







Sequential模型

配置训练方法
model.compile(loss, optimizr, metrics)
- loss损失函数
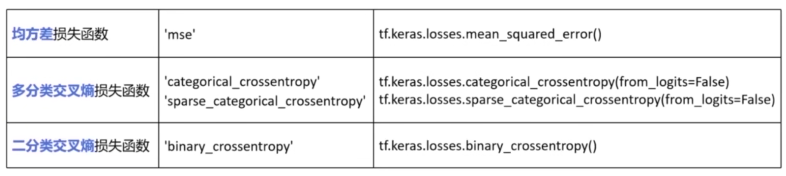
- optimizer优化器

- metrics性能评估函数
训练模型
model.fit(训练集的输入特征,训练集的标签,
batch_size=批量大小,
epochs=迭代次数,
shuffle=是否每轮训练之前打乱数据,
validation_data=(测试集的输入特征,测试集的标签),
validation_split=从训练集划分多少比例给测试集,
validation_freq =测试频率
verbose=日志显示形式
)
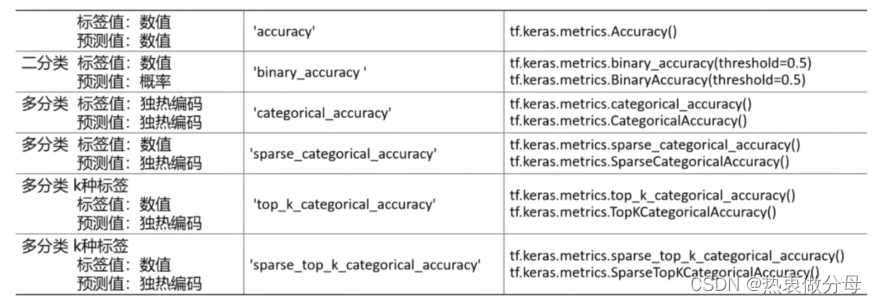
评估模型
model.evaluate(test_set_x, test_set_y, batch_size, verbose)
model.evaluate(test_set_x=测试数据属性,
test_set_y=测试数据标签,
batch_size=批量大小,
verbose=输出信息的方式
)
使用模型
model.predict(x, batch_size, verbose)
model.predict(x=数据属性值,
batch_size=批量大小,
verbose=输出信息方式
)
mnist识别
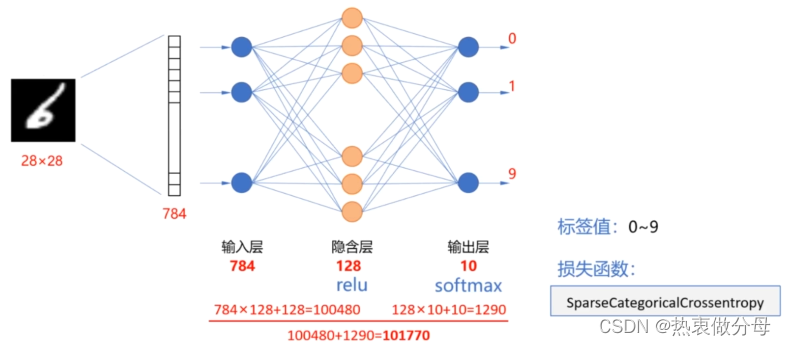
神经网络结构
程序
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
gpus = tf.config.experimental.list_physical_devices('GPU')
tf.config.experimental.set_memory_growth(gpus[0], True)
mnist = tf.keras.datasets.mnist
(train_x, train_y), (test_x, test_y) = mnist.load_data()
# 数据预处理,这一步交给后面的tf.keras.layers.Flatten()实现
# X_train = train_x.reshape(60000, 28*28)
# X_test = test_x.reshape(10000, 28*28)
X_train, X_test = tf.cast(train_x/255.0, tf.float32), tf.cast(test_x/255.0,tf.float32)
y_train, y_test = tf.cast(train_y, tf.int16), tf.cast(test_y, tf.int16)
