






kmeans算法实现聚类
编程平台matlab,.m文件
ID:8539732235951405
画花生姜
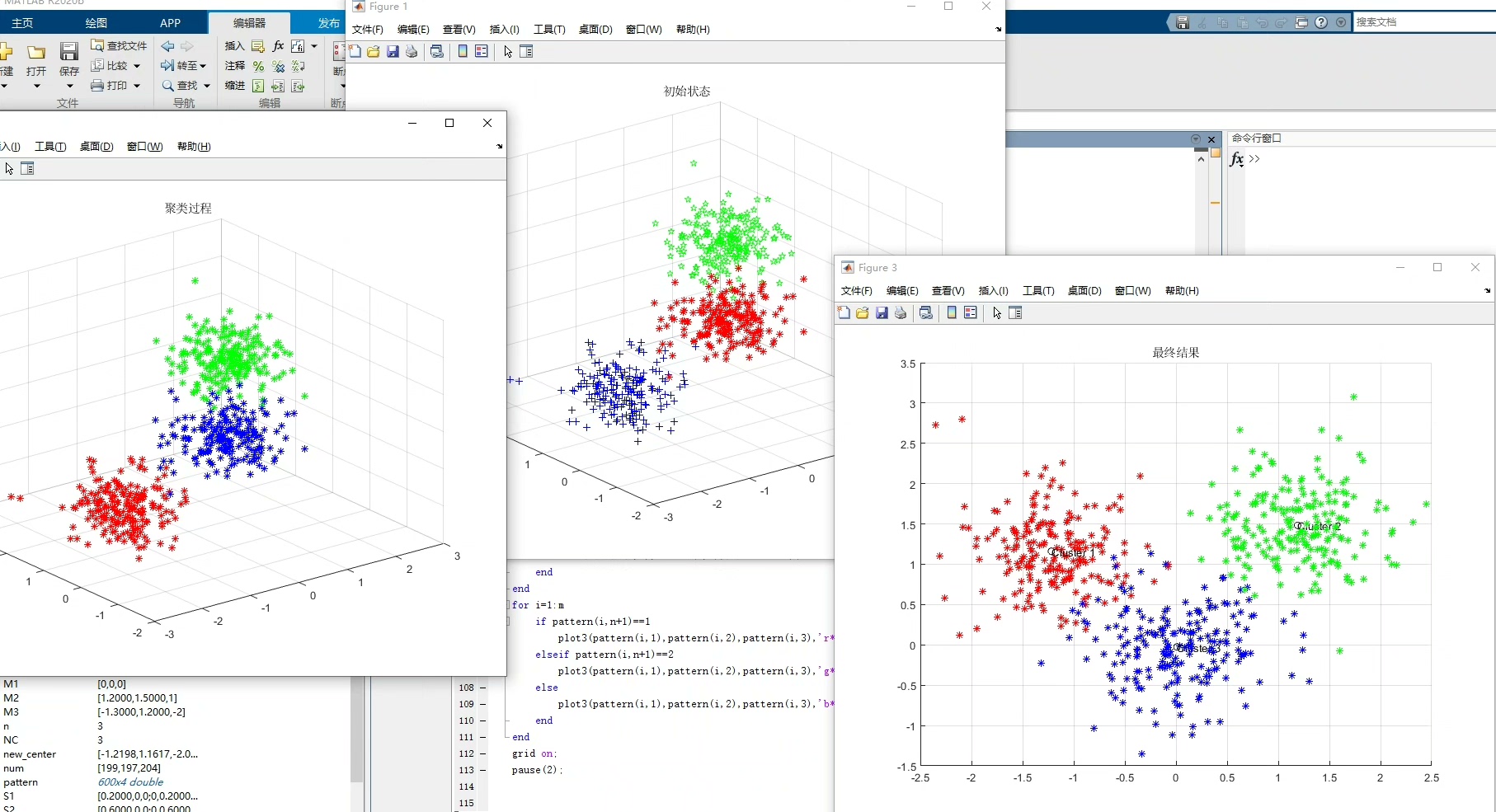
K-means算法是一种常用的聚类算法,它基于样本间的距离来将数据分为k个类别。在本文中,我们将探讨如何使用Matlab编程平台实现K-means算法,并通过编写.m文件来实现聚类。
首先,让我们简要介绍一下K-means算法的原理。K-means算法的目标是将数据分为k个不同的类别,使得同一类别内的样本间距离较小,而不同类别之间的样本间距离较大。该算法的步骤如下:
- 初始化k个聚类中心,可以随机选择数据点作为初始中心。
- 将每个数据点分配到最近的聚类中心。
- 更新聚类中心位置,将每个聚类中心设置为该聚类内所有数据点的平均值。
- 重复步骤2和步骤3,直到聚类中心不再变化或达到最大迭代次数。
在Matlab中,我们可以通过编写.m文件来实现K-means算法。首先,我们需要定义一些函数来计算数据点之间的距离和更新聚类中心的位置。例如,我们可以使用欧几里得距离来计算两个数据点之间的距离,并使用平均值来更新聚类中心的位置。
接下来,我们可以编写主函数来实现K-means算法的整个过程。在主函数中,我们可以读取输入数据集,并初始化聚类中心。然后,我们可以通过迭代的方式将每个数据点分配到最近的聚类中心,并更新聚类中心的位置。最后,我们可以输出聚类结果并进行可视化。
在编写代码时,我们还可以添加一些优化措施来提高算法的性能。例如,可以使用矩阵运算来加速距离计算的过程,或者使用动态更新的方式来选择初始聚类中心。
总结起来,本文介绍了如何使用Matlab编程平台实现K-means算法进行聚类。我们通过编写.m文件来实现算法的各个步骤,并讨论了一些优化措施。希望本文能够为读者提供一个清晰的指导,使他们能够在实际应用中正确使用K-means算法进行聚类分析。
这篇文章主要围绕K-means算法的实现展开,介绍了算法的原理和步骤,并使用Matlab编程平台实现了该算法。通过编写.m文件,我们可以实现数据的聚类,并输出聚类结果。同时,我们还讨论了一些优化措施,以提高算法的性能。希望本文能够帮助读者深入了解K-means算法,并在实际应用中发挥其优势。
以上相关代码,程序地址:http://wekup.cn/732235951405.html















 1490
1490











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









