







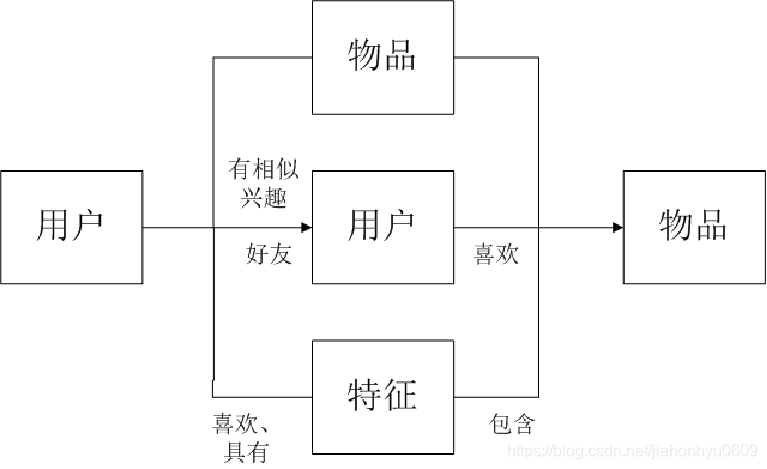
 我门需要三个方面进行给用户推荐,前两个是基于用户的,最后一个是基于内容的(这部分需要切词)。
我门需要三个方面进行给用户推荐,前两个是基于用户的,最后一个是基于内容的(这部分需要切词)。
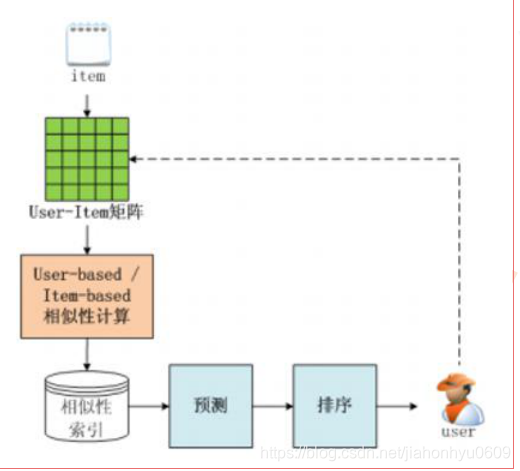
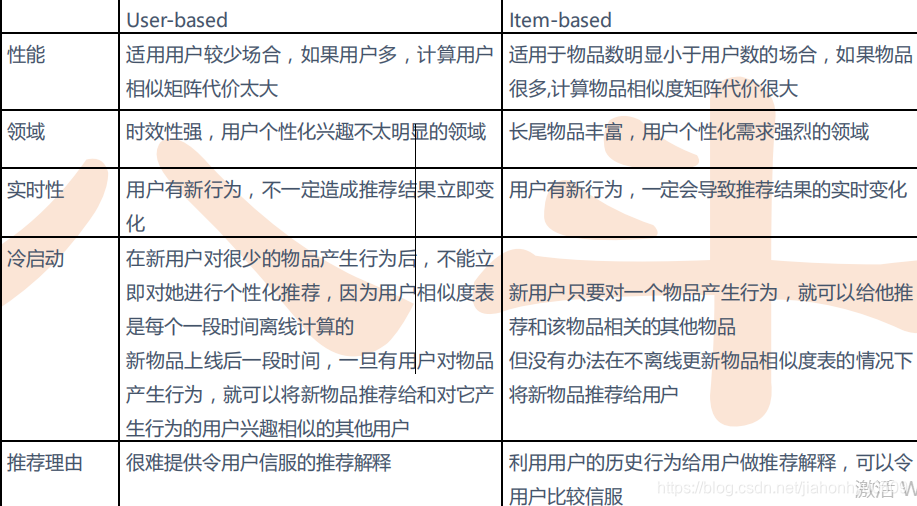
用户的历史记录,会有一个user-item矩阵,根User-Based CF 计算user与user的相似度矩阵。Item-Based CF 就算item-item的相似度矩阵。
CF的优点
– 充分利用群体智慧(历史行为数据)
– 推荐精度高于CB
– 利于挖掘隐含的相关性(啤酒尿布)
• 缺点
– 推荐结果解释性较差
– 对时效性强的Item不适用(我们算的都是T+1的,就是一天前的数据)
– 冷启动问题
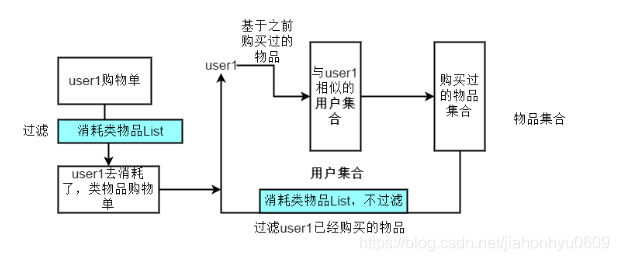
用户购买多次的物品,做一个count统计,大于一次的放入消耗类物品List中。
过滤User1已经购买的物品时、这个消耗物品List里面的物品不做过滤。要在用户已经购买的购物清单处过滤,这样推荐给user1用户的物品里面就没有消耗类List了。
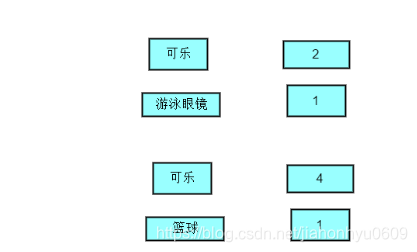
统计一个用户有偶然性,因为我买了一个墨镜后来丢了,排出这种可能性,增加保守的统计,统计多个的话,这种偶然性的占比就很小了。找出购买可乐的user用户几个,3个作为分母,再找出大于1个的作为分子,就是2/3。然后自己设置一个概率,概率大于60%的放入消耗List中去。
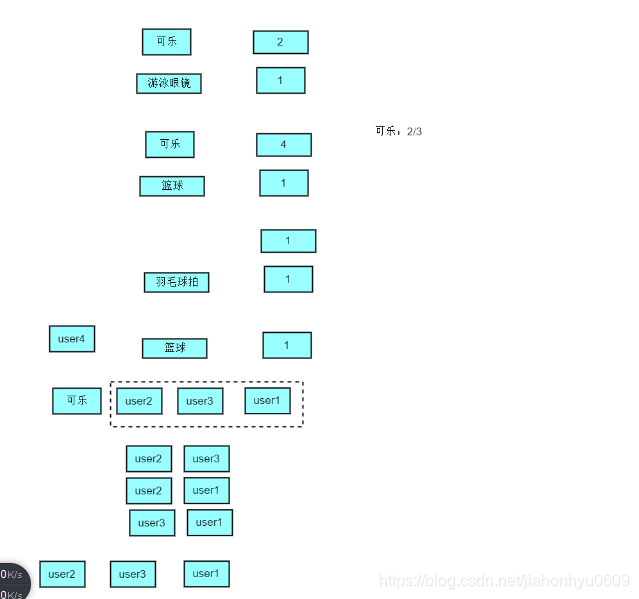
根据User-item矩阵能计算出:User-BasedCF,能计算出User-User的相似度矩阵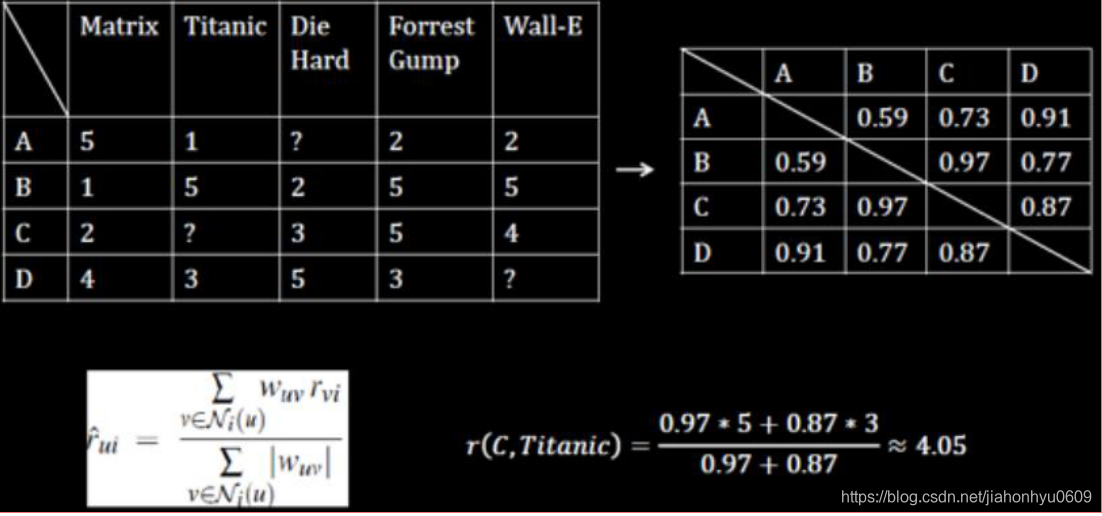
A和B的欧式距离:sqrt((5-1)^2 + (1-5)^2 + (2-5)^2 + (2-5)^2)
计算用户A和用户B的相似度:
余弦相似度cos = (15+15+25+25)/sqrt(25+1+4+4)sqrt(1+25+25+25)
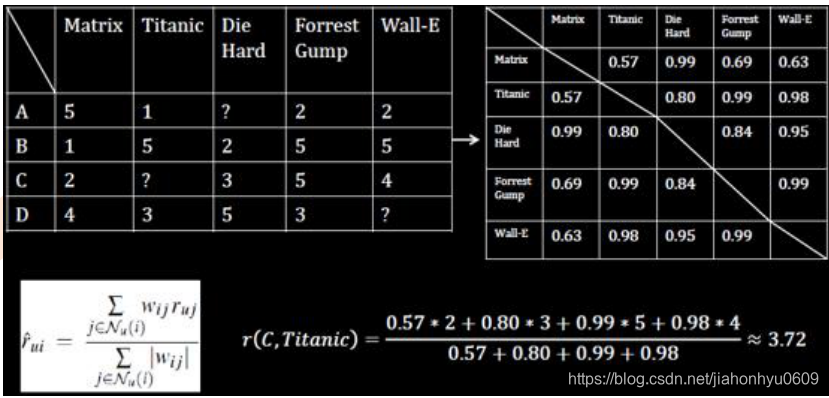
C,titanic
A 0.73,B:0.97,D:0.87取相似最大的前两个用户
B:0.97,D:0.87
C用户对titanic的电影评价是 = (50.97+3*0.87)/(0.97+0.87 )
Item—BasedCF,计算出Item-Item之间的相似性。算出用户以前购买的物品或者喜欢的相似物品,item-item矩阵可以存到内存中或者是线上要用的redis中,这样用户浏览时可以直接推给他,比user_cf要快。

