







摘要
这个神经网络有60 million 个参数,650000个神经元,5个卷积层,3个全连接层,最后一个全连接层输入到一个1000waysoftmax分类器中,产生1000个分类类别。
为了加快训练速度,使用了非饱和神经元和两个GPU。
为了减少过度拟合,在全连接层中使用 dropout。
CNNs架构
(1)非线性的ReLU

采用非线性的非饱和ReLU激活函数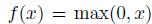
(2)多个GPUs
(补充:GPU是显卡的心脏,相当与CPU在电脑中的作用,它决定了显卡的档次和绝大多数性能)
在本实验中,使用2个GPU。
(3)局部相应正则化
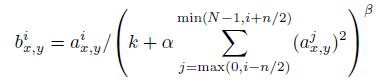
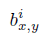
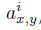
(4)重叠下采样层
(补充:下采样层一般放在卷积层后面,因为下采样就是为了减少卷积过后产生的特征向量,而重叠下采样层就是相邻下采样窗口之间会有重叠区域。此时要求size X> stride )。在本实验中下采样窗口大小size为3*3,相邻下采样窗口的水平位移/垂直位移stride为2。
重叠下采样层,有利于减少过度拟合。
(5)CNNs总体结构框架(重头戏来了)
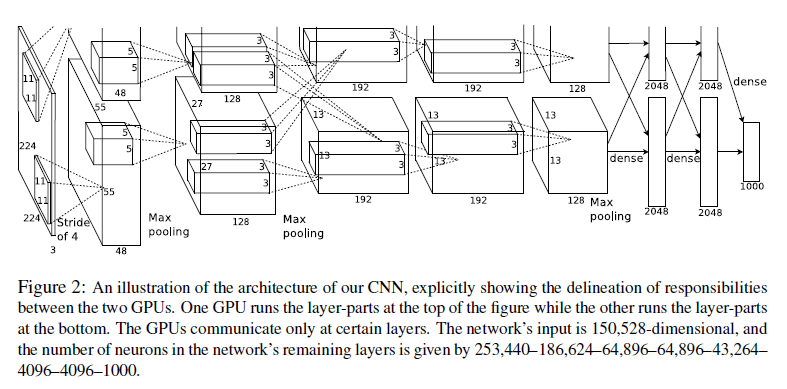
(在对这个有名的网络结构分析之前,我先给大家科普一下convolution过程:
假设有一个r*c大小的输入图像,然后从中抽取了a*b大小的图像样本,其实这也相当于我们卷积层里卷积核的大小,然后呢,让这个图像样本去卷积这个输入图像,假设这里存在k个特征,也就相当于k个卷积核个数,那么卷积过后得到的特征矩阵大小就为(r-a+1)*(c-b+1)*k,如果在卷积层后面还加了pooling层,那最终得到的特征矩阵大小另当别论。这跟pooling的层数有关。)
存在两个GPUs,一个负责图中的上一层,另一个负责图中的下一层。整个CNN有8层,5个卷积层,3个全连接层,下面对每层单独分析:
(1)前五层卷积层
第一层: 与224*224的输入图像连接,3个通道。96个卷积核,每个GPU上48个,卷积核大小为11*11*3,滑动窗口滑动位移为4个像素,采用ReLU激活函数进行卷积,卷积后进行重叠下采样处理,最后还要局部正则化。
第二层:第一层的输出作为第二层的输入,(卷积时,只卷积同一个GPU的前一层的48个特征映射层)256个卷积核,每个GPU上128个,卷积窗口大小为5*5*48,采用ReLU激活函数进行卷积,卷积后进行重叠下采样处理,最后还要局部正则化。
第三层:第二层的输出作为第三层的输入,(卷积时,卷积前一层两个GPU上所有256个特征映射层)384个卷积核,每个GPU上192个,卷积窗口大小为(3*3*128)*2,采用ReLU激活函数进行卷积.
第四层:(卷积时,只卷积同一个GPU的前一层的192个特征映射层)384个卷积核,每个GPU上192个,卷积窗口大小为3*3*192,采用ReLU激活函数进行卷积。
第五层:(卷积时,只卷积同一个GPU的前一层的192个特征映射层)256个卷积核,卷积窗口大小为3*3*192,采用ReLU激活函数进行卷积,后面重叠下采样处理。
(2)下面进入全连接层
第六层,第五层下采样处理后的输出作为第六层的输入,4096个神经元。
第七层:与第六层所有的神经元相连,4096个神经元。
第八层:与第七层所有的神经元相连,输入到一个1000way-softmax分类器中,产生1000个分类类别。
减少拟合
(1)数据扩充
水平对称变换,将原来256*256的输入图像变成224*224的三张一样大小的图像补丁(这也就是为什么DS-CNN总体结构框架图中输入图像的大小是224*224*3的原因)。
对RGB像素值进行PCA处理,对每张训练图像加上一个服从均值为0,标准差为0.1的高斯正态分布的随机变量。也就是说,将每张RGB图像像素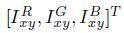
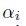
(2)Dropout
(补充:Dropout就是在训练过程中以一定概率将隐藏节点的输出值清0)
本实验中,就是以0.5的概率,将每个隐藏节点设为0。只有全连接层中的第一,第二层使用,也就是网络中第六,第七层。
训练细节
在训练这个CNNs时,采用随机梯度下降法进行更新优化。(梯度下降也就是通寻找合适的权值和偏置使得代价函数最小),每一批训练128个样例,动量项参数大小为0.9,权重衰减系数大小为0.0005,学习率为0.01(对所有层使用相同的学习率,如果这个值在训练时无法使误差收敛,那么就将学习率除以10作为新的学习率)。下面是网络中权值更新的规则。
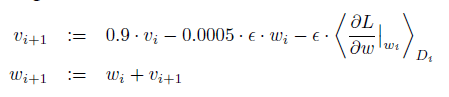
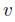
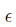
简而言之, ImageNet网络的独到之处是:
1.使用了新的激活函数ReLU(Rectified Linear Units)。
2.下采样层采用最大下采样代替平均下采样,并且是重叠下采样。
3.使用了局部响应归一化(Local Response Normalization)。
4.输出层使用softmax 分类器。
5.在训练中采用了dropout 技术。















 474
474

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









