







普通shuffle过程
shuffle过程是spark运算的重要过程,也是spark调优的关键地方之一,在spark中的reduceByKey,groupByKey,sortByKey,countByKey,join,cogroup等操作时,都会触发shuffle过程。shuffle过程发生在shuffleMapTask与resultTask之间,当shuffleMapTask的输出数据先放到内存bucket中,bucket会shuffleMapTask的输出Mapstatus,发送给DAGScheduler的mapoutputTrackerMaster。然后将数据写入shuffleblockFile磁盘文件。resultTask会用blockStoreShuffleFetcher去MapoutputTrackerMaster获取到要拉取的文件信息,然后通过blockManager拉取该磁盘文件。每个resultTask拉取过来的数据,是一个shuffledRDD,优先写入内存,内存不够写入磁盘。然后每个resultTask对数据进行聚合,最后生成MapPartitionsRDD,然后执行算子。map端默认内存缓存是100K,达到阈值就会刷磁盘,这种方式避免了早期版本中对内存大小的依赖,避免OOM。但是也可能数据过大造成频繁刷写磁盘。
此处与MR不同的是,MR要在map数据文件全部写入磁盘后才可以拉取文件,因为mr需要对数据排序,需要map全部写完排序后才进行reduce端拉取;但是spark不会在map端排序,所以map端只要写一些数据,reduce端就可以进行拉取计算。因此速度上spark要比mr快,但是mr的reduce处理很方便,但是spark不能提供直接处理key对应的value,没有mr的reduce方便。
优化shuffle过程
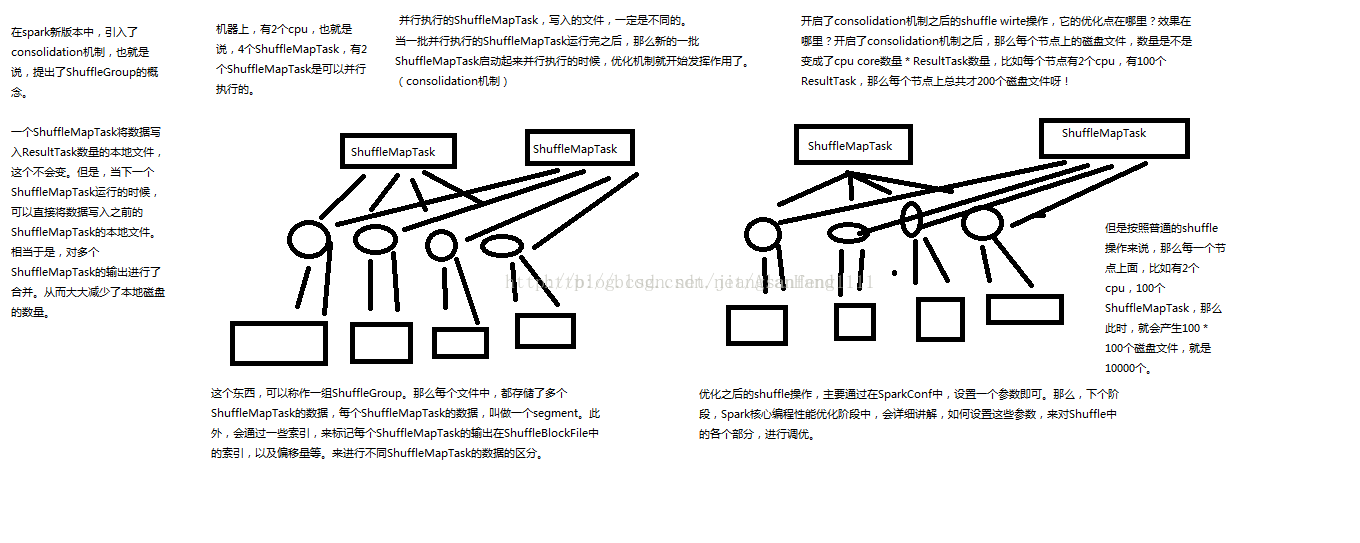
以上过程是普通的shuffle过程,但是该shuffle过程最大的问题是产生的磁盘文件太多,后面的版本中对此进行了优化,即spark的consolidation机制,也就是shuffleGroup概念。一个shuffleMapTask将写入resultTask数量的本地文件,当下一个shuffleMapTask运行的时候,可以将数据写入之前的shuffleMapTask的本地文件,相当于对多个shuffleMapTask的数据进行了合并,也就是其他的shuffleMapTask的输出会复用前一个shuffleMapTask的内存缓存和磁盘文件。复用的shuffleMapTask组成为一组shuffleGroup,通过索引标注shuffledBlockFile中每个shuffleMapTask输出的位置。每个shuffleMapTask输出的数据称为一个segment。从未减少了本地磁盘的数量。开启了consolidation的shuffle后,每个节点上磁盘文件的数量就是CPU core数量 * resultTask数量。
上面的文章分析中,在shuffleMapTask类中,当执行到writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])时候,ShuffleWriter的write方法就是对数据的map端写入操作。 默认的writer是org.apache.spark.shuffle.hash下的HashShuffleWriter,下面分析该类的write方法,该方法将map的输出写入本地磁盘














 1005
1005











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









