






- 实验目的:
- 掌握定性数据的描述性统计分析中常用的指标——频数和相对频率等;
- 掌握R语言绘制条图barplot()、饼图pie()和Pareto图的方法。
实验内容:
(习题3.1)一项研究资料表明,在美国市场,销售量在前 5名的软饮料分别是可口可乐、健怡可乐、百事可乐、雪碧和澎泉(Dr. Pepper ,美国的一种软饮料)。假设下表(略)中的数据(存放在SoftDrink.data 文件中)表示在只选择这 5种软饮料的情况下,抽取 50 次软饮料的购买样本。试计算每种饮料的频数和相对频率。
源代码:
# 读取数据
data <- read.table("C:/Users/黄培滇/Desktop/chap03/SoftDrink.data")
colnames(data) <- c("Consumers", "SoftDrink")
# 计算频数
f <- table(data$SoftDrink)
# 计算相对频率
rf <- prop.table(frequency)
# 输出结果
result <- data.frame(SoftDrink = names(frequency), 频数 = f, 相对频率 = rf)
print(result)
运行结果或截图:

(习题3.2)下表(略)中的数据(存放在 Crosstab.data 文件中)是对两个定性变量 x和y的30次观察值,x 的分类是A、B和C,y 的分类是1和 2。 (1) 做出数据交叉分组列表,以x为行、y为列;(2) 分别计算行百分比和列百分比。
(1)源代码:
# 读取数据
data <- read.table("C:/Users/黄培滇/Desktop/chap03/Crosstab.data")
colnames(data) <- c("x", "y")
# 数据交叉分组列表
cross_table <- table(data$x, data$y)
# 计算行百分比
row_percentage <- prop.table(cross_table, margin = 1) * 100
# 计算列百分比
column_percentage <- prop.table(cross_table, margin = 2) * 100
# 输出结果
result <- data.frame(x = rownames(cross_table), cross_table, RowPercentage = row_percentage, ColumnPercentage = column_percentage)