冷 启 动问题:
分为三类
–1. 用户冷启动
• 提供热门排行榜,等用户数据收集到一定程度再切换到个性化推荐
• 利用用户注册时提供的年龄、性别等数据做粗粒度的个性化
• 利用用户社交网络账号,导入用户在社交网站上的好友信息,然后给用户推荐其好友喜欢的物品
• 在用户新登录时要求其对一些物品进行反馈,收集这些兴趣信息,然后给用户推荐相似的物品
– 2.物品冷启动
• 给新物品推荐给可能对它感兴趣相似的物品的用户,利用内容信息,将他们推荐给喜欢过和他们相似的物品的用户。
• 物品必须能够在第一时间展现给了,否则经过一段时间后,物品的价值就大大降低了
• UserCF和ItemCF都行不通,只能利用 Content based解决该问题,频繁更新相关性数据。
—3.系统冷启动
•引入专家知识,通过一定高效方式迅速建立起物品的相关性矩阵
基于user_cf的算法实现
generate_train_data.py
import pandas as pd
from recall import user_cf
import operator
from recall import item_cf
data_path = 'C:\\Users\\zheng\\PycharmProjects\\webpy_test\\cf\\data\\u.data'
udata = pd.read_csv(data_path,
sep='\t',
header=None,
names=['user_id', 'item_id', 'rating', 'timestamp'])
#做成训练数据,train的数据格式:{user_id:{item_id:rating}}
train = dict()
# for _,row in udata.iloc[:2,:].iterrows():
for _, row in udata.iterrows(): # 对每一行数据进行迭代,_是第一列的0,1,2,3,4
user_id = str(row['user_id']) # 取user_id的数据
item_id = str(row['item_id']) # 取item_id的数据
rating = row['rating'] # 取rating的数据
if train.get(user_id, -1) == -1: # 如果在train中没有user_id这个值,则我们把user_id至为字典形式,就是{user_id:{}}
train[user_id] = dict()
train[user_id][item_id] = rating # {user_id:{item_id:rating}}
# ###################user_cf test###################
#找相似用户
