









brief
等式 y =ax + b,就是一个简单线性回归方程,
解释变量x与因变量y的关系可以用一个等式表达
或者说变量x可以解释变量y,变量x每变动1个单位,y就有预计会变动a个单位,也可以说就有一个变量y与之对应(其实是一个y总体的平均数)
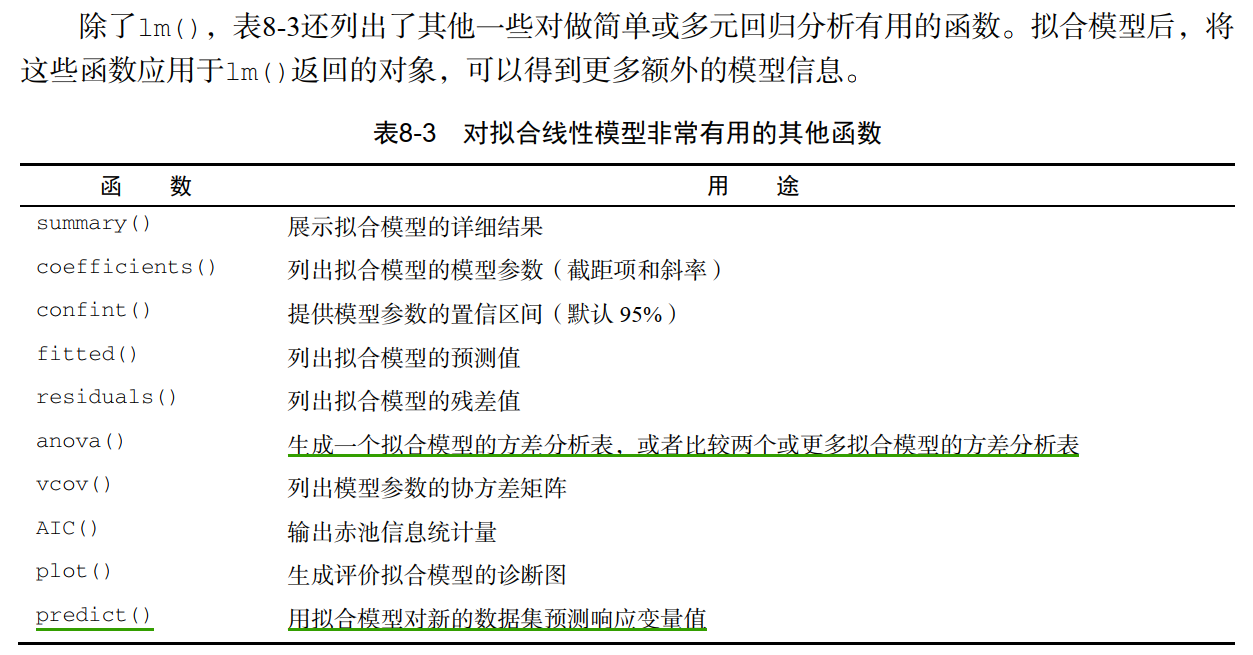
R函数拟合OLS回归模型
基础理论部分
OLS回归拟合模型的形式:
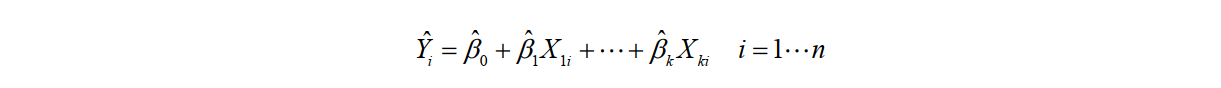


需要注意的是,正态性指每一个自变量x对应一个因变量y的正态总体。
构建函数


简单线性回归
attach(women)
head(women)
# 直接用身高预测体重试一下
myfit <- lm(weight~height,data = women)
