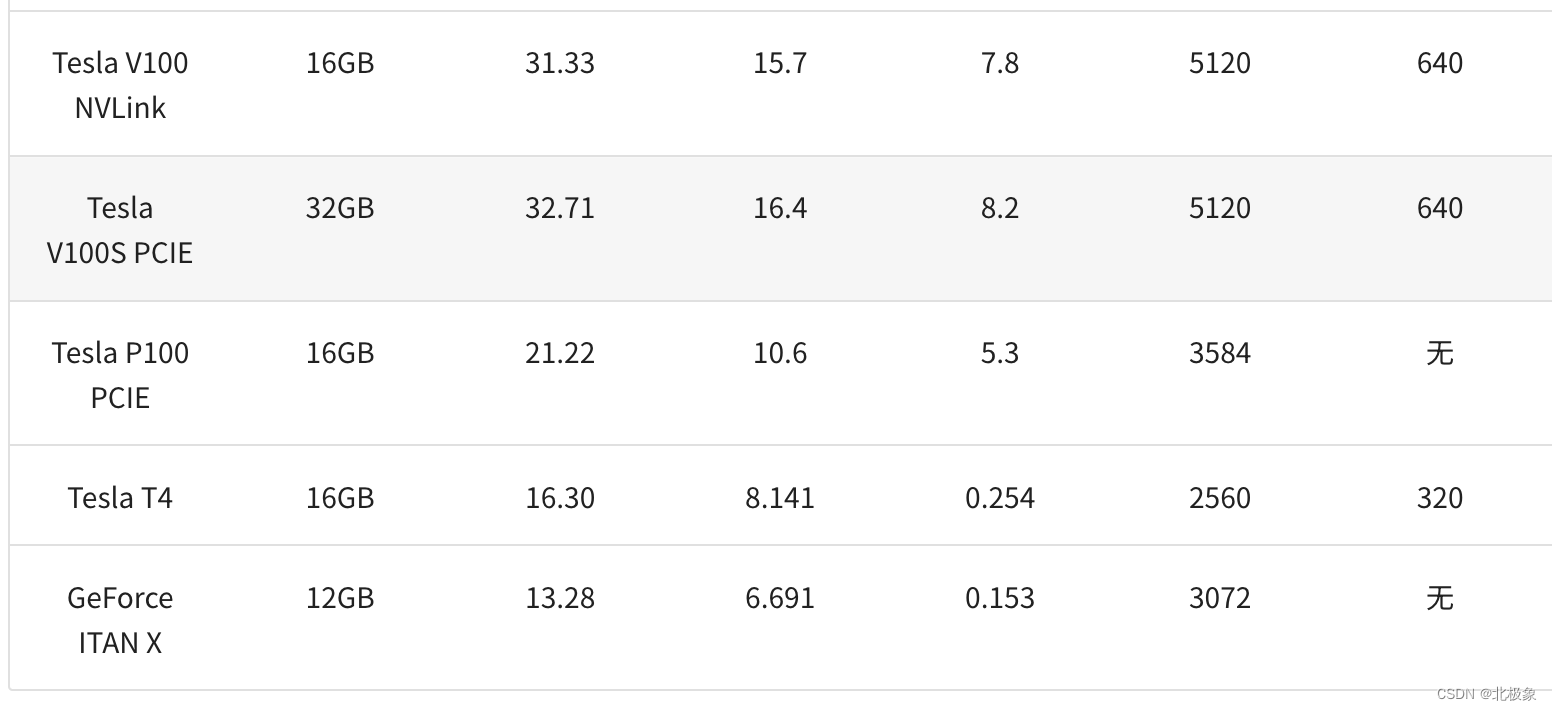
CUDA Core、Tensor Core 和 RT Core
通用的 GPU 中包含三种核心,分别是 CUDA Core、Tensor Core 和 RT Core,这三种核心各自具有不同的特性和功能。
- CUDA Core:CUDA Core 是用于通用并行计算任务的计算核心,可以执行单精度和双精度浮点运算,以及整数运算。它在处理广泛的并行计算任务方面非常高效。
- Tensor Core:Tensor Core 是针对深度学习和 AI 工作负载而设计的专用核心,可以实现混合精度计算并加速矩阵运算,尤其擅长处理半精度(FP16)和全精度(FP32)的矩阵乘法和累加操作。Tensor Core 在加速深度学习训练和推理中发挥着重要作用。
- RT Core:RT Core 是专门用于光线追踪处理的核心,能够高速进行光线和声音的渲染,对于图形渲染和光线追踪等任务具有重要意义。
其它(TODO)
少数公司从英伟达那里获得了2万多颗A100或H100 GPU。H100是英伟达最新旗舰AI芯片,价值4万美元。它的前一代是A100芯片,价值1万美元。
- RTX 3080
- RTX 2080Ti
RTX 3080,两倍于RTX 2080Ti
搭建深度学习
硬件:Intel Core i9-12900KF + 64GB + 512GB NvME + Nvidia 3080Ti显卡
操作系统:Microsoft Windows 11 Pro X64 简体中文版
针对Nvidia 3080Ti,需要安装配置 Nvidia 的机器学习环境:显卡驱动 + CUDA +cuDNN。具体


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