print(result)运行结果或截图:
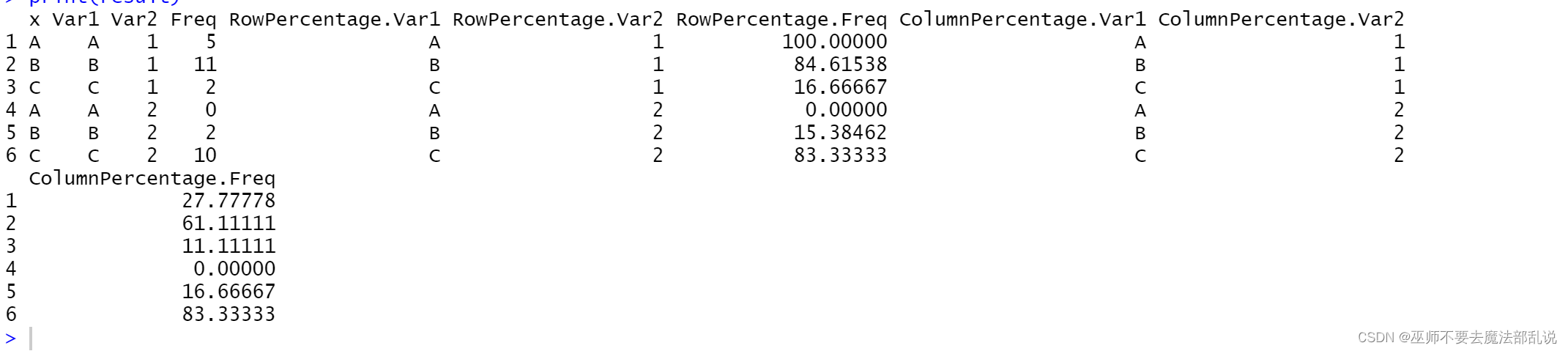
(2)源代码:
# 读取数据
data <- read.table("C:/Users/黄培滇/Desktop/chap03/Crosstab.data")
colnames(data) <- c("x", "y")
# 数据交叉分组列表
cross_table <- table(data$x, data$y)
# 计算行百分比
row_percentage <- prop.table(cross_table, margin = 1) * 100
# 计算列百分比
column_percentage <- prop.table(cross_table, margin = 2) * 100
# 输出结果
result <- data.frame(x = rownames(cross_table), cross_table, RowPercentage = row_percentage, ColumnPercentage = column_percentage)
print(result)运行结果或截图:
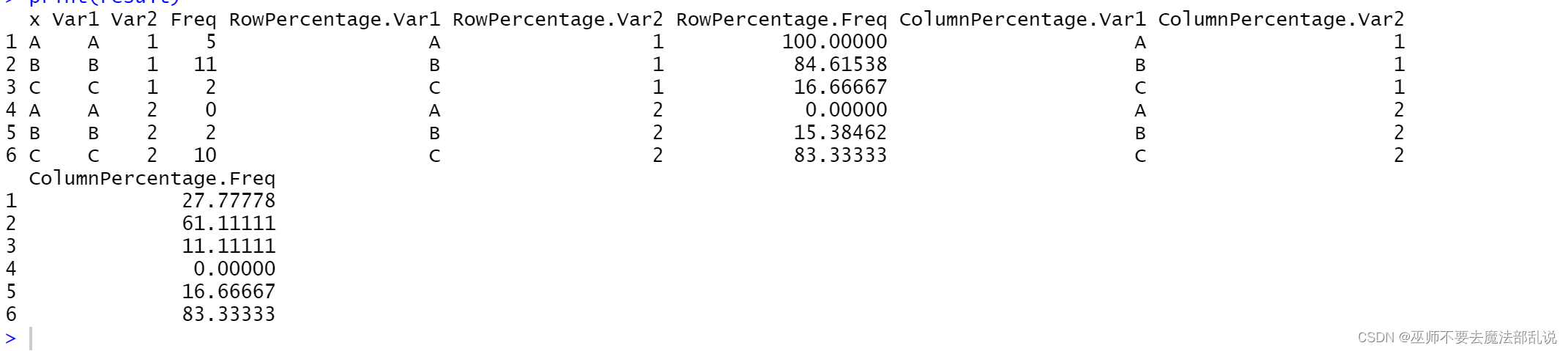
(习题3.3)一名动物学家正在做一项试验,调查在鸡食中加入抗生素后比没有抗生素的标准食物是否更能提高鸡的生长速度。从以前的研究中知道,通过8 周用标准饮料的喂养,一只鸡平均增重 3.9 g。动物学家选择了 100 只小鸡,为清除其他影响鸡增重的因素,将这些小鸡放在同一环境下饲养。下表(略,数据存放在 co ck.data 文件中)记录了 100 只鸡的增重。将小鸡增重数据分组,共分 14 组,每组的区间宽度为 0.lg ,从 3.55g 开始,至 4.95g 结束,并计算各组的频数和相对频率。
源代码:
# 读取数据
data <- scan("C:/Users/黄培滇/Desktop/chap03/cock.data")
# 计算区间宽度
width <- 0.1
# 计算组数
group_num <- ceiling((4.95 - 3.55) / width)
# 计算分组区间
intervals <- seq(3.55, 4.95, by = width)