W = user_cf.user_similarity(train)
# 按相似度值做排序key=operator.itemgetter(1),逆序,取前10个
print(sorted(W.get('1').items(), key=operator.itemgetter(1), reverse=True)[:10])
# 相似用户的物品集合
rec_item_list = user_cf.recommend('1', train, W, 10)
print(sorted(rec_item_list.items(), key=operator.itemgetter(1), reverse=True)[:20])
# ###################item_cf test###################
W2 = item_cf.item_similarity(train)
item_list = item_cf.recommend(train,'1',W2,10)
print(sorted(item_list.items(), key=operator.itemgetter(1), reverse=True)[:20])
user_cf.py(基于用户的协同过滤)
import operator
import math
# train 格式 :{user:{item:rating}}
#相似用户
def user_similarity(train):
# 建立item->users倒排表(一个item有多少个user购买了它),目的是,如果有相似的item,就计算users里面的user之间的相似度,如果没有,就不计算user的相似度,这样的话,就可以不用计算除了我以外全部的user相似度。
item_users = dict()
for u, items in train.items(): # 按字典形式遍历u=user_id, items={item_id:rating}
for i in items.keys(): # items.keys()这个字典中的item_id取出
if i not in item_users: # 如果item_id不在这个item_users倒排表里面
item_users[i] = set() # 我们定义一个set加进去
item_users[i].add(u) # 如果item_users中有这个item, 则把物品的用户给加进去,一个user里面有多个item,按个遍历下,每个item都add这个用户,其他的用户也add
#train: {user:{item:rating}} {'196': {'242': 3}, '186': {'302': 3}}
#item_users: {item:{users...}} {'242': {'196'}, '302': {'186'}}
