







Multi-View Saliency Guided Deep Neural Network for 3-D Object Retrieval and Classification 是2020年发表在IEEE transaction on multimedia 上的论文。
这篇论文的目的是解决以下两个问题
- 如何充分利用多视角语境信息,同时实现代表性视图的选择和相似性度量
- 如何在没有特定摄像机设置的情况下发现多视图序列的判别结构
这篇论文的贡献
- 提出了用于三维对象检索和分类的MVSG-DNN,它可以通过利用多视图上下文来同时实现代表性视图的选择和相似性测度。
- 在不需要特定摄像机设置的情况下,MVSG-DNN可以发现每个三维物体的判别结构特征。 这个方法可以更实际地应用于实际应用。
一 网络的整体结构
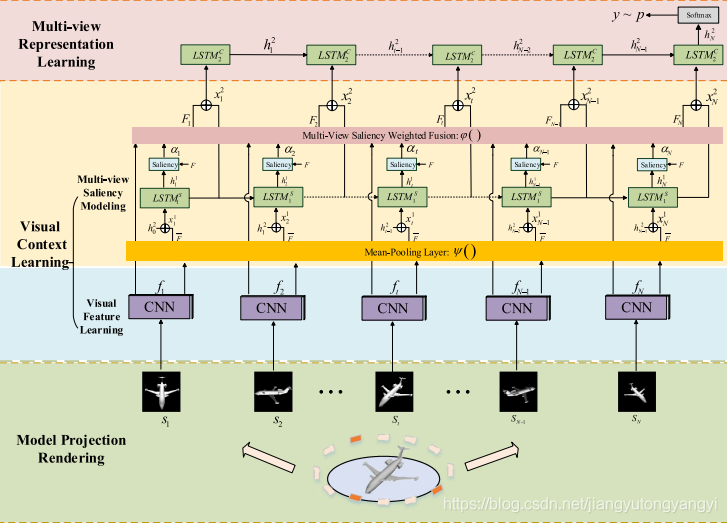 这个方法用于这两种任务的多视点显着性引导深度神经网络(MVSG-DNN。第一个模型投影渲染模块 用于捕获一个3D对象的多个视图。 第二视觉语境学习模块用于探索多个视图之间的相关性,第三个多视图表示学习模块用于计算用于检索的成对对象之间的相似性,也可与Softmax函数一起用于分类。
这个方法用于这两种任务的多视点显着性引导深度神经网络(MVSG-DNN。第一个模型投影渲染模块 用于捕获一个3D对象的多个视图。 第二视觉语境学习模块用于探索多个视图之间的相关性,第三个多视图表示学习模块用于计算用于检索的成对对象之间的相似性,也可与Softmax函数一起用于分类。
二 Model Projection Rendering(模型投影渲染模块)


针对不同的视点设置多个虚拟摄像机来捕获3D对象的视图。虽然视点(虚拟摄像机)可以任意选择,但是他们主要考虑两个有代表性的相机设置,有和没有直立的方向假设,就是说物体是竖直摆放和不是竖直摆放的。第一种有竖直摆放的,虚拟摄像机就围绕着物体360拍摄,如果每个视点相隔的角度是30,那么就有会有12视图。第二种就物体不是竖直摆放的,那么就不知道哪个角度的视图更具有代表性,作者就将12面体的20个顶点分别获取视图。
三 Visual Context Learning(视觉语境学习模块)

这个模块分为两部分:Visual Feature Learning、Multi-View Saliency Modeling
3.1 Visual Feature Learning
这部分他们选择AlexNet进行CNN特征提取,因为它可以在较少的参数下实现三维对象检索和分类的竞争性能。它有5个卷积层和3个全连接层。

网络的输入为:
其中si 是第一个投影渲染模块得到的多角度视图。N是多角度视图序列的个数。
网络的输出是D维的特征序列:
3.2 Multi-View Saliency Modeling
该模块旨在设计一种多视图显着性机制,通过探索多视图上下文,自适应地选择具有代表性的视图。

网络输入:

第一个公式是求所以视图的一个平均值,第二个公式的求某时刻状态的输入x1t 。其中h2t-1是classification LSTM的t-1时刻的输出。这个状态是classification LSTM的一个初始状态,作者想把classification LSTM和saliency LSTM的信息相互利用。这个我在读论文的时候不太明白,是联系到了作者,作者给我解答的(感觉有一点小骄傲呢 哈哈)。第三个公式就是正常的LSTM的输入。
然后计算每个视图的权重:

首先计算一组权重ai ,它是由h1t和fi 经过网络求出的。最后的Ft通过对ai 与h1t相乘求和算出。
四 Multi-View Representation Learning