# 将数据分组
groups <- cut(data, breaks = intervals, right = FALSE)
# 计算频数
X <- table(groups)
# 计算相对频率
Y <- prop.table(X)
# 输出结果
result <- data.frame(分组 = intervals[-length(intervals)], 频数 = X, 相对频率= Y)
print(result)运行结果或截图:
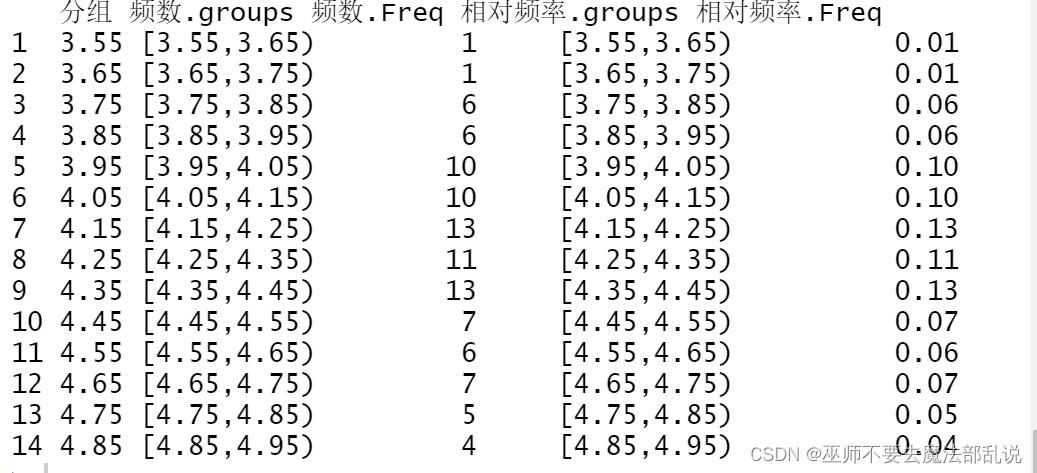
(习题3.4)下表(略,数据存放在 OccupSat.csv 文件中)给出对 4种职业进行了工作满意度研究的得分情况.工作满意度是通过一个包括 18 个问题的问卷调查表来测量的,每个问题对1至5分。18 个问题的得分总和就是样本中每个人的工作满意度分数,更高分数代表更大的满意度。(1) 将满意度分数分组,从 30 分至 90 分,每 10 分一组;(2) 做出职业与满意度分数(按分组数据)的交叉分组列表;(3) 关于这些职业的满意度水平,你能得出什么观察结果?
(1)源代码:
# 读取数据
data <- read.csv("C:/Users/黄培滇/Desktop/chap03/OccupSat.csv")
# 将满意度分数分组
data$满意度分数组 <- cut(data$满意度分数, breaks = seq(30, 90, by = 10), include.lowest = TRUE)
# 做出职业与满意度分数(按分组数据)的交叉分组列表
cross_table <- table(data$职业, data$满意度分数组)
# 打印交叉分组列表
print(cross_table)
运行结果或截图:

(2)源代码:
# 读取数据
data <- read.csv("C:/Users/黄培滇/Desktop/chap03/OccupSat.csv")
# 将满意度分数分组
data$满意度分数组 <- cut(data$满意度分数, breaks = seq(30, 90, by = 10), include.lowest = TRUE)
# 做出职业与满意度分数(按分组数据)的交叉分组列表
cross_table <- table(data$职业, data$满意度分数组)
# 打印交叉分组列表
print(cross_table)运行结果或截图:

(3)观察结果:
1.理疗师、律师和系统分析师的满意度分数分布相对平均,而木工的满意度分数主要集中在50-70分之间。
2.律师和理疗师分别在满意度分数为40-50分和70-80分之间有比较高的频率。
3.三个职业(理疗师、律师和木工)中,满意度分数最低的都是在30-40分之间。
4.系统分析师在满意度分数为60-70分之间有一个峰值,但是满意度分数最高只有60-70分之间,比其他职业都低。
(习题3.5)画出习题 3.1中每种饮料频数的条形图、相对频率的饼图,以及Pareto 图。
源代码:
#读取数据
drink<-scan("C:/Users/黄培滇/Desktop/chap03/drink.data",what = list(顾客性别="",饮料类型=""))
#计算频数和相对频率
Ta<-table(drink$饮料类型)
prop<-prop.table(Ta)*100
#绘制频数条形图
barplot(Ta,legend.text=c("男","女"),
args.legend = list(x="topleft"),
xlab="饮料类型",ylab="频数" )
r<-barplot(Ta,beside=T,
legend.text=c("男","女"),
args.legend=list(x=3,y=8),
xlab="饮料类型",ylab="频数")
text(r,Ta/2,Ta)
#绘制相对频率饼图
labels <- paste0(names(Ta), ": ", round(prop, 2), "%")
pie(Ta, radius = 0.9, labels = labels,
col = rainbow(length(Ta)), font = 2, cex = 1.2)
#绘制Pareto图
source("C:/Users/黄培滇/Desktop/chap03/exa_0301.R")
source("C:/Users/黄培滇/Desktop/chap03/pareto_chart.R")
pareto_chart(Ta,xlab="饮料类型")运行结果或截图:
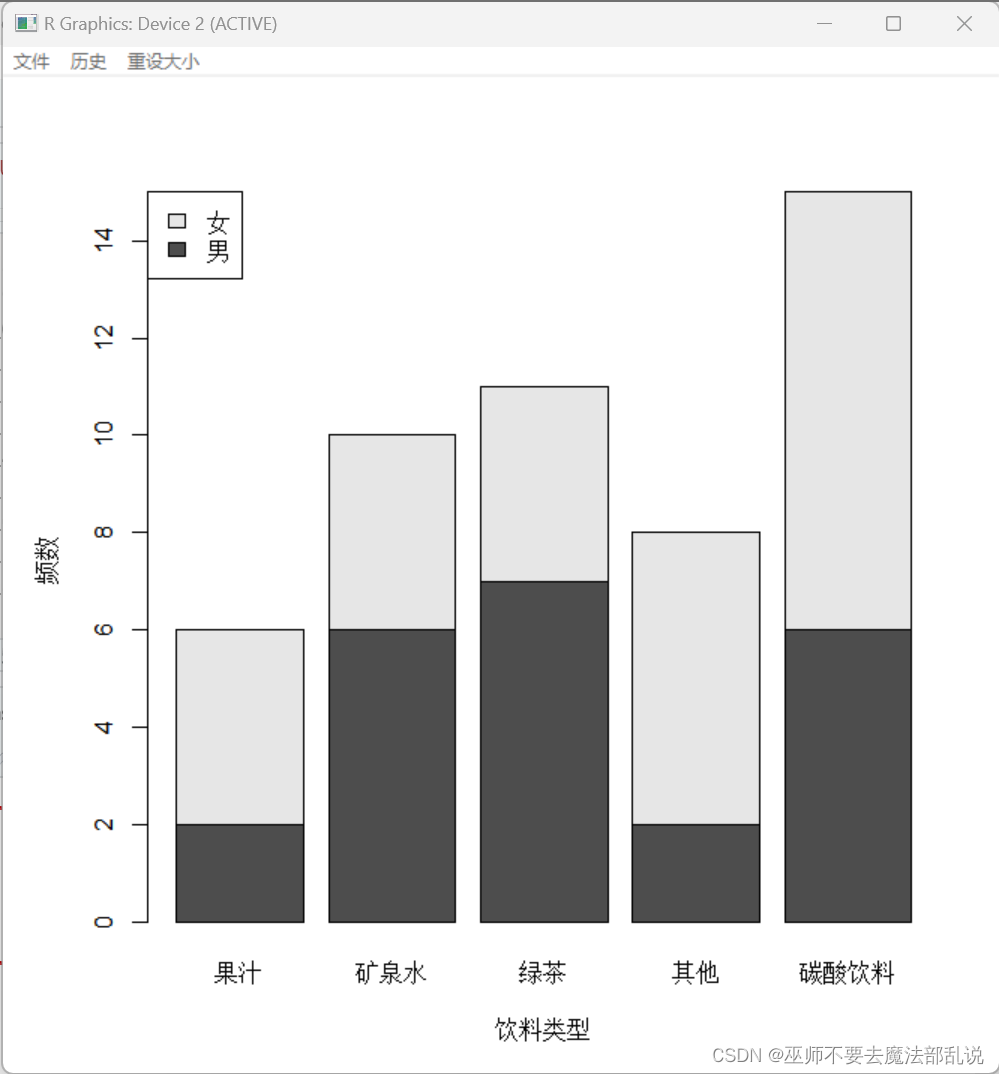
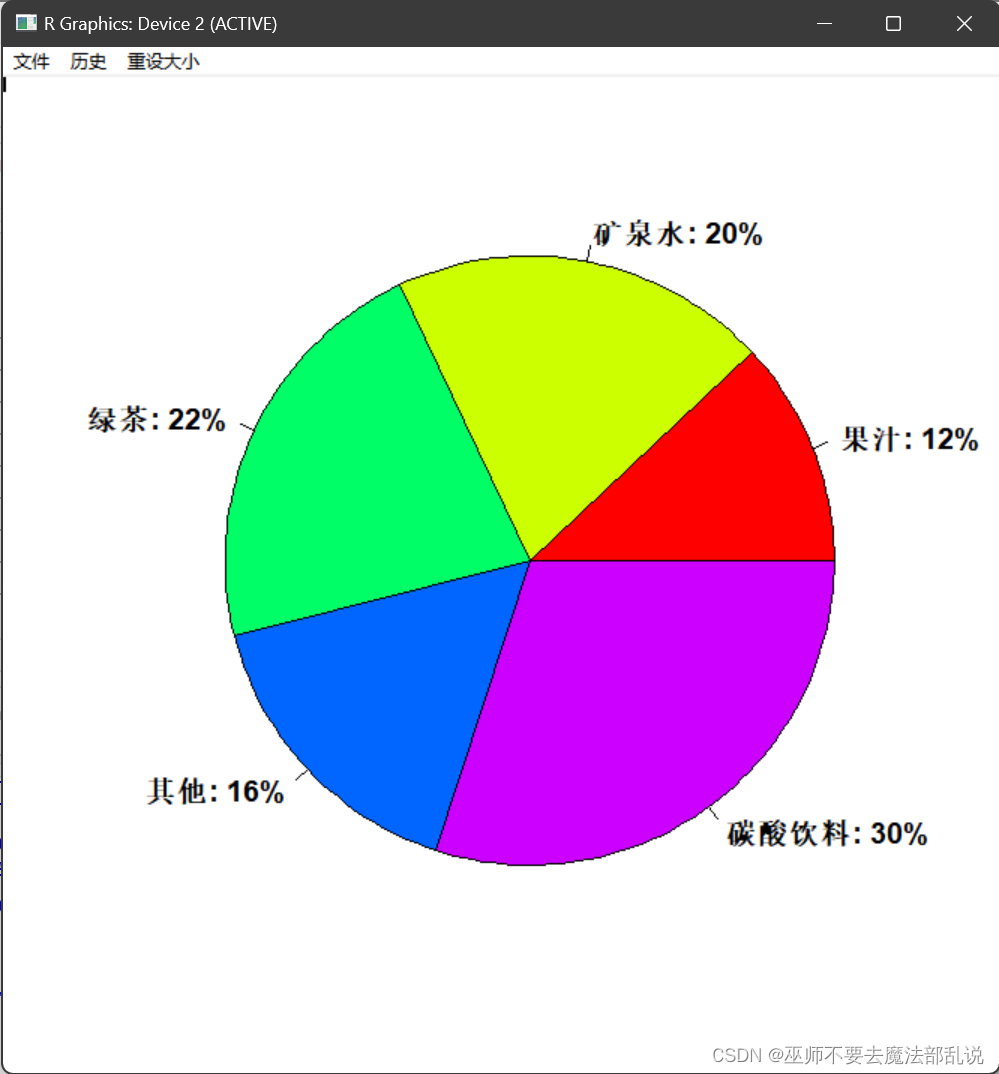
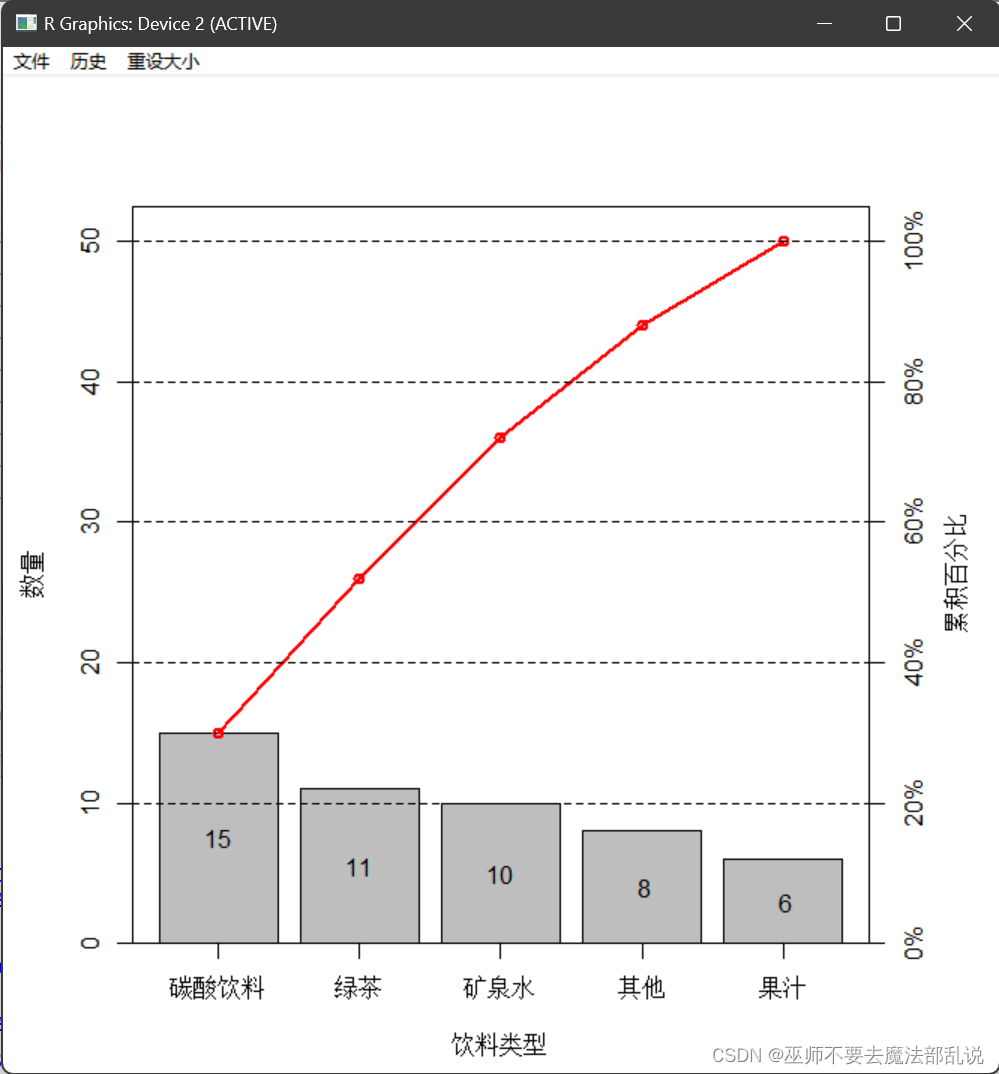
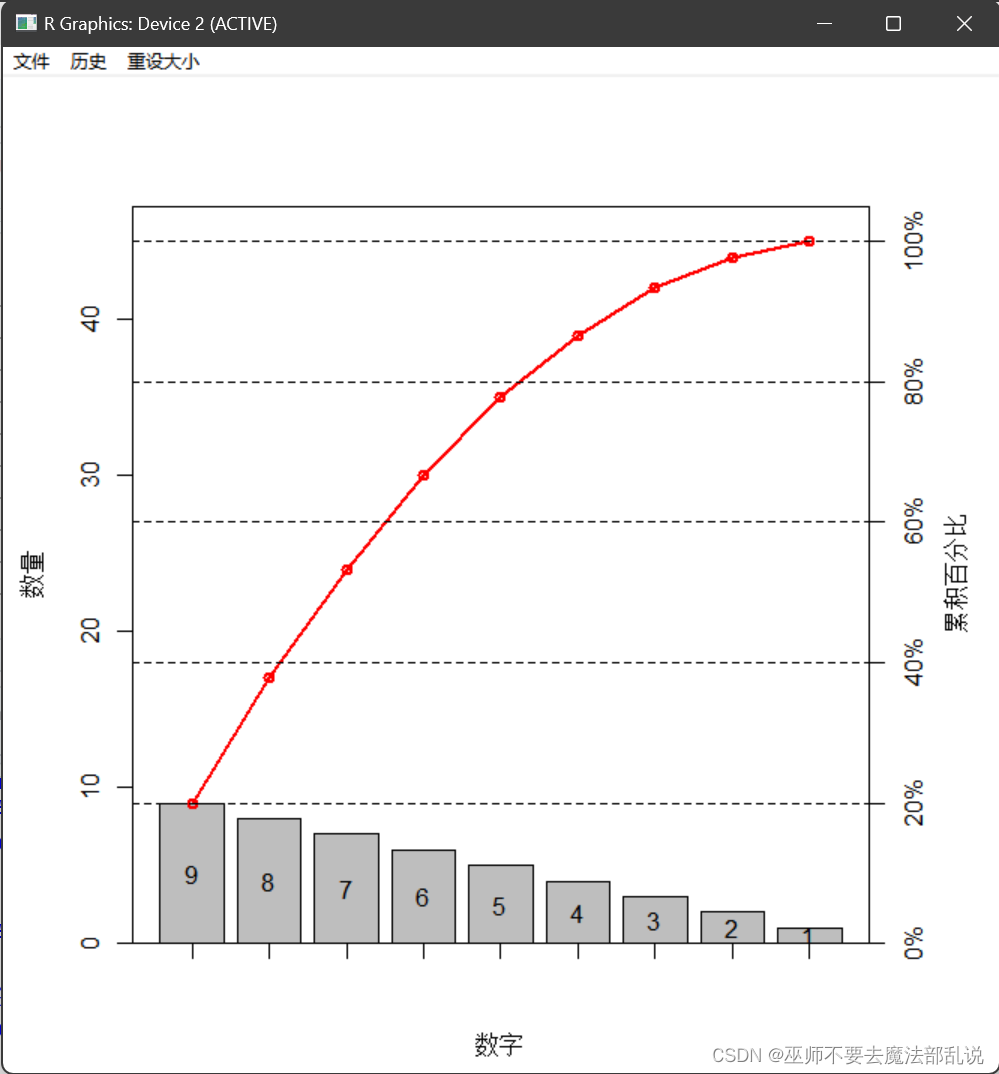