#看一下总体表现
summary(myfit)
# 实际值和预测值
women$weight
fitted(myfit)
# 实际值和预测值之差被称为残差值
women$weight - fitted(myfit)
residuals(myfit)
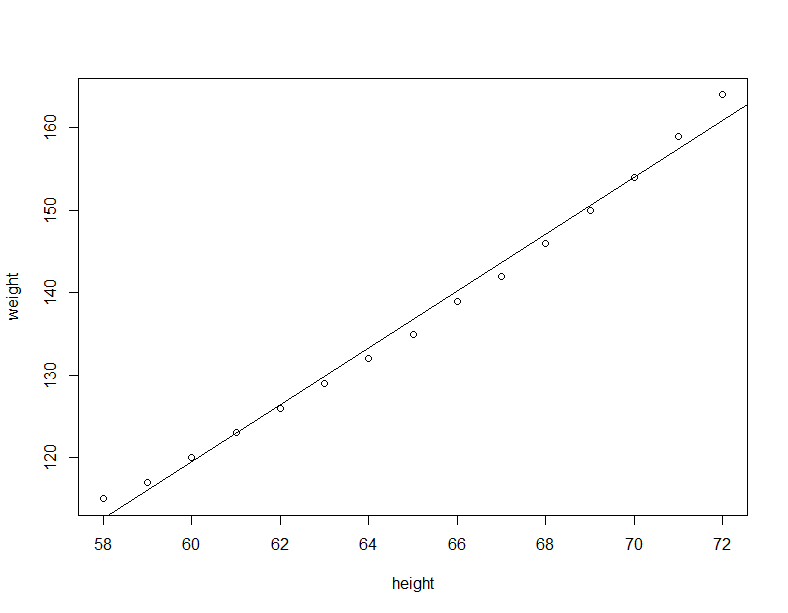
# 利用散点图看一下拟合情况
plot(women$height,women$weight,xlab = "height",ylab="weight")
abline(myfit)
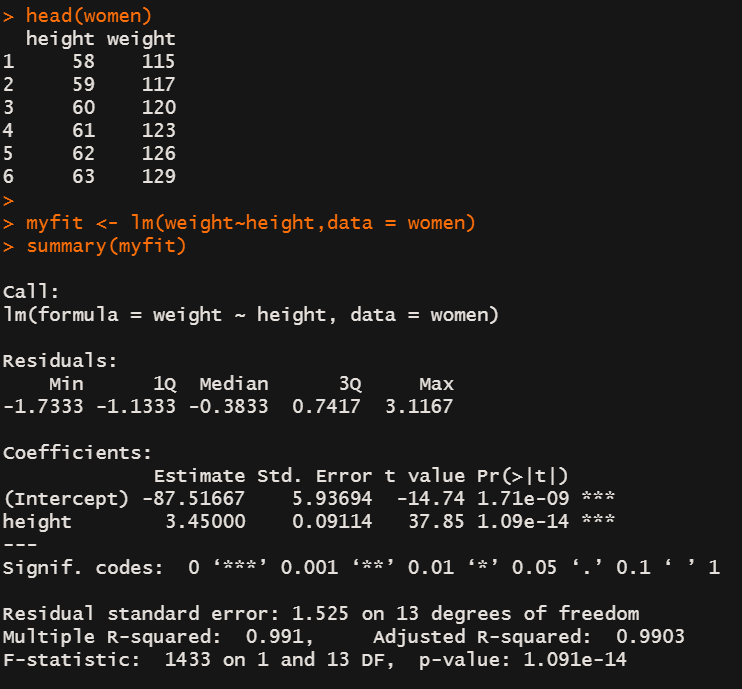
这里可一看到R2等于0.991,这个数据个人理解就是决定系数
还有F检验对回归系数进行了显著性检验
多项式回归
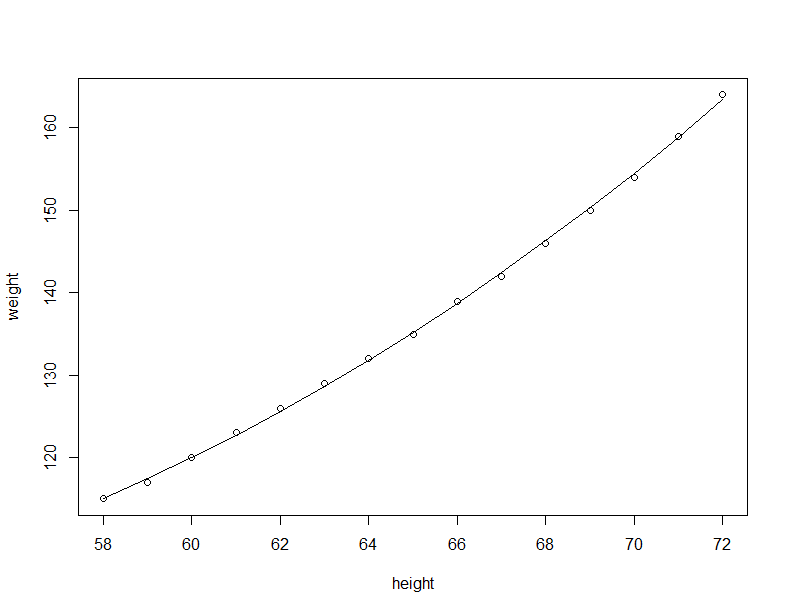