他们使用最后一个隐藏状态H2N来测量成对3D对象之间的相似性,并将其与Softmax函数一起用于分类。P ∈RD是一个概率向量,d的维数与类别数相同。
五 数据集和评估标准
数据集:
- ModelNet10:contains 4,866 models from 10 categories.
- ModelNet40:consists of 12,311 CAD models from 40 categories
- ShapeNetCore55:consists of 51,300 3D objects from 55 common categories
评估标准:
- The Precision-Recall Curve (PR-Curve)
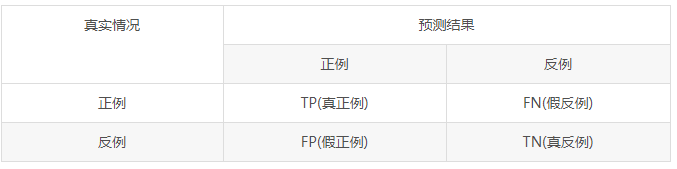
P代表查准率(Precision),又叫准确率,缩写表示用P。查准率是针对我们预测结果而言的,它表示的是预测为正的样例中有多少是真正的正样例。公式为:

R查全率(Recall),又叫召回率。查全率是针对我们原来的样本而言的,它表示的是样本中的正例有多少被预测正确。公式:

PR-Curve表示P-R曲线,以查准率为纵轴、查全率为横轴作图,就得到了查准率-查全率曲线,简称“P-R曲线”,显示该曲线的图称为“P-R图”。例如下图:

另外论文在实验中用到的P@N表示的是返回前N个结果的精确度。比如P@5,那么1,3,5正确,2,4错误,就是说明它的P=0.6=3/5.同理R@N - The First Tier (FT) 被用来计算顶级τ结果的召回率,其中τ是查询的相关对象的数量。
- The Second Tier (ST) 被用来计算顶级2τ结果的召回率,其τ是查询的相关对象数量。
- The Mean Average Precision (mAP)
首先要知道AP,准确率和召回率都只能衡量检索性能的一个方面,最理想的情况肯定是准确率和召回率都比较高。当我们想提高召回率的时候,肯定会影响准确率,所以可以把准确率看做是召回率的函数,即:P=f( R),也就是随着召回率从0到1,准确率的变化情况。那么就可以对函数P=f( R)在R上进行积分,可以求PP的期望均值。公式如下:

其中rel(k)表示第k个文档是否相关,若相关则为1,否则为0,P(k)表示前k个文档的准确率。 AveP的计算方式可以简单的认为是:

其中R表示相关文档的总个数,position®表示,结果列表从前往后看,第r个相关文档在列表中的位置。比如,有三个相关文档,位置分别为1、3、6,那么AveP=1/3×(1/1+2/3+3/6)。在编程的时候需要注意,位置和第i个相关文档,都是从1开始的,不是从0开始。
因为通常会用多个查询语句来衡量检索系统的性能,所以应该对多个查询语句的AveP求均值(the mean of average precision scores),即公式:

- The Discounted Cumulative Gain (DCG)
Cumulative Gain(CG):
表示前p个位置累计得到的效益,公式如下:

其中reli表示第i个文档的相关度等级,如:2表示非常相关,1表示相关,0表示无关,-1表示垃圾文件。
由于在CGp的计算中对位置信息不敏感,所以引入位置因素,有两种计算方式:


- The F_measure (F)
同时考虑准确率和召回率的指标。公式如下:

有一种变体,是考虑到准确率和召回率的各种所占的权重

另外在ShapeNetCore55上有两种评估方法macro-averaged(宏平均)、 micro-averaged metrics(微平均)
宏平均:对每个查询求出某个指标,然后对这些指标进行算术平均
微平均:将所有查询视为一个查询,将各种情况的文档总数求和,然后进行指标的计算
六 实验
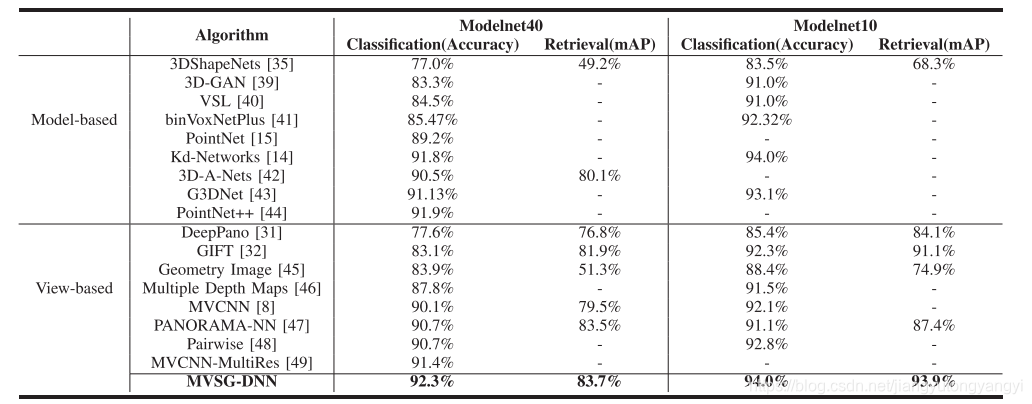
6.1 与现在最先进的技术相比
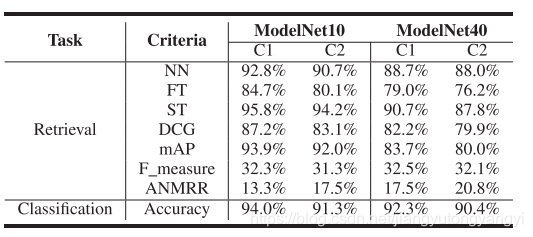
6.2 视图渲染性能比较
比较两个有代表性的相机设置,在他们的实验中,他们在第一种情况下(C1)将视图数设置为12,在第二种情况(C2)下设置为20。
6.3 隐态维度的敏感性分析
将显著性LSTM和分类LSTM的隐态维数设置为1024,可以达到最佳的性能.
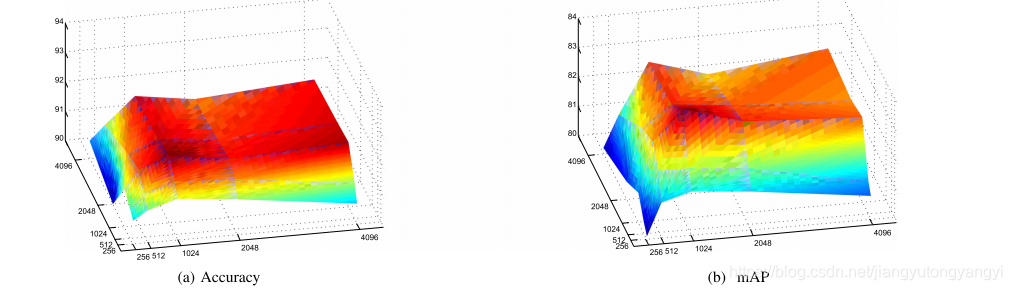
6.4 视图顺序的灵敏度分析
这些结果表明,多视图显着性机制可以自适应地计算单个视图的重要性,而不受特定顺序的约束。

6.5 视图数的灵敏度分析
最优视图数设置为12。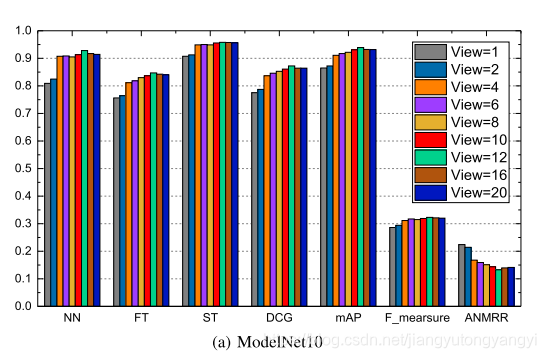
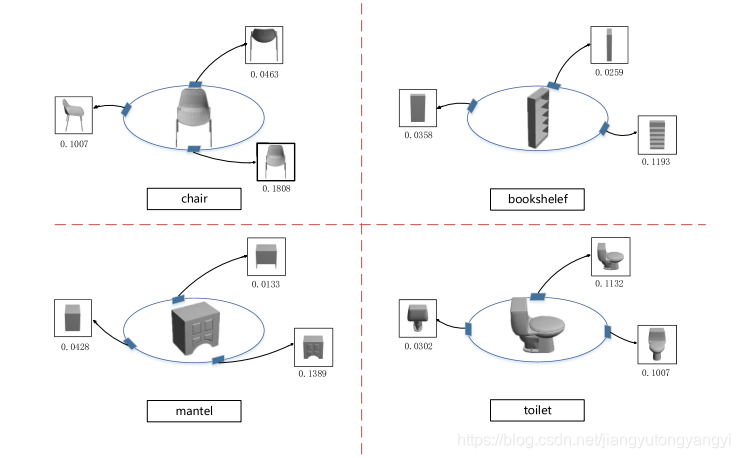
6.6 多视角显著性机制的定性分析
他们可视化了多个视图的显着性分数。包含更多视觉外观或结构特征的视图图像将被更重要地处理。
这个就是我对该论文的理解,对评价指标那部分知识我参考了https://blog.csdn.net/u010138758/article/details/69936041/博客,这个对信息检索中常用的评价指标写得很好值得以看。
想读这篇论文的原因是他们将LSTM用到了3D图像的检索和分类中,我感觉很新颖所以想读一读。最让我开心的是我几经波折后联系到了作者,把一些不会的问题搞懂了,作者真的是一个超级超级好的小哥哥。耐心的给我解答我不懂的地方,再此,对作者表示深深的感谢。














 1511
1511











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