(习题3.6)Benford(本福德)数字法则。在随机选取数字时,1~9 中某些数字作为第 1个有效数字比其他数字更可能出现,例如,法则预测数字 1可以作为第 1个数字出现占 30%。 在关于Benford 法则的一项研究中,要求 743 名大学生随机地写出 6位数,下表记录了每个数的第一个有效数字及其分布汇总。(1) 试画出第一个数字频数的条形图和相对频率的饼图;(2) 用Pareto 图描述“随机猜测”数据的第一个数字,并说明这个图能否支持 Benford 法则的观点。
第一个数字及相应的次数
| 第一个 | 出现的 | 第一个 | 出现的 | 第一个 | 出现的 |
| 1 | 109 | 4 | 99 | 7 | 89 |
| 2 | 75 | 5 | 72 | 8 | 62 |
| 3 | 77 | 6 | 117 | 9 | 43 |
(1)源代码:
# 创建数据框
data <- data.frame(
数字 = c(1, 2, 3, 4, 5, 6, 7, 8, 9),
次数 = c(109, 75, 77, 99, 72, 117, 89, 62, 43)
)
# 计算相对频率
data$频数 <- data$次数 / sum(data$次数)
# 绘制第一个数字频数的条形图
barplot(data$频数, names.arg = data$数字,
xlab = "第一个数字", ylab = "频数",
main = "数字条型图")
# 绘制相对频率的饼图
labels <- paste0(data$数字, ": ", round(data$频数 * 100, 1), "%")
pie(data$次数, labels = labels,
col = rainbow(length(data$数字)), font = 2, cex = 1.2)运行结果或截图:
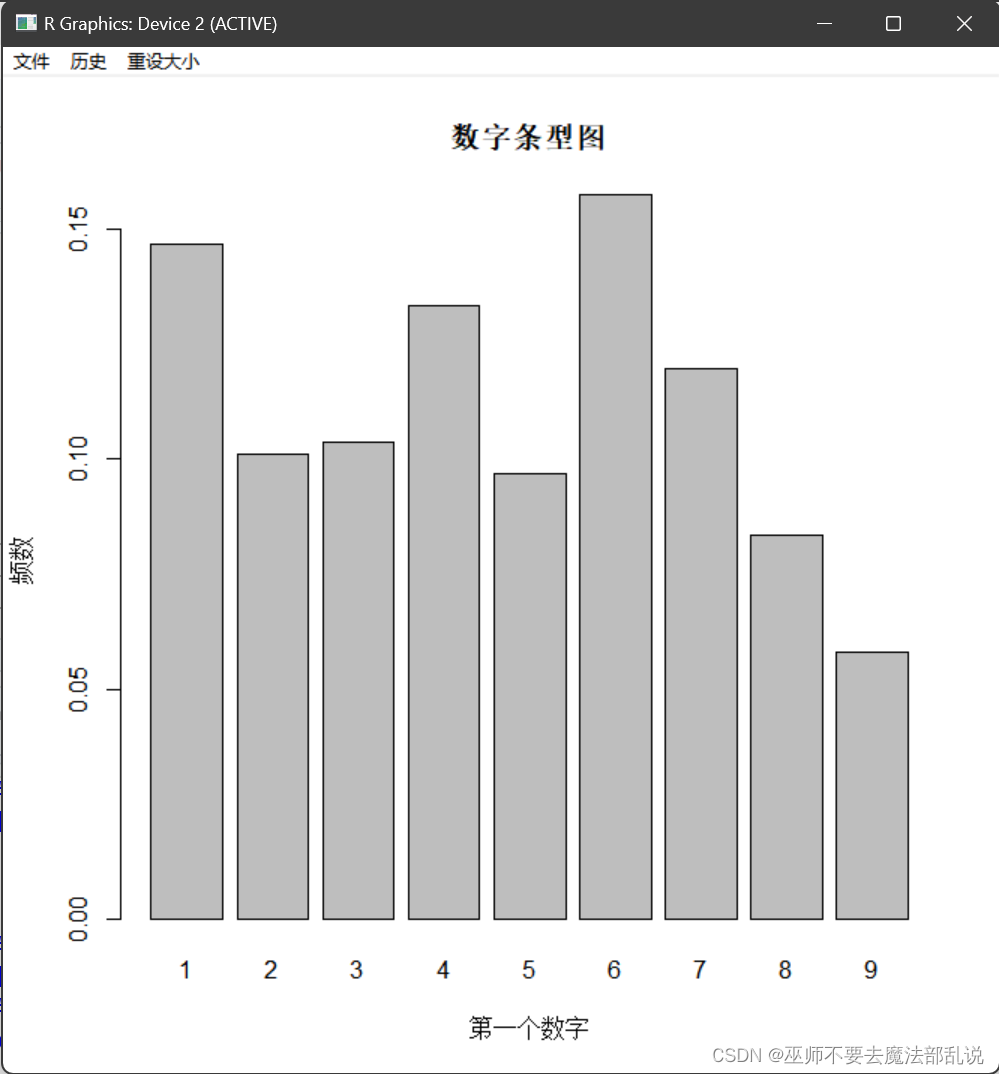
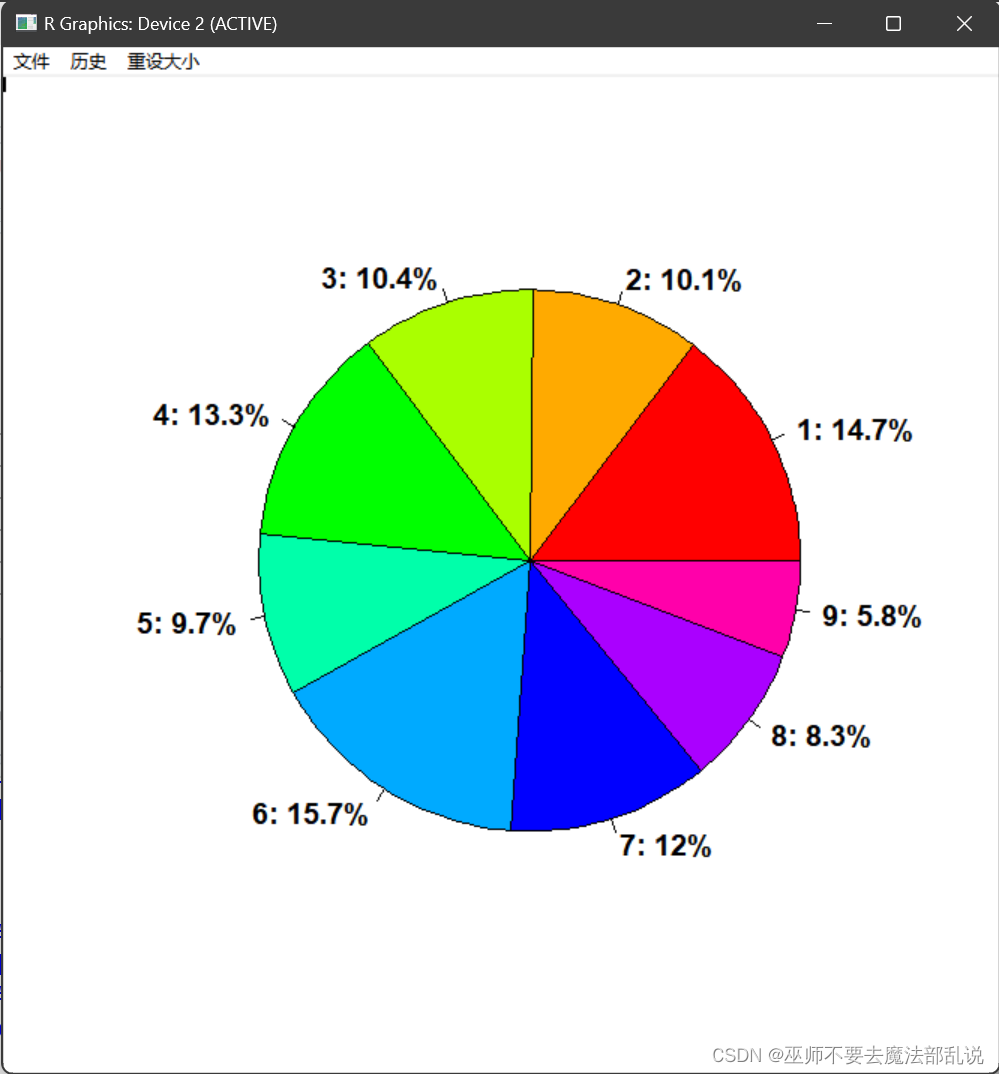
(2)源代码:
# 创建数据框
data <- data.frame(
数字 = c(1, 2, 3, 4, 5, 6, 7, 8, 9),
次数 = c(109, 75, 77, 99, 72, 117, 89, 62, 43)
)
# 计算相对频率
data$频数 <- data$次数 / sum(data$次数)
