







 本文介绍了CUDA编程在提升计算速度方面的潜力,通过学习《GPGPU编程技术》并实现实现平方和的缩减内核。第一版程序虽然能运行,但速度较慢。在第二版中增加了计时功能,通过cudaMemcpy获取GPU执行时间,并计算带宽。结果显示,执行效率和带宽较低,暗示优化的必要性。后续文章将探讨CUDA程序的优化策略。
本文介绍了CUDA编程在提升计算速度方面的潜力,通过学习《GPGPU编程技术》并实现实现平方和的缩减内核。第一版程序虽然能运行,但速度较慢。在第二版中增加了计时功能,通过cudaMemcpy获取GPU执行时间,并计算带宽。结果显示,执行效率和带宽较低,暗示优化的必要性。后续文章将探讨CUDA程序的优化策略。
CUDA程序优化小记(一)
CUDA全称Computer Unified Device Architecture(计算机同一设备架构),它的引入为计算机计算速度质的提升提供了可能,从此微型计算机也能有与大型机相当计算的能力。可是不恰当地使用CUDA技术,不仅不会让应用程序获得提升,反而会比普通CPU的计算还要慢。最近我通过学习《GPGPU编程技术》这本书,深刻地体会到了这一点,并且用CUDARuntime应用改写书上的例子程序;来体会CUDA技术给我们计算能力带来的提升。
原创文章,反对未声明的引用。原博客地址:http://blog.csdn.net/gamesdev/article/details/17488237
我这个程序实现的是一个缩减内核。缩减的意思是从多个数据中提炼出较少的数据。具体来说,我将要实现的是平方和。即a12+ a22+ a32+a42+ a52这样的。首先了解一下CUDA内核的调用方式,即这样:
functionCall<<<dim3 网格大小,dim3 块大小,size_t 共享内存数量,cudaStream_t cuda的流>>>
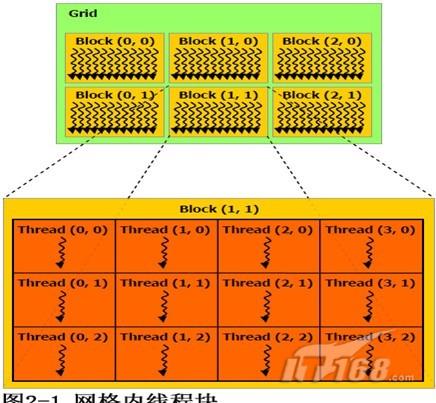
CUDA的执行模型是这样的:一次执行任务由一个或若干个网格(grid)组成,每一个格中有若干个块(block),每一个块中有若干个线程(thread),由这些组成了CUDA的执行模型。
好了,我们第一版程序非常简单,参照《GPGPU编程技术》中的算法,再加上CUDARuntime的编程写法,一个简单的程序就写好了。
#include <cuda_runtime.h>
#include <cctype>
#include <cassert>
#include <iostream>
#define DATA_SIZE 1048576
#ifndef nullptr
#define nullptr 0
#endif
using namespace std;
void GenerateData( int* pData,size_t dataSize )// 产生数据
{
assert( pData != nullptr );
for ( size_t i = 0; i <dataSize; i++ )
{
srand( i + 3 );
pData[i] = rand( ) % 100;
}
}
__global__ static voidKernel_SquareSum( int* pIn, size_t* pDataSize, int* pOut )
{
for ( size_t i = 0; i <*pDataSize; ++i )
{
*pOut += pIn[i] * pIn[i];
}
}
bool CUDA_SquareSum( int* pOut, int* pIn, size_t dataSize )
{
assert( pIn != nullptr );
assert( pOut != nullptr );
int* pDevIn = nullptr;
int* pDevOut = nullptr;
size_t* pDevDataSize = nullptr;
// 1、设置设备
cudaError_t cudaStatus = cudaSetDevice( 0 );
if ( cudaStatus != cudaSuccess )
{
fprintf( stderr, "调用cudaSetDevice()函数失败!" );
ret 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2903
2903

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