上面利用简单线性回归拟合数据,最后作图可以发现数据整体趋势微微向上弯曲,也许进行多项式回归最终拟合的效果会更好。
y = ax + bx2+c 二次项
y = ax + bx2+cx3+d 三次项
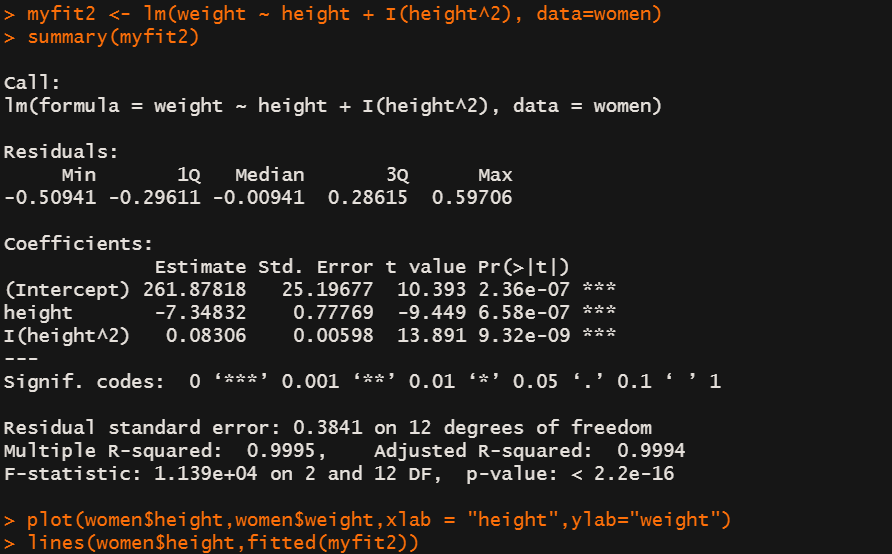
myfit2 <- lm(weight ~ height + I(height^2), data=women)
summary(myfit2)
plot(women$height,women$weight,xlab = "height",ylab="weight")
line(women$height,fitted(myfit2))
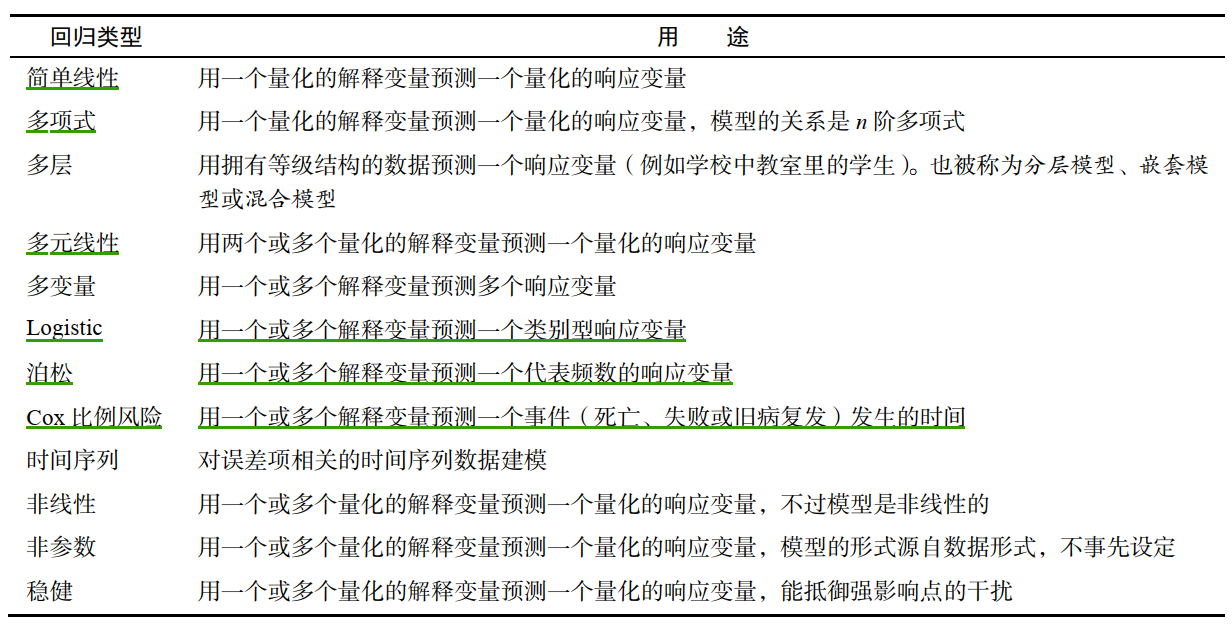
多元线性回归
当预测变量不止一个时,可以使用多元线性回归模型进行拟合