# 计算相似user共同的物品数量(item_users里面的user和user的相似度),这块要加一个热门物品的衰减,热门的物品你们买的一样,不一定你们两个兴趣相似,要是冷门的物品你们两买的一样,说明相似,所以给热门物品做衰减
C = dict() # 相似用户之间相同物品的数量 交集
N = dict() # 存储每个用户拥有的Item数量 分母 C/N大致的相似度(两个交集的大小/u购买item的集合大小*v购买item的集合大小)
for i, users in item_users.items(): # item_users= {item_id:{user_id,user_id...}}
for u in users:
if N.get(u, -1) == -1: # 初始化一下,先让每个用户拥有的item数量为0,后面再加
N[u] = 0
N[u] += 1
if C.get(u, -1) == -1: # 初始化一下,先让相似用户相同的物品的数量为dict(),因为这个存的不仅有用户u,还有用户v,所以用dict来存。
C[u] = dict() # 每个用户对应其他的用户和它们对应的物品数量
for v in users:
if u == v:
continue
elif C[u].get(v, -1) == -1:
C[u][v] = 0 # 初始化一下
C[u][v] += 1 # 因为它们都是对应的一个item,所以是1,等在for循环,就是下一个item,就在+1
# C[u][v] += 1 / math.log(1 + len(users)) 1/log(1+用户数量)
# 得到最终的相似度矩阵W(只计算和它购买相似物品的user的相似度,不需要计算除了他自己以外全部user的相似度)
W = dict()
for u, related_users in C.items(): # related_users 是和u相似的其他用户集合{user_id:和u相同的item数量}
if W.get(u, -1) == -1:
W[u] = dict() # 初始化
for v, cuv in related_users.items(): #v是和u相似的用户, cuv是相同item的数量(交集)
W[u][v] = cuv / math.sqrt(N[u] * N[v] * 1.0) #交集/sqrt(u用户购买的item*v用户购买的item)
return W
# 相似用户的物品集合(取前几个相似用户,然后把他们对应item拿出来)
def recommend(user, train, w, k): # 得传入user,这样才能拿到与user1相似的用户,进而拿到相似用户对应的item
rank = dict() #粗排