# 绘制第一个数字频数的条形图
barplot(data$频数, names.arg = data$数字,
xlab = "第一个数字", ylab = "频数",
main = "数字条型图")
# 绘制相对频率的饼图
labels <- paste0(data$数字, ": ", round(data$频数 * 100, 1), "%")
pie(data$次数, labels = labels,
col = rainbow(length(data$数字)), font = 2, cex = 1.2)
#绘制Pareto图
source("C:/Users/黄培滇/Desktop/chap03/exa_0301.R"),
source("C:/Users/黄培滇/Desktop/chap03/pareto_chart.R")
pareto_chart(data$数字,xlab="数字")运行结果或截图:
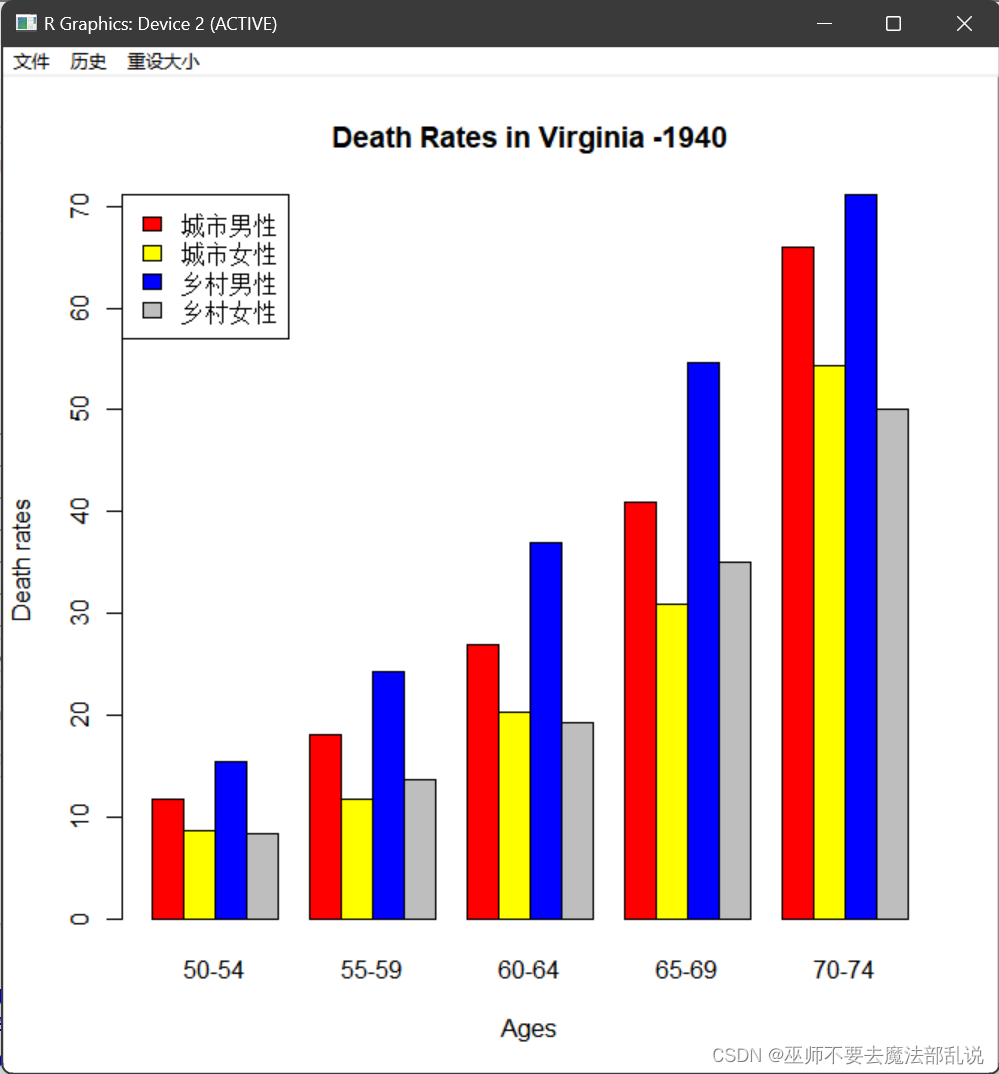
利用R自带的数据集VADeaths,绘制条图(可利用data()函数查看所有R自带的数据集)。VADeaths是1940年弗吉尼亚州分年龄组、地区和性别的死亡率数据。在命令行中输入VADeaths,就可以查看到,其数据如下:
Rural Male Rural Female Urban Male Urban Female
50-54 11.7 8.7 15.4 8.4
55-59 18.1 11.7 24.3 13.6
60-64 26.9 20.3 37.0 19.3
65-69 41.0 30.9 54.6 35.1
70-74 66.0 54.3 71.1 50.0
我们准备按年龄分组,用条图显示不同地域(城市、乡村)不同性别(男性、女性)的死亡率。请直接使用barplot()函数绘制条图,并将条图截图粘贴于下:
# 读取VADeaths数据集
data(VADeaths)
# 创建一个矩阵,按年龄分组,行表示年龄组,列表示地域和性别
D <- matrix(c(VADeaths[,"Rural Male"], VADeaths[,"Rural Female"],
VADeaths[,"Urban Male"], VADeaths[,"Urban Female"]),
nrow = 5, ncol = 4, byrow = TRUE,
