






用到的模型:
LLM:deepseek-r1(7B)
embedding模型:quentinz/bge-large-zh-v1.5
软件:MobaXterm
1、下载项目
链接:GitHub - HKUDS/LightRAG: "LightRAG: Simple and Fast Retrieval-Augmented Generation"
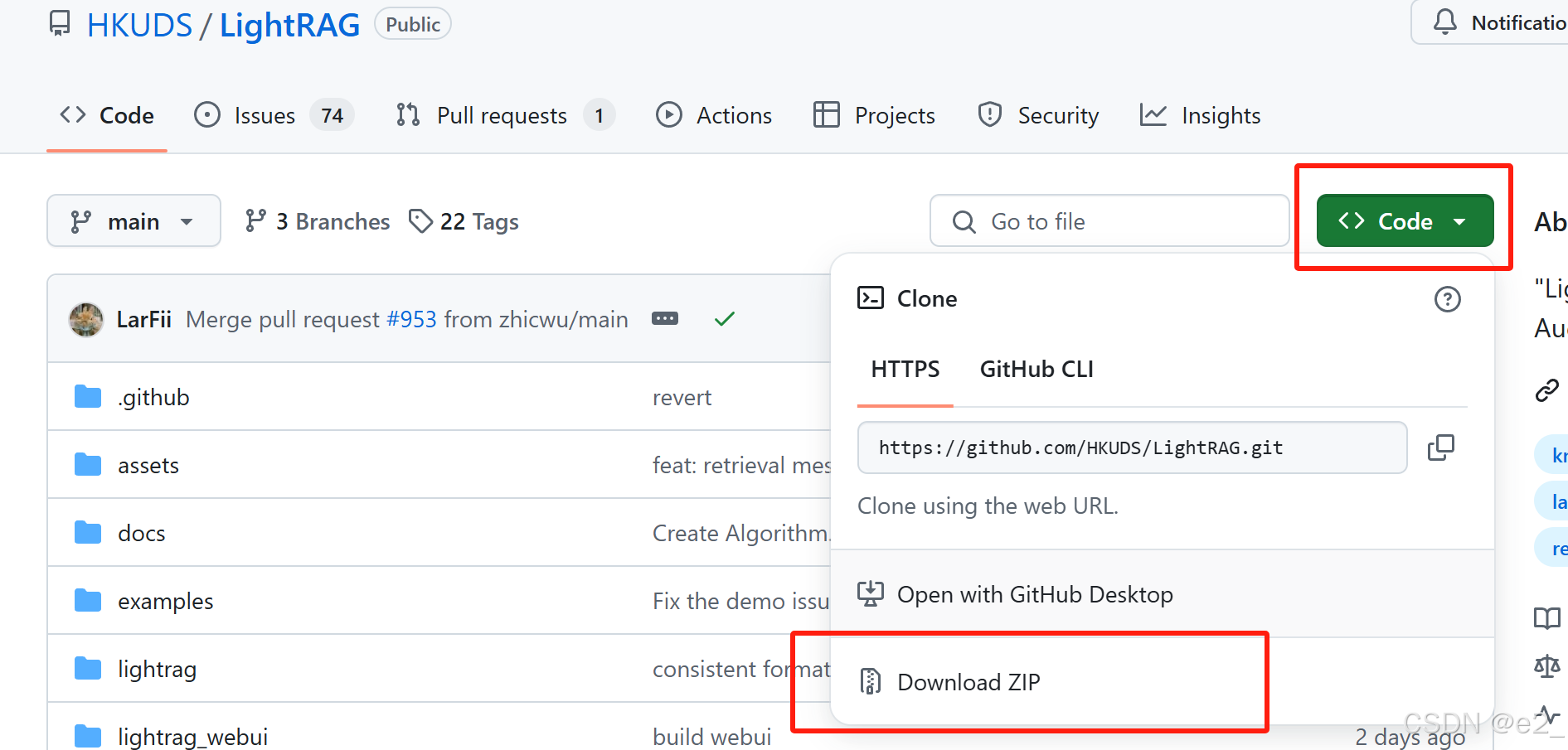
下载好之后解压,然后上传到服务器(eg:文件位置为/home/user/LLM/LightRAG)
2、用ollama下载模型
运行ollama:

