







在上节课,

目标:使用 Sequential 模型实现对 MNIST 手写数字数据集的识别

步骤一:设置神经网络结构
MNIST 手写数字数据集中的每个样本图片都是 28 x 28 的,在使用图片作为神经网络的输入时,通常把它拉成一个一维张量后,再送入神经网络。
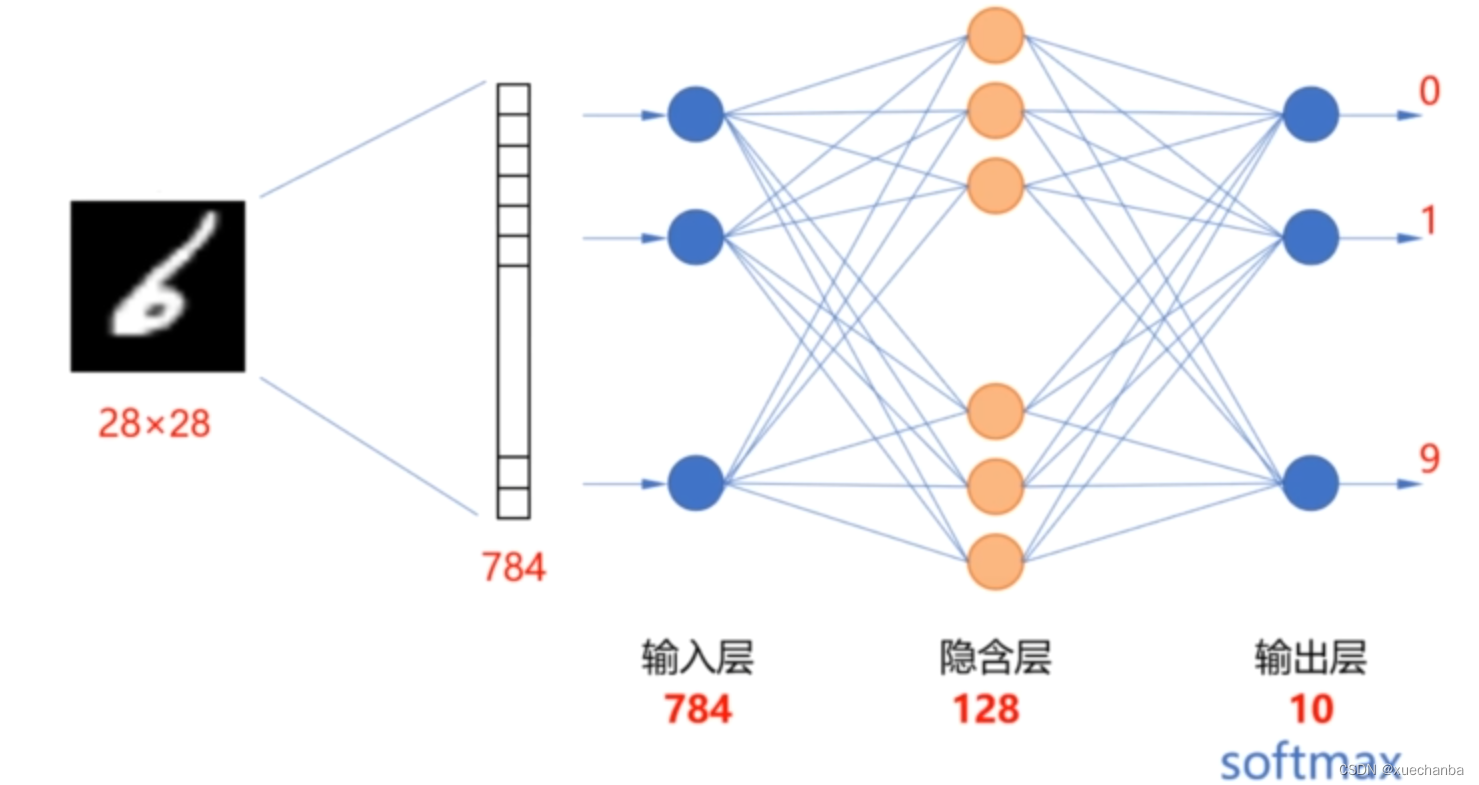
因此,输入层中有 784 个结点,我们使用一个隐含层的全连接网络来实现手写数字数据集的识别。这些数字从 0 到 9,分为10类,因此输出层中有 10 个神经元。分别是当前图片属于每个数字的概率。因此这是一个多分类任务,从而输出层使用 softmax 函数作为激活函数,隐含层我们设计128个神经元,使用 relu 函数作为激活函数。
在 Mnist 数据集中,标签是 0~9的数字,