states <- as.data.frame(state.x77[,c("Murder", "Population",
"Illiteracy", "Income", "Frost")])
fit <- lm(Murder ~ Population + Illiteracy + Income + Frost,
data=states)
summary(fit)
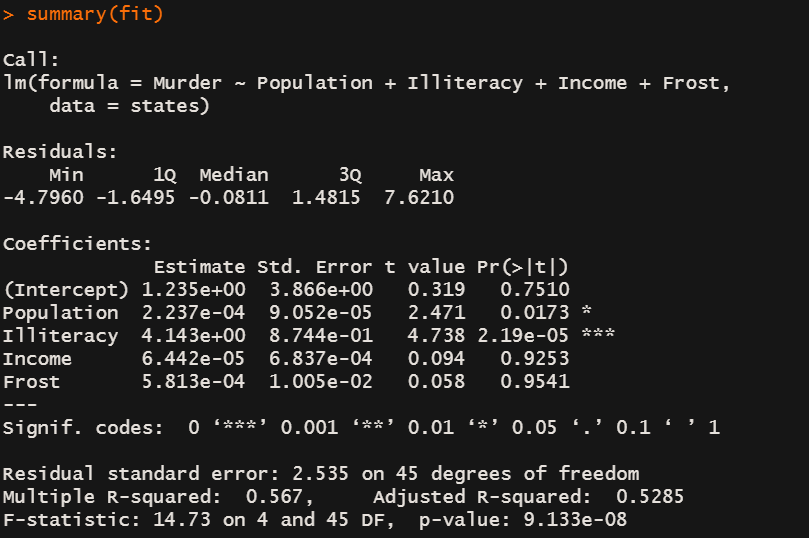
当预测变量不止一个时,回归系数的含义为:一个预测变量增加一个单位,其他预测变量保持不变时,因变量将要增加的数量。
在结果中,文盲率的回归系数为4.14,表示控制人口、收入、温度等不变时,文盲率上升1%,自杀率将会上升4.14%。Pr显著性小于α=0.05,拒绝原假设H0:回归系数等于0.
