







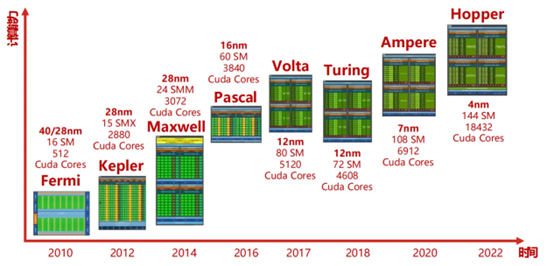
英伟达的 GPU 架构演进之路充满了创新与突破。
©作者|Zane
来源|神州问学
一、 英伟达GPU的架构演进之路
1999 年,英伟达发布 Geforce256 图形处理芯片,首次提出 GPU 概念。早期的架构如 G80 或 GeForce 8800 GTX,包含 8 个 TPC,每一个 TPC 中有两个 SM,一共有 16 个 SM。随着技术的发展,GT200 或 GeForceGTX 280 增加了 TPC 中的 SM 数量。2012 年,Kepler 架构推出,从这一架构开始,NVIDIA 以往坚持的 Core:Shader = 1:2 的分频模式消失,SM 单元中的 CUDA 核心数大幅提升,如每组 SM 单元的 CUDA 核心数从 GF100 时代的 32 个提升到了 Kepler 时代的 192 个。同时,纹理单元、前端渲染单元等也相应增加,而且核心频率达到 1GHz 以上,不再需要 Shader 异步,降低了显卡功耗。2017 年,Volta 架构引入了 Tensor Core,专门用于执行张量计算,支持并行执行 FP32 与 INT32 运算,为人工智能和机器学习工作带来了巨大的性能提升。2018 年,Turing 架构引入 RT Core,负责处理光线追踪加速。2020 年,Ampere 架构进一步提高了 FP32 着色器操作数量、RT Cores 的光线 / 三角形相交测试吞吐量,并加速稀疏神经网络处理速度。例如在完整 GA102 核心中,总共有 92 个 SM,每个 SM 包含 128 个 CUDA 核心、4 个 Tensor 核心和 1 个 RT 核心。今年,英伟达又公布了新一代 AI 芯片架构 Blackwell,集成 2080 亿颗晶体管,采用定制台积电 4NP 工艺,采用统一内存架构 + 双芯配置,共有 192GB HBM3e 内存、8TB/s 显存带宽,单卡 AI 训练算力可达 20PFLOPS,其性能堪称强大。
二、 架构演进对模型推理速度的影响

(一)计算核心的变化
首选我们需要先对GPU和CPU有一个直观的认识,如以下2张图片:
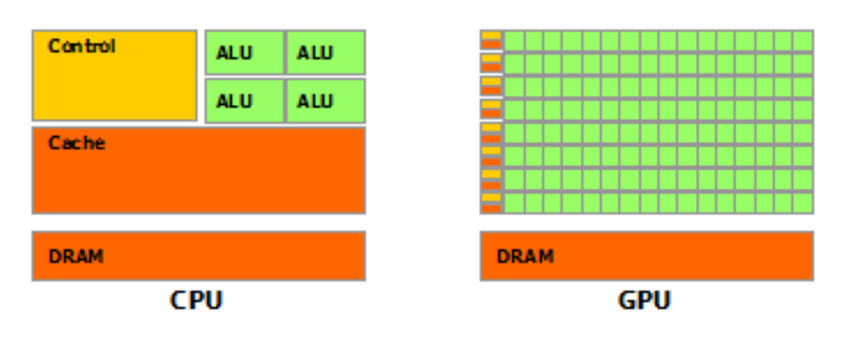
可以看到在GPU中由于存储器的发展慢与处理器,所以在CPU上发展出了多级缓存的接口,而在GPU中也存在类似的缓存接口。只是GPU中将更多的晶体管用于数值计算而不是缓存和流控制,在上边的图中可以看到GPU的Core数量要远远多于CPU,但是Cache和Control则少于CPU,这就使得GPU的单Core的自由度要远远小于CPU会收到诸多的限制,比如在一行中有多个Core却只有1个Control和1个Cache,这就代表多个Core在同一时间只能执行同样的指令这种模型被称为SIMT (Single Instruction Multiple Threads),所以从这个架构出发我们就会发现Cache和Control的缺失,只有计算密集型和数据并行的程序适合GPU。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3795
3795

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