在前面鸢尾花数据集的分类中,我们首先是把这种自然顺序码形式的标签值转换为独热编码的形式,然后再使用交叉熵损失函数来计算损失。其实,在 tf.keras 中提供了稀疏交叉熵损失函数,

因此可以直接使用这种数值形式的标签值来计算损失,而无需把它转化为独热编码的形式再进行处理 。
在这个数据集中,输入层和隐含层之间有 784 x 128 个权值和 128 个阈值,一共

个参数。
在隐含层和输出层之间有 128 x 10 个权值和 10 个阈值,一共

个参数。因此,在这个神经网络中,一共有

个参数。
下面,我们就开始使用 Sequential 模型来编程实现这个神经网络。
步骤二:编程实现
# 一:导入库函数
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
# 二:参数配置
# 图片显示中文字体的配置
plt.rcParams["font.family"] = "SimHei", "sans-serif"
# GPU显存的分配配置
gpus = tf.config.experimental.list_physical_devices('GPU')
tf.config.experimental.set_memory_growth(gpus[0], True)
# 三:加载数据
mnist = tf.keras.datasets.mnist
(train_x, train_y), (test_x, test_y) = mnist.load_data()
print(train_x.shape) # (60000, 28, 28)
# 每条数据的属性就是图片中各个像素的灰度值, 存放在一个 28 * 28 的二维数组中
print(train_y.shape) # (60000,)
print(test_x.shape) # (10000, 28, 28)
print(test_y.shape) # (10000,)
print(type(train_x), type(train_x))
# <class 'numpy.ndarray'> <class 'numpy.ndarray'>
# 每条数据的属性就是图片中各个像素的灰度值, 存放在一个
print(type(test_x), type(test_y))
# <class 'numpy.ndarray'> <class 'numpy.ndarray'>
print((train_x.min(), train_x.max()))
print((test_y.min(), test_y.max()))
# 每个元素的灰度值在(0, 255)之间
# 数据的标签值在(0, 9)之间
# 四:数据预处理
"""
# 在输入神经网络时, 需要把每条数据的属性从 28 * 28 的二维数组转化为长度为 784 的一维数组
# 可以使用 reshape 方法进行转换
X_train = train_x.reshape((60000, 28*28))
X_test = test_x.reshape((10000, 28*28))
print(X_train.shape)
print(X_test.shape)
# 但是这一步也可以省略, 在这里保持输入数据的形状不变,
# 在后面创建神经网络时增加一个 Flatten() 层来实现输入数据维度的变化.(通过 tf.keras.layers.Flatten()函数来实现)
"""
# 为了加快迭代速度, 还要对属性进行归一化, 使其取值范围在 (0, 1)之间
# 与此同时, 把它转换为Tensor张量, 数据类型是 32 位的浮点数.
# 把标签值也转换为Tensor张量,数据类型是 8 位的整型数.
X_train, X_test = tf.cast(train_x / 255.0, tf.float32), tf.cast(test_x / 255.0, tf.float32)
y_train, y_test = tf.cast(train_y, tf.int16), tf.cast(test_y, tf.int16)
# 现在, 数据已经准备好了, 可以搭建模型了
# 五:搭建模型
# 在之前, 都是使用低阶 API 来训练和测试模型, 在这里直接使用 tf.keras.Sequential 来建立和训练模型
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28, 28)))
# 这里首先添加一个 Flatten 层, 说明输入层的形状, Flatten 层不进行计算, 只是完成形状转换, 把输入的属性拉直, 变成一维数组
# 这样在数据预处理阶段, 不用改变输入数据的形状, 隐含层中也不用再说明输入数据, 各层的结构更加清晰
model.add(tf.keras.layers.Dense(128, activation="relu"))
# 这里再添加隐含层, 隐含层是全连接层, 其中有 128 个结点, 激活函数采用 relu 函数
model.add(tf.keras.layers.Dense(10, activation="softmax"))
# 最后, 添加输出层, 输出层也是全连接层, 其中有 10 个结点, 激活函数采用 softmax 函数
# 六:查看模型结构和信息
# 下面使用 summary() 方法来查看模型结构和参数信息
print(model.summary())
"""
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 784) 0 可以看出输入层中共 784 个结点, 没有参数
_________________________________________________________________
dense (Dense) (None, 128) 100480 可以看出隐含层中共 128 个结点, 100480个参数
_________________________________________________________________
dense_1 (Dense) (None, 10) 1290 可以看出输出层中共有 10 个结点, 1290个参数
=================================================================
Total params: 101,770 所有参数为 101770 , 和前面计算的结果一致
Trainable params: 101,770 可训练参数为 101770
Non-trainable params: 0
_________________________________________________________________
None
"""
# 七:配置模型的训练方法
model.compile(loss='sparse_categorical_crossentropy',
# 损失函数使用稀疏交叉熵损失函数,
optimizer='adam', # 这里可以不用设置 adam 算法中的参数,
# 因为 keras 中已经使用常用的公开参数作为他们的默认值
# 在大多数情况下都可以得到比较好的结果
metrics=['sparse_categorical_accuracy'] # 在 mnist 手写数字数据集中
# 标签值是 0 ~ 9 的数字, 而神经网络的输出是一组概率分布, 类似独热编码的形式
# 所以使用稀疏准确率评价函数
)
# 八:训练模型
model.fit(X_train, y_train, batch_size=64, epochs=5, validation_split=0.2)