interacted_items = train[user].keys() #train[user].keys()拿到user1购买过物品的集合
for v, wuv in sorted(w[user].items(), #wuv是v和u的相似度,w[user].items()取和user1相似的用户和他们对用的相似度
key=operator.itemgetter(1),
reverse=True)[0:k]:
for i, rvi in train[v].items(): #取相似用户对应的item,i是item,rvi是对应的打分rating,
if i in interacted_items: # 过滤已经购买过的物品
continue
elif rank.get(i, -1) == -1:
rank[i] = 0 #初始化,这个是粗排
rank[i] += wuv * rvi #相似用户之间的分值*相似用户对它的物品打分(具体看下面图)
return rank
建立倒排索引的目的:
就是我们计算可乐的user.只计算购买它的users之间的相似度。user2和user3,user2和user1,user3和user1之间的相似度就可以,不用把user4也加进来计算。
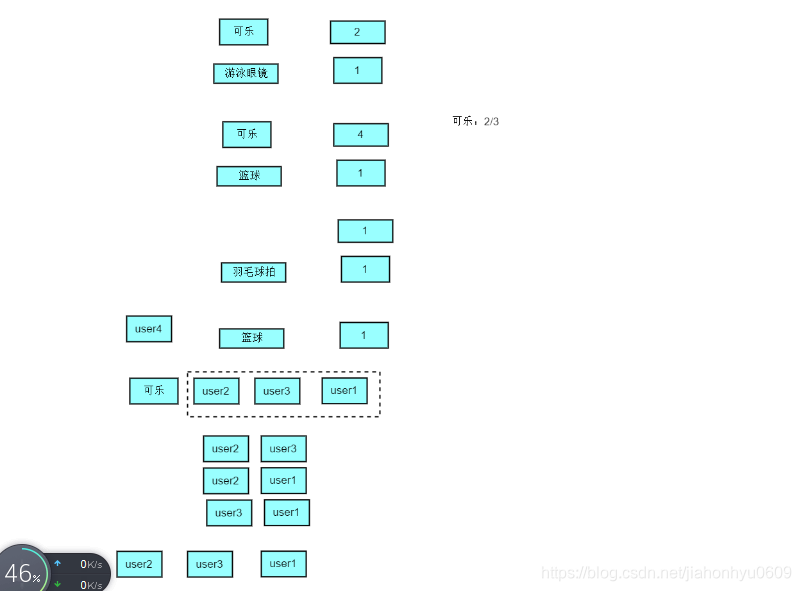
计算user和user的相似度:
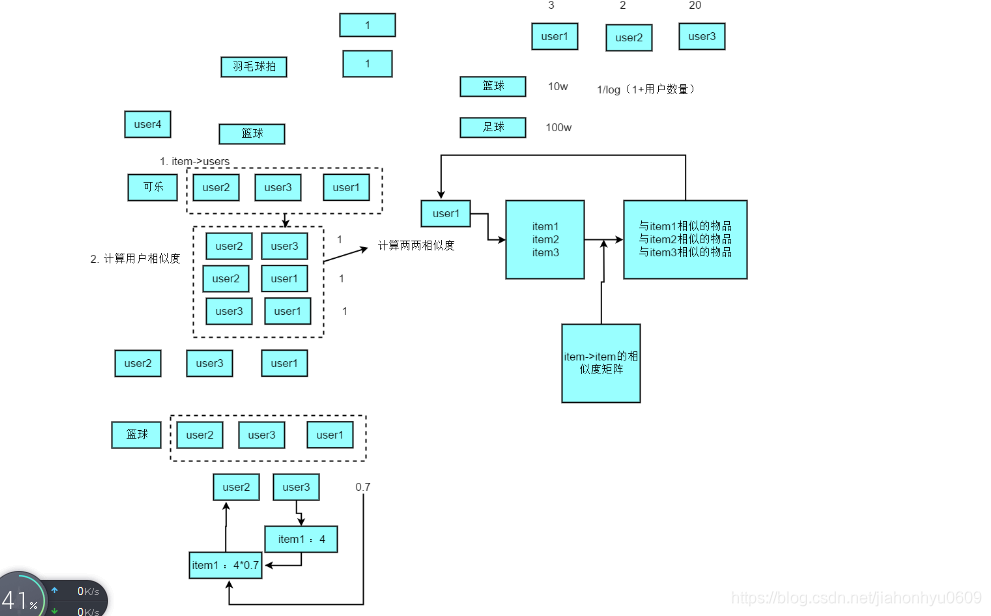
item_cf.py(基于物品的协同过滤)
import math
import operator
'''
input: train:{user_id:{item_id:rating(score)},...}
'''
# item-item的相似度{item_id:{item_id:相似度}}
def item_similarity(train):
# 计算item与item相同的user的数量
C = dict() # 存item1与其他item相同user的个数 分子{item_id:{item_id:user个数}} (和user_cf那个相反)
N = dict() # item对应的用户数量 分母
for u, items in train.items(): # {user_id:{item_id:rating}}
for i in items: # 取{item_id:rating}中的item
if N.get(i, -1) == -1:
N[i] = 0 #初始化一下
N[i] += 1 #根据for循环+1
if C.get(i, -1) == -1:
C[i] = dict() #初始化,因为多个item和他对应的user,所以用dict存储
for j in items: #相同的物品不用计算了
if i == j:
continue
elif C[i].get(j, -1) == -1:
C[i][j] = 0 #初始化,对于i这个物品来说,没有物品j,所以初始化
C[i][j] += 1 #对于这个u用户数量+1
# 加分母计算相似度
W = dict()
for i, related_items in C.items(): # {item_id:{item_id:user个数}}
if W.get(i, -1) == -1:
W[i] = dict() #初始化,多个item的相似度,所以用dict存储
for j, cij in related_items.items(): # j是和i相似的物品。cij就是user的数量
if W[i].get(j, -1) == -1:
W[i][j] = 0 #初始化,因为下面有个 W[i][j] += 操作,所以必须有个初始值。不然报错了
W[i][j] += cij / math.sqrt(N[i] * N[j]) # user个数/sqrt(i物品对应的user数*j物品对应的user数)
return W
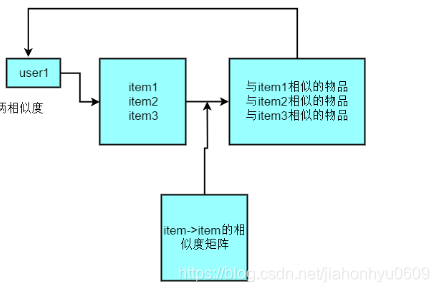
# 最终推荐,从item-item相似度矩阵中计算(与item1,与item2,与item3...相似的物品),然后推给用户
def recommend(train, user, w, k): #user要传进来,因为我们要从user里面取出对应的item
rank = dict()
ru = train[user] #取出item的集合 {item_id:rating}
for i, pi in ru.items(): #i是item_id,pi就是打分rating
for j, wj in sorted(w[i].items(), # 取出和i相似的k个相似item。相似的item j。wj是i物品和j物品之间的相似度。
key=operator.itemgetter(1),
reverse=True)[0:k]:
if j in ru: #如果j物品在之前购买的item集合中,则过滤掉
continue
elif rank.get(j, -1) == -1: #得到j物品的分值
rank[j] = 0 #没有则初始化一下,因为下面做rank[j] += 操作
rank[j] += pi * wj # item对用的rating*item与item的相似度
return rank
Item_cf的协同过滤:
计算item相同的user数量,
两个推荐引擎都做完各自的排序后,然后按照他们的key做一个过滤,加set(key),过滤掉他们推荐重复的item














 2137
2137











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