dimnames = list(c("50-54", "55-59", "60-64", "65-69", "70-74"),
c("Rural Male", "Rural Female", "Urban Male", "Urban Female")))
# 绘制条形图
barplot(D, beside = TRUE,
main = "不同地区和性别的死亡率",
xlab = "年龄组", ylab = "死亡率")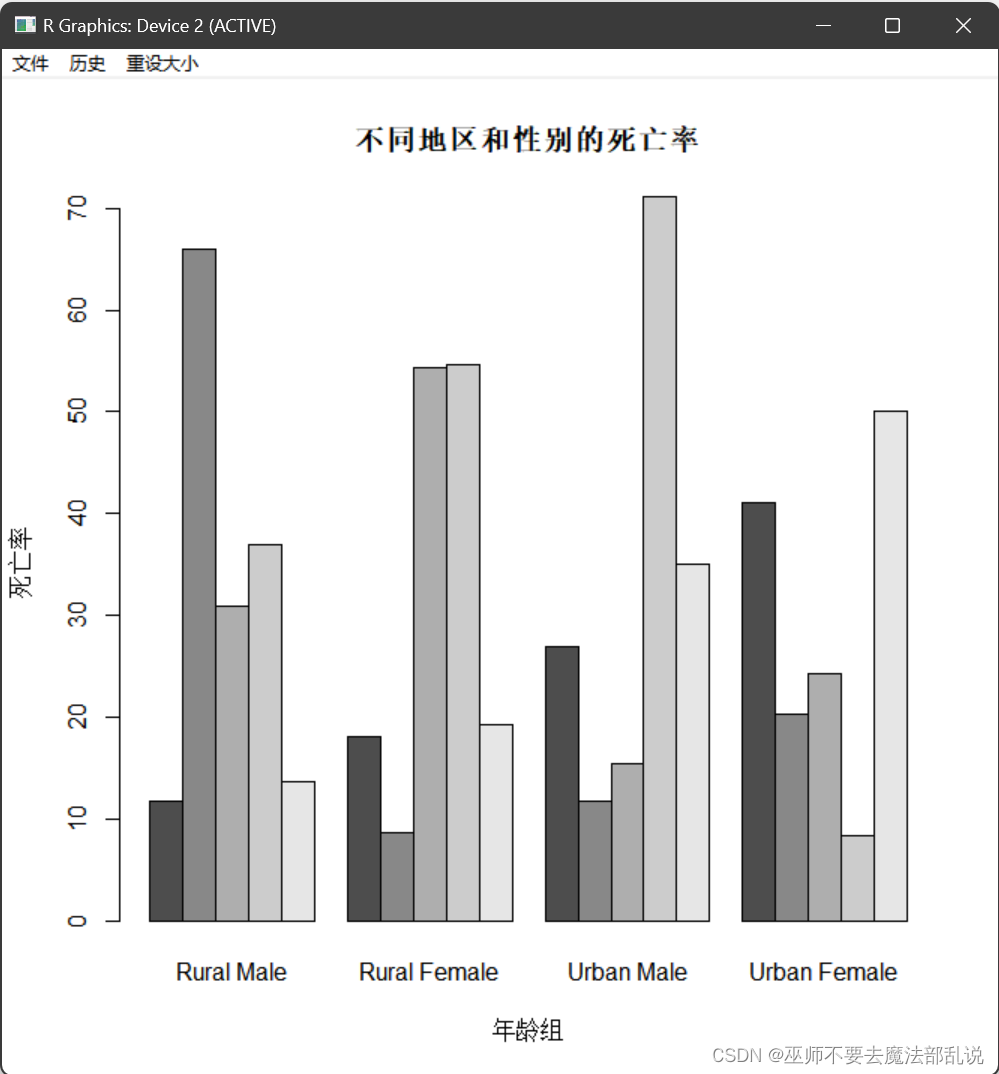
可以看到,barplot()默认是按列分组画条图,为此我们需要对原始数据VADeaths进行转置(利用t()函数)。请运行以下代码:
barplot(t(VADeaths),beside=T,legend=T, main="Death Rates in Virginia -1940")
请在下面粘贴运行上述代码生成的条图:
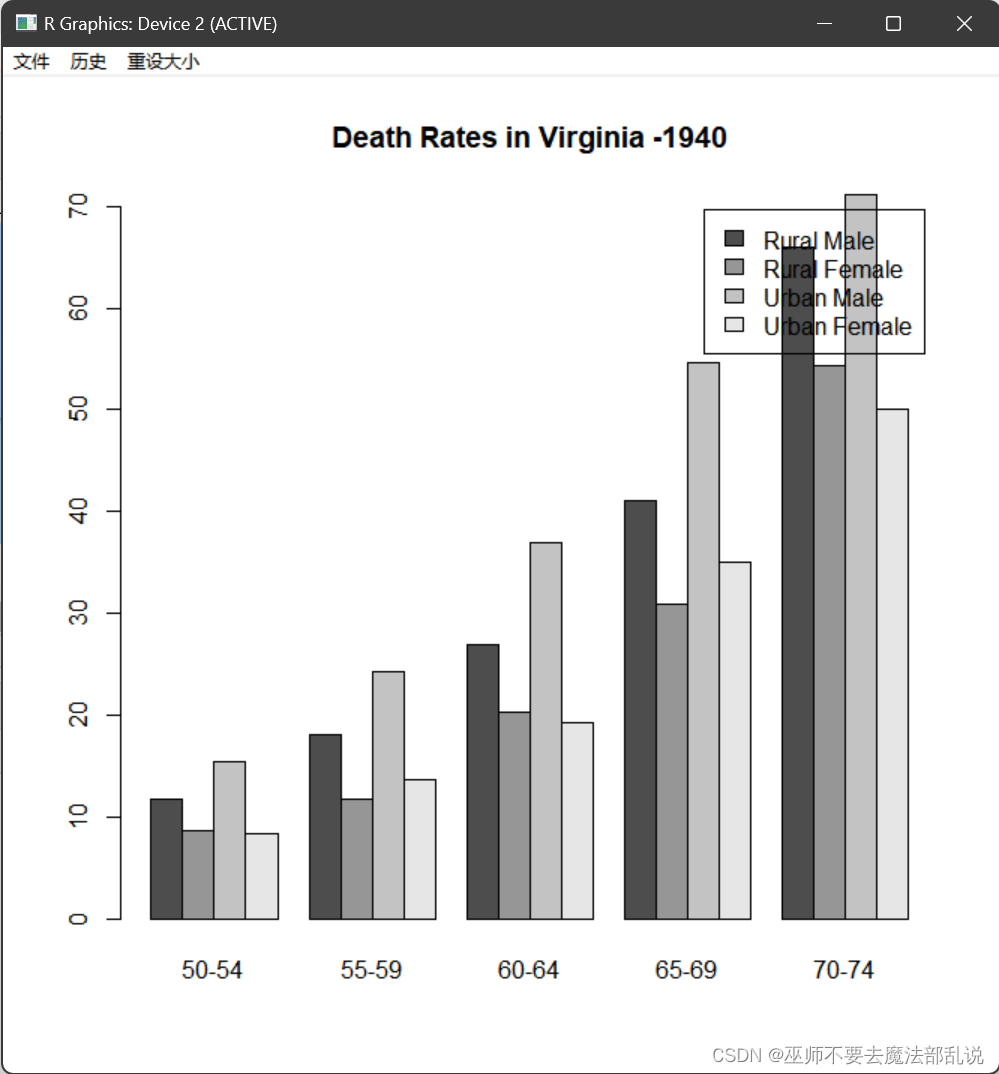
可以看到,右上角的图例部分与较高的条图重叠。
解决办法是对args.legend参数进行设置。如args.legend=list(x="topleft"),(也可以利用c()函数,即args.legend=c(x="topleft"))。
也可以直接设置图例的坐标,如args.legend=c(x=25,y=68),其中x, y表示图例右上角在整幅图中的坐标。如果不知道x 和y 的具体位置,可使用locator(1) 在图形中选择。具体方法是,在命令行中输入locator(1),然后把鼠标在图形显示区域中想要放置图例的地方点击一下,就能获取到所点击的位置的坐标(作为图例右上角坐标)。最后将得到的坐标值赋给args.legend中的x, y即可。
其余参数的设置:
利用参数col对条图的颜色进行自定义。如col=c("red","yellow","blue","grey"),或者col=rainbow(4)。如需更多颜色名称,可以“R语言颜色”为关键字自行在网上搜索。
利用参数xlab="Ages",ylab="Death rates",对横轴和纵轴赋予名称。
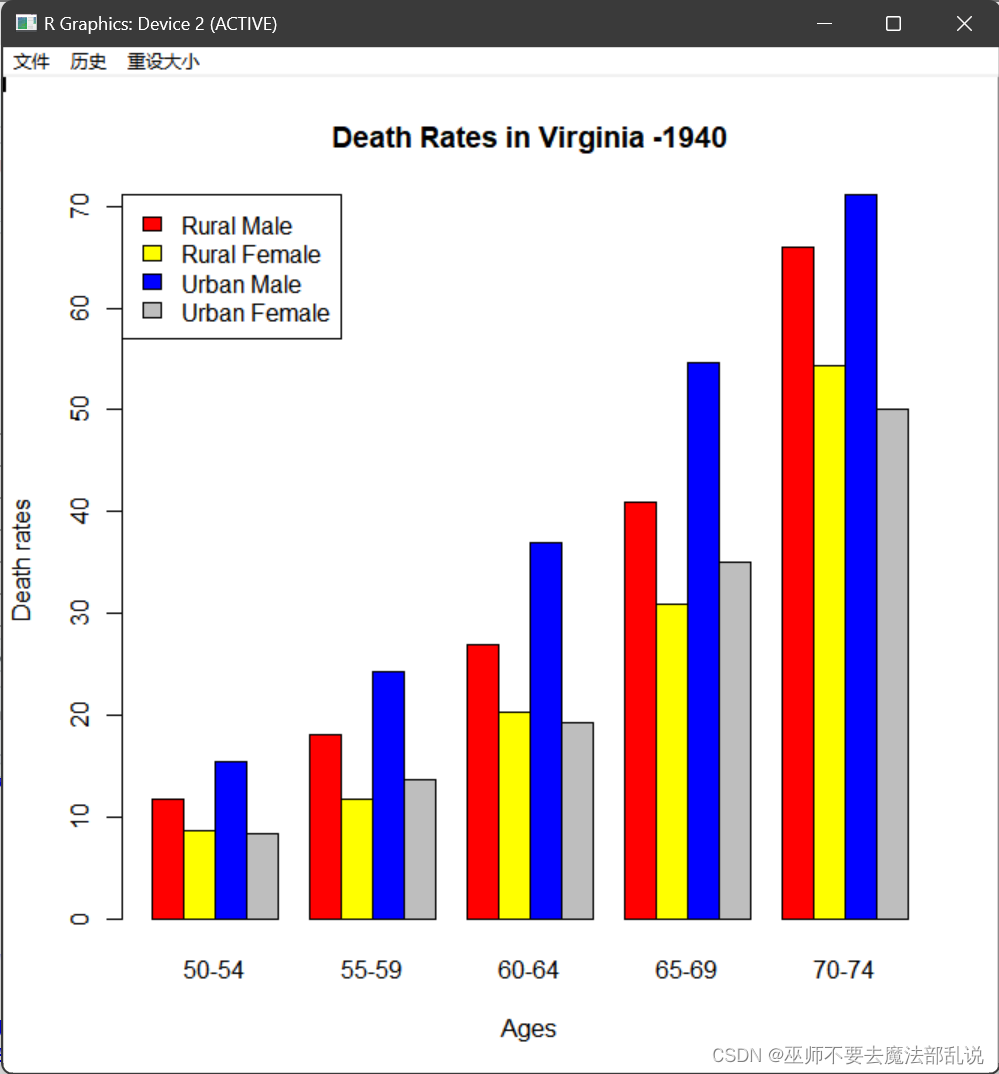
请按默认年龄组从小到大,将生成的条图的代码及截图粘贴于下:
源代码:
# 读取VADeaths数据集
data(VADeaths)