"""
750/750 [==============================] - 2s 2ms/step - loss: 0.3316 - sparse_categorical_accuracy: 0.9080
- val_loss: 0.1854 - val_sparse_categorical_accuracy: 0.9490
Epoch 2/5
750/750 [==============================] - 1s 2ms/step - loss: 0.1542 - sparse_categorical_accuracy: 0.9557
- val_loss: 0.1362 - val_sparse_categorical_accuracy: 0.9625
Epoch 3/5
750/750 [==============================] - 1s 2ms/step - loss: 0.1083 - sparse_categorical_accuracy: 0.9684
- val_loss: 0.1133 - val_sparse_categorical_accuracy: 0.9662
Epoch 4/5
750/750 [==============================] - 1s 2ms/step - loss: 0.0816 - sparse_categorical_accuracy: 0.9764
- val_loss: 0.1070 - val_sparse_categorical_accuracy: 0.9683
Epoch 5/5
750/750 [==============================] - 1s 2ms/step - loss: 0.0640 - sparse_categorical_accuracy: 0.9817
- val_loss: 0.0891 - val_sparse_categorical_accuracy: 0.9740
48000 / 64 = 750,由于批次中的数据元素是随机的,所以每次运行的结果都不同,但相差不大
"""
# 九:评估模型
# 这里使用 mnist 本身的测试集来评估模型
# verbose=2 表示输出进度条进度
model.evaluate(X_test, y_test, batch_size=64, verbose=2)
"""
157/157 - 0s - loss: 0.0831 - sparse_categorical_accuracy: 0.9753
可以看出评估结果和训练结束时差不多, 说明模型具备比较好的泛化能力
"""
print(model.predict(tf.reshape(X_test[0], (1, 28, 28))))
"""
[[1.0715038e-06 1.0324411e-08 4.6169051e-05 3.1649109e-03 2.5737654e-09
1.0182708e-05 3.5060754e-10 9.9673718e-01 7.0867241e-06 3.3317392e-05]]
"""
print(np.argmax(model.predict(tf.reshape(X_test[0], (1, 28, 28))))) # 7
print(model.predict(X_test[0:1]))
"""
[[1.0715038e-06 1.0324411e-08 4.6169051e-05 3.1649109e-03 2.5737654e-09
1.0182708e-05 3.5060754e-10 9.9673718e-01 7.0867241e-06 3.3317392e-05]]
"""
print(np.argmax(model.predict(X_test[0:1]))) # 7
# 十:应用模型
print(model.predict(X_test[0:4]))
"""
[[1.07150379e-06 1.03244107e-08 4.61690943e-05 3.16491537e-03
2.57376542e-09 1.01827382e-05 3.50607543e-10 9.96737182e-01
7.08673088e-06 3.33174248e-05] 7
[3.35424943e-07 1.12591035e-04 9.99805272e-01 7.68335231e-05
4.28767265e-14 2.12541249e-06 6.02013586e-07 3.72865123e-13
2.21275559e-06 1.86290827e-11] 2
[5.71592282e-05 9.90575433e-01 1.31425296e-03 3.72505921e-04
5.41845860e-04 1.76171481e-04 6.35534816e-04 4.01782431e-03
2.23736092e-03 7.18673400e-05] 1
[9.99535441e-01 1.98488053e-08 8.39202767e-05 4.44717125e-06
4.52212788e-07 1.29147578e-04 2.16145389e-04 5.45915918e-06
1.63960962e-07 2.48363776e-05]] 0
一方面是因为神经网络的损失函数是一个复杂的非凸函数,使用梯度下降法只能是尽可能的去逼近全局最小值点,另一方面由于每次训练时批次中的数据元素是随机的, 到达最小值点的路径也不同,所以每次运行的结果都不同, 但相差不大。
"""
# axis=1 表示对每一行元素求最大索引
y_pred = np.argmax(model.predict(X_test[0:4]), axis=1)
print(y_pred) # [7 2 1 0]
# 下面取出测试集中的前4个数据进行识别
plt.figure()
for i in range(4):
plt.subplot(1, 4, i+1)
plt.axis("off")
plt.imshow(test_x[i], cmap="gray") # cmap="gray"表示绘制的是灰度图
plt.title("y= "+str(test_y[i]) + "\n" + "y_pred=" + str(y_pred[i]))
plt.suptitle("取出测试集中的前4个数据进行识别", fontsize=20, color="red", backgroundcolor="yellow")
# 下面再随机取出测试集中的任意4个数据进行识别
plt.figure()
for i in range(4):
num = np.random.randint(1, 10000)
plt.subplot(1, 4, i+1)
plt.axis("off")
plt.imshow(test_x[num], cmap="gray")
y_pred = np.argmax(model.predict(tf.reshape(X_test[num], (1, 28, 28))))
plt.title("y= "+str(test_y[num]) + "\n" + "y_pred=" + str(y_pred))
plt.suptitle("随机取出测试集中的任意4个数据进行识别", fontsize=20, color="red", backgroundcolor="yellow")
plt.show()
最后预测图和结果如下:


遇到几个问题如下:
1、报错
WARNING:tensorflow:Model was constructed with shape (None, 28, 28) for input KerasTensor(type_spec=TensorSpec(shape=(None, 28, 28), dtype=tf.float32, name='flatten_input'), name='flatten_input', description="created by layer 'flatten_input'"), but it was called on an input with incompatible shape (None, 28).
Traceback (most recent call last):
File "E:\projectCode\PycharmProjects\tensorflowProject\hello_tensorflow.py", line 174, in <module>
y_pred = np.argmax(model.predict([[X_test[num]]]))
解决方法:
y_pred = np.argmax(model.predict(tf.reshape(X_test[0], (1, 28, 28))))
2、GPU 可能不能用,代码跑不下去。
(PyCharm 运行成功一次后就扔在那了,一直不用GPU跑代码了,过一段时间再运行,可能就出现这个问题),
failed to create cublas handle: CUBLAS_STATUS_NOT_INITIALIZED
程序中也设置了 GPU 显存的分配配置,
gpus = tf.config.experimental.list_physical_devices('GPU')
tf.config.experimental.set_memory_growth(gpus[0], True)
思考可能的原因,
1、排除是否程序中代码确实写错了(如果之前运行好好的,突然不能运行了,就跳到第二步)。
2、我倾向于这篇文章 https://blog.csdn.net/heenim33/article/details/106524802/ 中所说的资源冲突。
解决方法:反复确认是否是代码有问题,然后,关闭 PyCharm ,等待一会,再重新运行试试。















 2981
2981











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