# 建立模型
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28, 28))) # 数据拉直预处理
model.add(tf.keras.layers.Dense(128, activation="relu"))
model.add(tf.keras.layers.Dense(10, activation="softmax"))
model.summary() # 查看模型结构
# 配置训练方法
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['sparse_categorical_accuracy'])
# 训练模型
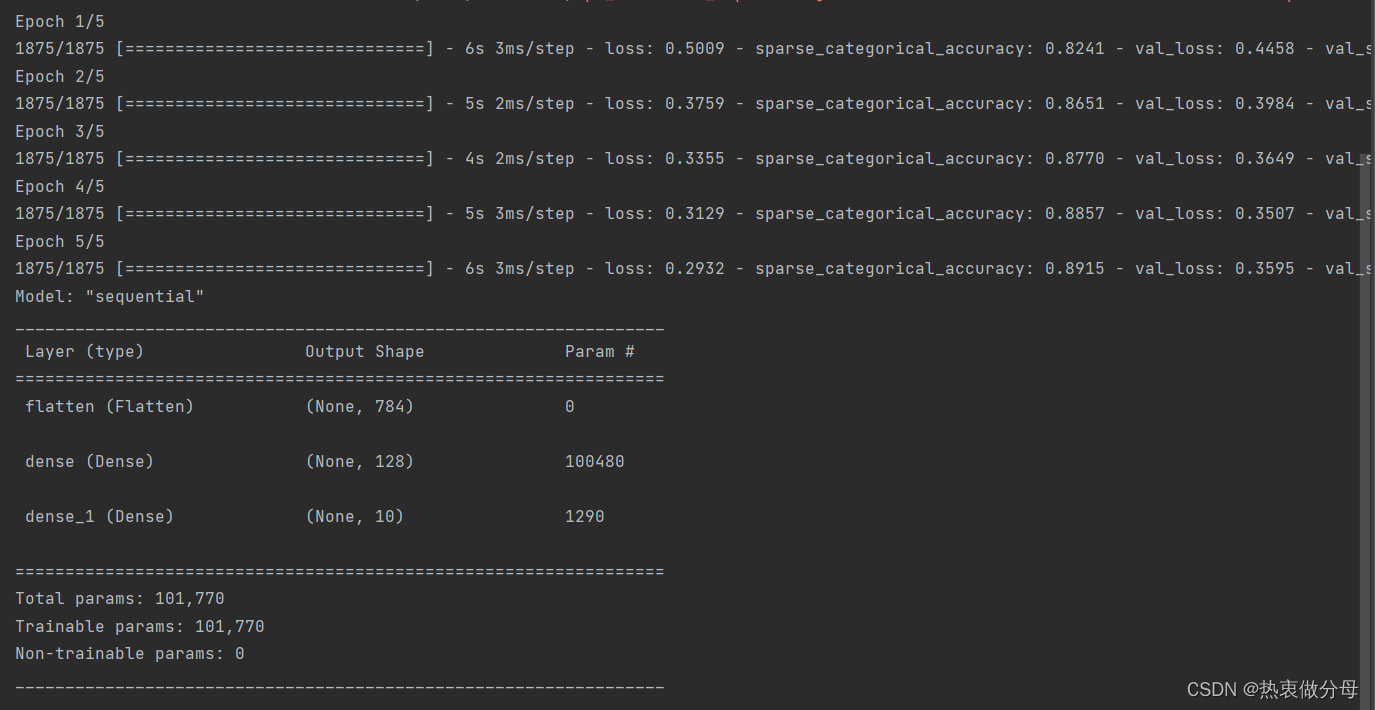
model.fit(X_train, y_train, batch_size=64, epochs=5, validation_split=0.2)
# 评估模型
model.evaluate(X_test, y_test, verbose=2)
# 使用模型--测试集中前四个数据
result = np.argmax(model.predict(X_test[0:4]), axis=1)
for i in range(4):
plt.subplot(1, 4, i+1)
plt.axis("off")
plt.imshow(test_x[i], cmap='gray')
plt.title(str(test_y[i])+"\npred:"+str(result[i]))
plt.show()
结果


fashion数据集识别
程序
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
fashion = tf.keras.datasets.fashion_mnist
(x_train, y_train), (x_test, y_test) = fashion.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1)
model.summary()
# 使用模型--测试集中前四个数据
result = np.argmax(model.predict(x_test[0:4]), axis=1)
for i in range(4):
plt.subplot(1, 4, i+1)
plt.axis("off")
plt.imshow(x_test[i], cmap='gray')
plt.title(str(y_test[i])+"\npred:"+str(result[i]))
plt.show()
结果















 217
217











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