OLLAMA_HOST=127.0.0.1:11500 ./ollama serve下载模型:
ollama pull deepseek-r1 #LLMollama pull quentinz/bge-large-zh-v1.5 #emnedding模型3、把ollama中LLM模型的上下文长度调整到32k
ollama show --modelfile deepseek-r1:latest > Modelfile找到Modelfile文件,进行以下修改:
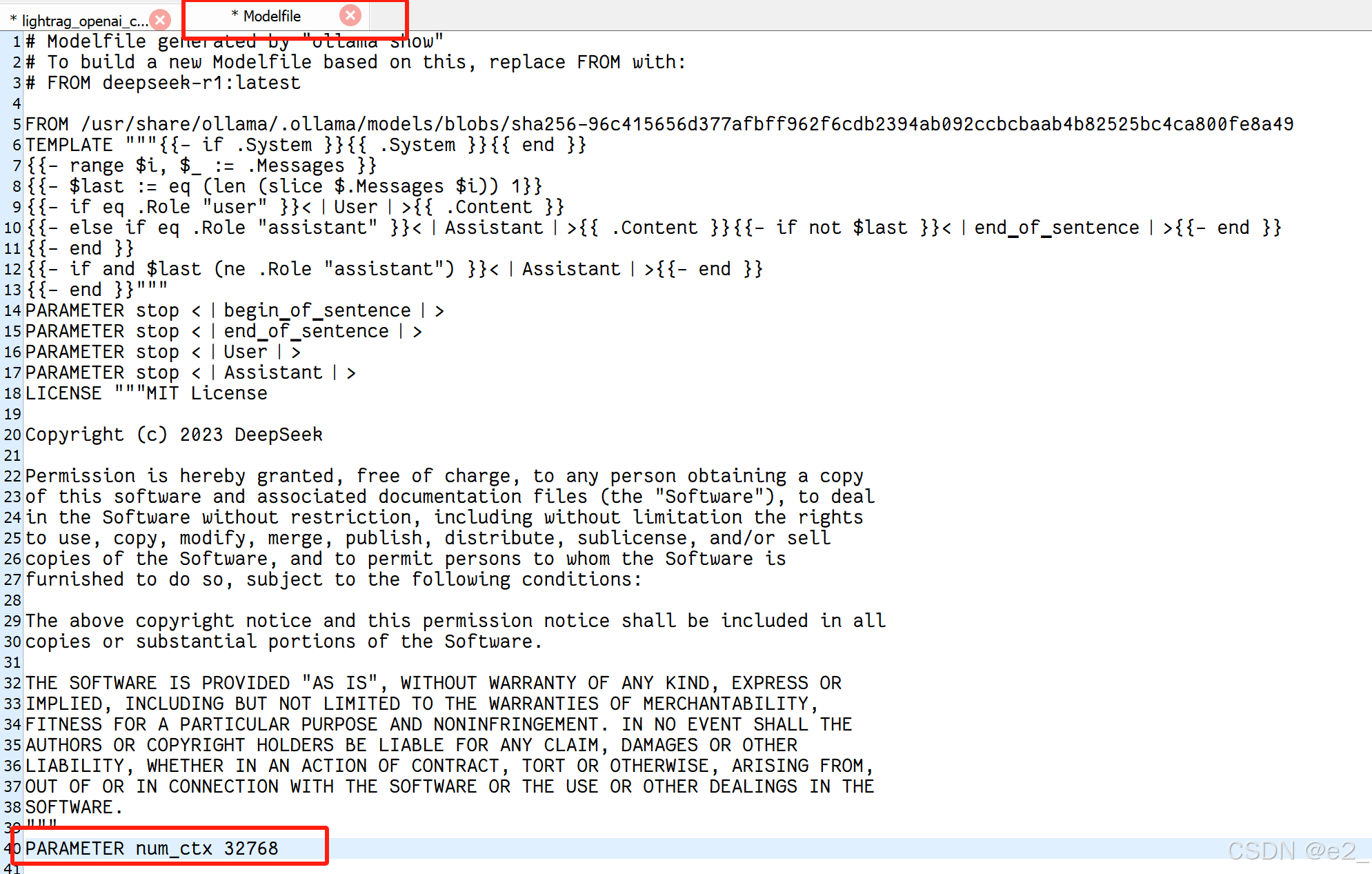
ollama create -f Modelfile deepseek-r1-7b-32k4、运行deepseek-r1-7b-32k
通过 ollama list 查看已有的模型列表:

运行deepseek-r1-7b-32k:
ollama run deepseek-r1-7b-32k5、创建虚拟环境
conda create --name LightRAG python=3.10 #注意这里Python版本必须>=3.10
conda activate LightRAG #激活环境进入/home/user/LLM/LightRAG/LightRAG-main/文件夹
pip install -e .6、准备样例数据
进入/home/user/LLM/LightRAG/LightRAG-main/examples文件夹
使用官方的英文示例:
#使用 curl 命令从指定的 URL 下载文件,并将其内容保存到本地文件 book.txt 中
curl https://raw.githubusercontent.com/gusye1234/nano-graphrag/main/tests/mock_data.txt > ./book.txt 7、修改代码
在examples文件夹中找到lightrag_ollama_demo.py进行修改
修改LLM、embedding模型:
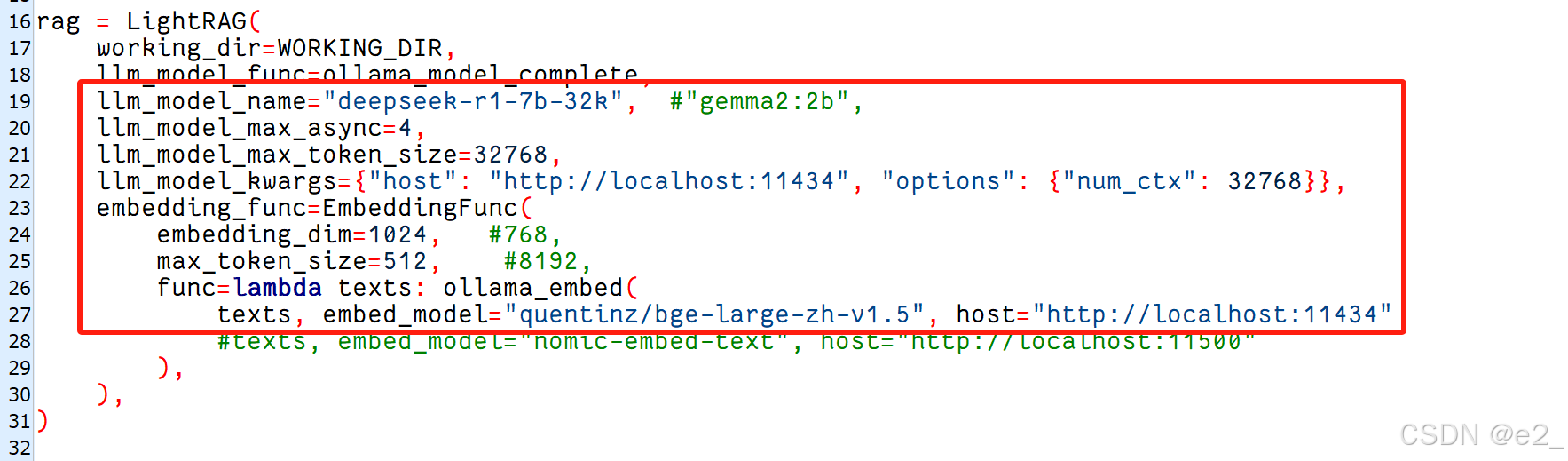
7、运行代码
进入/home/user/LLM/LightRAG/LightRAG-main/examples/文件夹
运行代码:
python lightrag_ollama_demo.py在代码的运行过程中,可以查看ollama正在运行的模型:

运行成功:
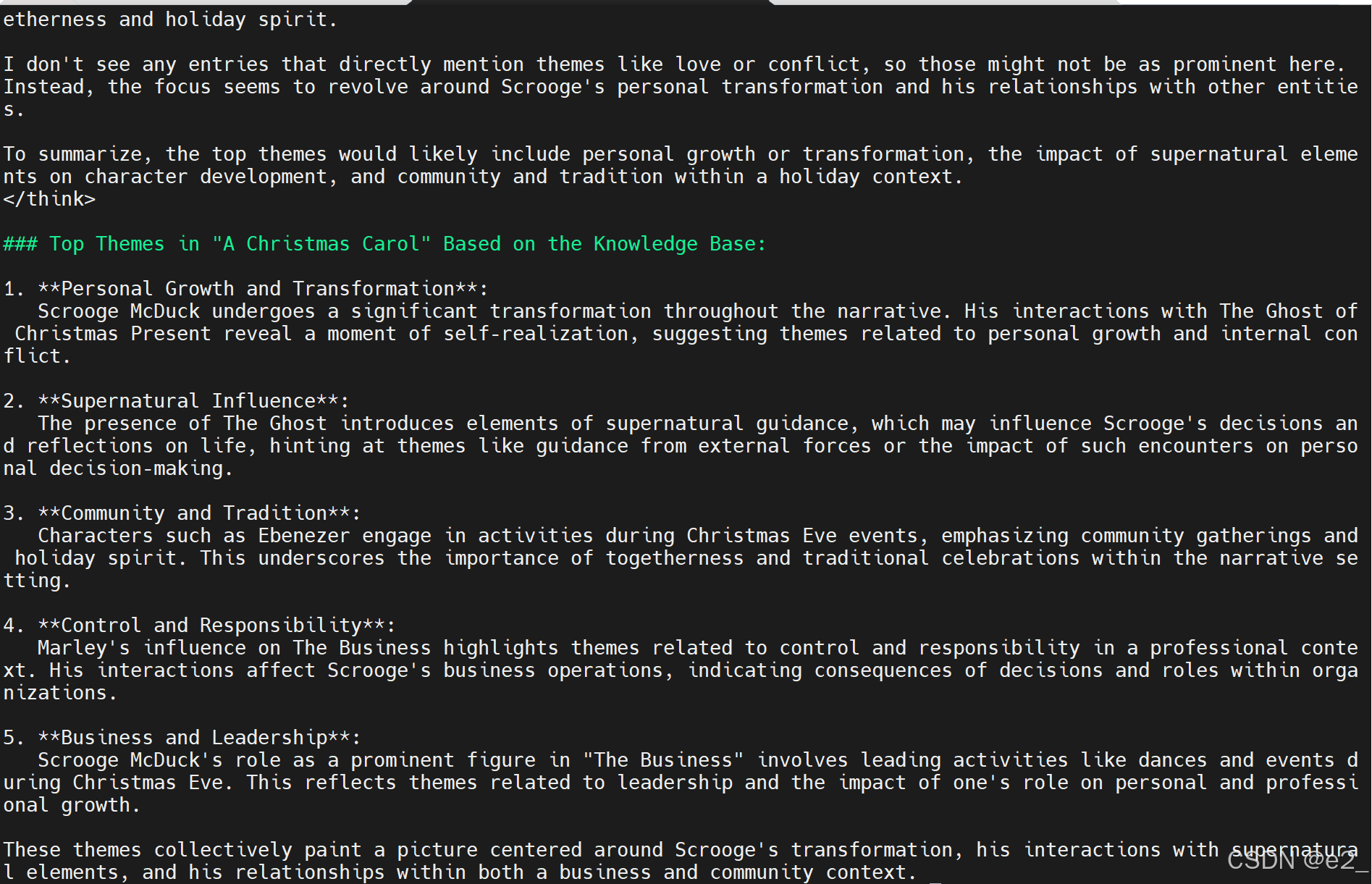
8、把文档格式从.txt修改为PDF
参考链接:LightRAG:GraphRAG 的简单快速替代品
在你的虚拟环境中安装 pdfplumber:
pip install pdfplumber在examples文件夹下,创建一个新的python文件,具体代码如下:
(这个代码和原来的lightrag_ollama_demo.py,只有文档的读取部分有不同:

改为:
此为具体代码:(输入的PDF文档名为paper.pdf,同样放在examples文件夹下)
import asyncio
import os
import inspect
import logging
from lightrag import LightRAG, QueryParam
from lightrag.llm.ollama import ollama_model_complete, ollama_embed
from lightrag.utils import EmbeddingFunc
import pdfplumber
WORKING_DIR = "./Documents"
logging.basicConfig(format="%(levelname)s:%(message)s", level=logging.INFO)
if not os.path.exists(WORKING_DIR):
os.mkdir(WORKING_DIR)
rag = LightRAG(
working_dir=WORKING_DIR,
llm_model_func=ollama_model_complete,
llm_model_name="deepseek-r1-7b-32k", #"gemma2:2b",
llm_model_max_async=4,
llm_model_max_token_size=32768,
llm_model_kwargs={"host": "http://localhost:11434", "options": {"num_ctx": 32768}},
embedding_func=EmbeddingFunc(
embedding_dim=1024, #768,
max_token_size=512, #8192,
func=lambda texts: ollama_embed(
texts, embed_model="quentinz/bge-large-zh-v1.5", host="http://localhost:11434"
#texts, embed_model="nomic-embed-text", host="http://localhost:11500"
),
),
)
pdf_path = "./paper.pdf" # Constitution_of_India.pdf
pdf_text = ""
with pdfplumber.open(pdf_path) as pdf:
for page in pdf.pages:
pdf_text += page.extract_text() + "\n"
rag.insert(pdf_text)
# Perform naive search
print(
#rag.query("What are the top themes in this story?", param=QueryParam(mode="naive"))
rag.query("这个故事的主题是什么?", param=QueryParam(mode="naive"))
)
# Perform local search
print(
rag.query("这个故事的主题是什么?", param=QueryParam(mode="local"))
#rag.query("What are the top themes in this story?", param=QueryParam(mode="local"))
)
# Perform global search
print(
rag.query("这个故事的主题是什么?", param=QueryParam(mode="global"))
#rag.query("What are the top themes in this story?", param=QueryParam(mode="global"))
)
# Perform hybrid search
print(
rag.query("这个故事的主题是什么?", param=QueryParam(mode="hybrid"))
#rag.query("What are the top themes in this story?", param=QueryParam(mode="hybrid"))
)
# stream response
resp = rag.query(
"这个故事的主题是什么?",
param=QueryParam(mode="hybrid", stream=True),
)
async def print_stream(stream):
async for chunk in stream:
print(chunk, end="", flush=True)
if inspect.isasyncgen(resp):
asyncio.run(print_stream(resp))
else:
print(resp)
















 4346
4346

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









