






先放参考链接:http://blog.csdn.net/u012931582/article/details/70314859
首先,u-net的网络结构:
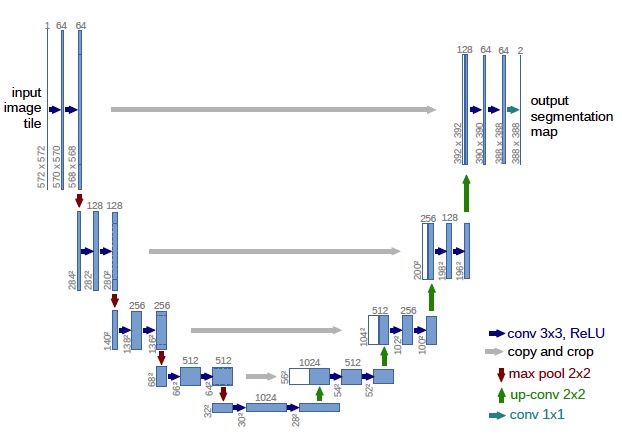
可以看到,输入图像尺寸是大于输出图像的。
u-net一个比较“创新”做法在于:在对图像边界进行padding时,用的不是传统的补零,而是对边缘部分镜像!:
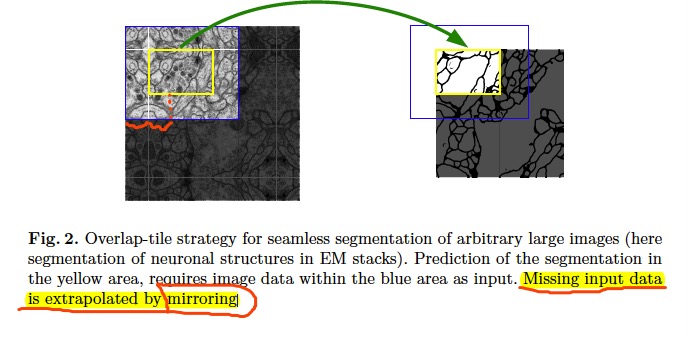
u-net的拓展:
数据增强:移动最小二乘实现图像数据增强(有时间自己可以写代码实现一下。。。)
论文名称: Image Deformation Using Moving Least Squares


还有个segnet,
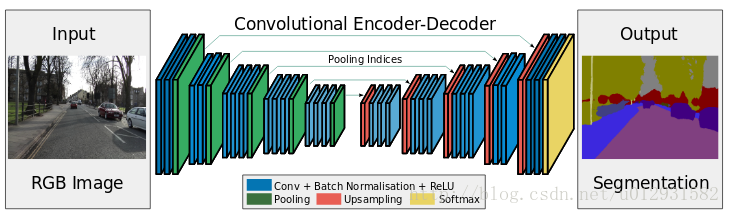
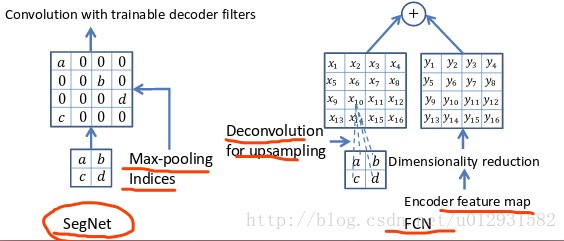
结构很对称,前部分和普通的vgg19一致。创新之处在于,它的pooling都会记住pooling indices(粗暴点讲就是max pooling时候,会记住max值的坐标位置)。所以在后半部分upsample的时候,操作是:把pooling得到的max值放回之前本身的对应坐标位置,其他位置的值全置0.

这篇写的比较水啊,有新理解会来补充的。。。。。















 3639
3639

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