# 创建一个矩阵,按年龄分组,行表示年龄组,列表示地域和性别
D <- matrix(c(VADeaths[,"Rural Male"], VADeaths[,"Rural Female"],
VADeaths[,"Urban Male"], VADeaths[,"Urban Female"]),
nrow = 5, ncol = 4, byrow = TRUE,
dimnames = list(c("50-54", "55-59", "60-64", "65-69", "70-74"),
c("Rural Male", "Rural Female", "Urban Male", "Urban Female")))
# 绘制条形图
barplot(t(VADeaths),
beside=T,legend=T,
col=c("red","yellow","blue","grey"),
args.legend=list(x="topleft"),
main="Death Rates in Virginia -1940",
xlab="Ages",ylab="Death rates")运行结果或截图:
如果把legend=T 换成legend.text=c("城市男性","城市女性","乡村男性","乡村女性"),看看有什么变化?
左上角注释信息变成中文
注:
绘制Pareto图,还可以使用第三方的程序包,如: qicharts包中的paretochart()函数,qualityTools包中的paretoChart()函数,qcc包中的pareto.chart()函数等。
若想制作三维饼图,可以使用第三方程序包,如:plotrix包中的pie3D()函数可以创建三维饼图。可自行下载并安装plotrix包,查看pie3D()函数的用法,绘制出上述几题的三维饼图。
思考:
统计分析包括哪两个方面的分析?
描述统计分析;推断统计分析
scan()函数读取多个属性的数据时,要用到的一个重要参数是?
what参数
描述定性数据的指标主要有哪两个?R中涉及的函数主要有哪三个?
描述定性数据指标主要有“频数”、“比例”,R中相关函数:table(),prop.table(),barplot()
cut()函数的返回值是什么数据类型?
返回值为factor(因子)类型















 673
673











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