然后Frost的系数进行显著性检验时,没有拒绝原假设,表明控制其他变量不变时,Frost与Murder不成线性关系。
有交互项的线性回归
比如两个预测变量,这两个预测变量存在一定程度相互作用/影响,而且相互作用/影响的结果对结果变量影响程度怎么样,我们就可以使用交互向进行拟合。
fit <- lm(mpg ~ hp + wt + hp:wt, data=mtcars)
summary(fit)
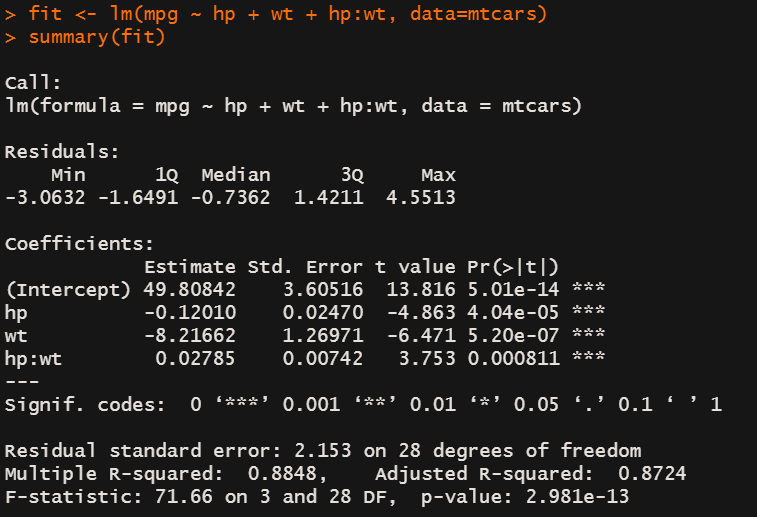
hp:wt交互项的系数显著不为0,说明因变量与其中一个自变量的关系严重依赖于另一个自变量。
评价拟合优度
文章最后面有pearson系数计算的手写公式,R2 等于pearson系数的平方,
R2 = SSxy2 / SSx * SSy
SS回归 = SSxy2 / SSx
所以 R2 = SS回归 / SSy 或者说X变异引起Y变异的平方和占Y总变异的平和的多少。
当然是R2 拟合的越大越好了,当然需要等式有实际意义。
检验假设条件
回归系数显著性检验

假设的检验
fit <- lm(weight ~ height, data=women)
par(mfrow=c(2,2))
plot(fit)
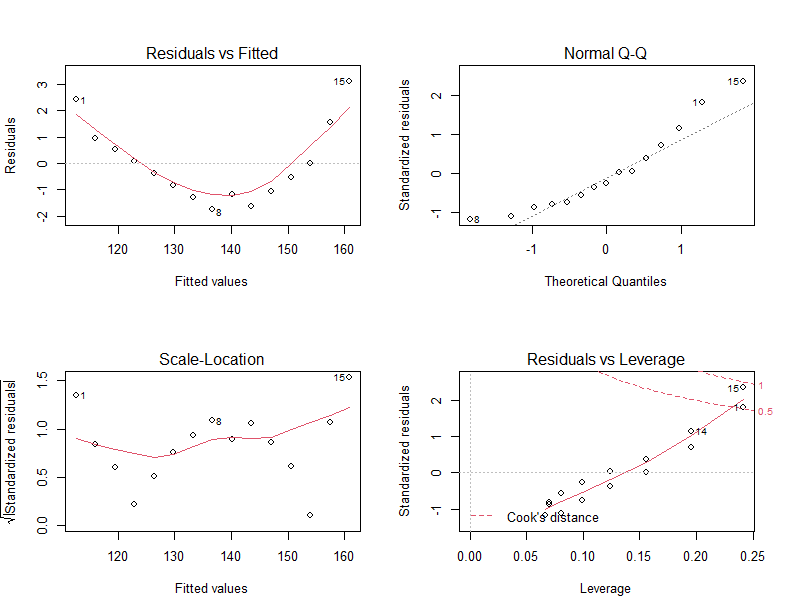
- 你的数据有多满足前提假设,进行回归后的结果就越有可能正确
- 假设认为一个自变量x对应一个因变量正态总体y,也就说y包含理论值和误差两部分,而且误差时正态随机分布的,残差值如果是误差造成的,是不是应该符合正态随机分布?所以残差值和因变量理论上没有趋势可言,第一幅图显示了他们的分布具有趋势。
- 残差值如果是随机正态分布那和理论上的分布应该是正相关且斜率靠近1,但是NormalQ-Q图表明,残差值不是标准版的正态随机分布。
- scale - location 图同上述解释一样,标准残差值理论上也是随机分布的,前提假设中因变量具有方差齐性,其实个人认为就是y包含的误差部分如果是正态分布的延伸。
- Residuals vs leverage可以让我们看到离群点,也就是对因变量y方差贡献最多的一些点。
其他方法


选择最终模型
模型比较
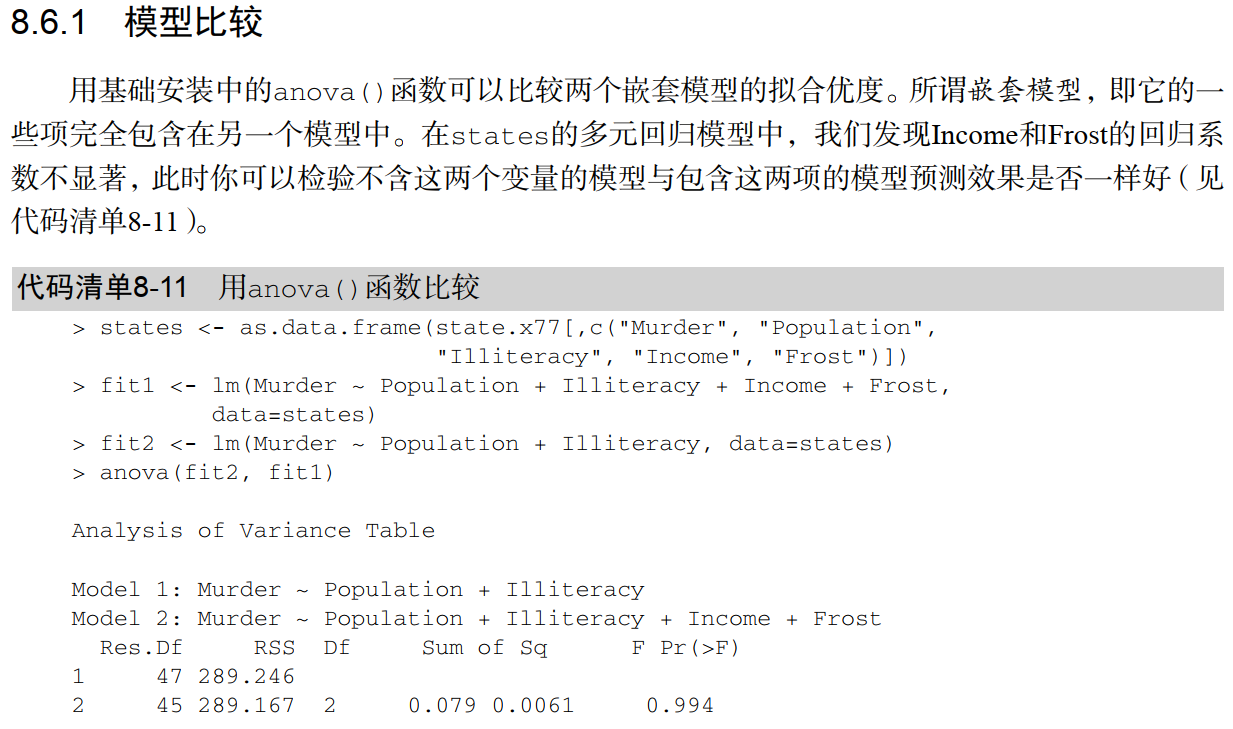



预测变量的选择




install.packages("leaps")
library(leaps)
states <- as.data.frame(state.x77[,c("Murder", "Population",
"Illiteracy", "Income", "Frost")])
leaps <-regsubsets(Murder ~ Population + Illiteracy + Income +
Frost, data=states, nbest=4)
plot(leaps, scale="adjr2")
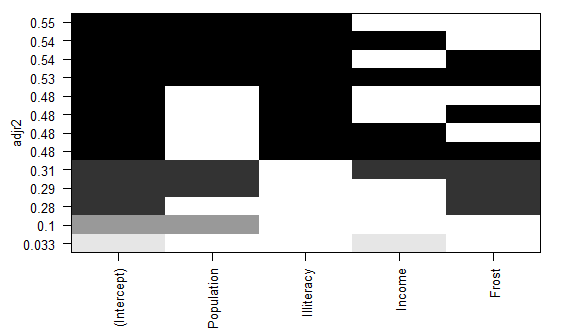
类似于热图的最上面的几行显示,当增加预测变量时,adjr2不会增加了,最大是0.55,增加预测变量反而使得
adjr2变小,所以两个预测变量用于线性回归是最好的选择。
线性回归和相关性的关系



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









