








文章目录
论文:TextMonkey: An OCR-Free Large Multimodal Model for Understanding Document
代码:https://github.com/Yuliang-Liu/Monkey
时间:2024.03
贡献:
- 专为文档理解任务做的模型
- 增强了跨窗口的关联:借鉴 Monkey 切分大分辨率图像的思路,TextMonkey 引入了 shfited window attention 来提升 cross-window 之间的关联,而且作者在 Shifted Window Attention 机制中引入了零初始化,使模型能够避免在早期训练中进行剧烈的修改。
- Token 数量压缩:因为提升分辨率后会引入一些冗余的 token,所以作者使用相似性作为判断标准,提取出重要的 token,用这些重要的 token 作为 query,这样能减小 token 的数量,提升模型速度,且比随机查询更好
- 支持文本定位:作者扩展了模型的功能,让模型能读取文本,识别文本,定位文本
一、背景
在之前的文档理解方法中,基本都使用的是两阶段的方法来实现的,这些两阶段的方法会导致错误累积:
- 第一阶段:检测和识别文本
- 第二阶段:基于文本识别的结果与图像一起来理解文档
相关工作:
OCR 模型驱动的相关工作:依赖于 OCR 模型额外的提取文本,会增加计算资源和耗时,可能会由于 OCR 模型的不准确导致文档理解有误
- OCR 模型驱动是使用 OCR 工具来获取文本和边界框信息,然后依靠模型来集成文本、布局、视觉数据,同时设计了不同的预训练任务来增强视觉和文本输入之间的跨模态对齐
- StrucTexT
- ERNIE-Layout
- LayoutLM
- UDOP
- Wukong-reader
- DocFormerv2
- DocLLM
OCR-free 的相关工作:不需要现成的 OCR 模型
- Donut:第一个提出了基于 Transformer 的 OCR-free 的端到端训练方法
- Dessurt:融合了双向交叉注意力并采用了不同的预训练方法
- Pix2Struct:引入了可变分辨率的输入表示和更灵活的方式来集成语言和视觉输入
- StrucTexTv2:引入了新的自监督预训练框架
- 上面几个模型虽然不需要 OCR tools,但还是需要在特定的任务上进行微调
- LLaVAR [7], mPLUG-DocOwl [10] and UniDoc [8] 都建立了新的指令跟随数据集来提升模型对 text-rich 图像的理解
- 还有一些方法通过捕捉更多的图像纹理信息来提升效果,
- 如 UReader 设计了一个 shape-adaptive cropping 模型,来在高分辨输入的条件下使用低分辨率输入的预训练模型。
- DocPedia 将输入图像处理成了频域来降低 visual token。
- Vary 通过提升视觉词汇量来提升输入分辨率
- TGDoc 使用 text-grounding 来提升对文档的理解,表明在文本上进行 grounding 能够提升模型对文本的理解能力。
额外的引入现成的 OCR model 或 API 也会引入额外的计算量和复杂性,限制了文本与其周围上下文之间的联系,所以 OCR-Free 的方法引起了大家的关注
LMM 方法虽然发展迅速,但也有一定的问题,比如 LLaVAR [7], UniDoc [8], TGDoc [9], mPLUG-DocOwl [10] 这些方法严重依赖于预训练好的 CLIP 来做视觉编码,但 CLIP 的视觉 encoder 的输入是 224 或 336,文档数据包含很多小的文字,所以小分辨率的输入难以支持文档中的小文字
因此,UReader [13] 和 Monkey [14] 提升了输入分辨率,如图 1b,但是这种直接切分图像的方法可能会切到单词,导致语义不连贯,比如将 ”backup" 切分为 “back” 和 “up”,这样就会改变语义,然后导致和位置相关的任务(grounding)错误。
如图 1c,DocPedia 直接将输入变换到了频域,频域可以在不损失信息的情况下快速扩展分辨率,但是使用了频域变换后就难以使用现有的预训练模型。
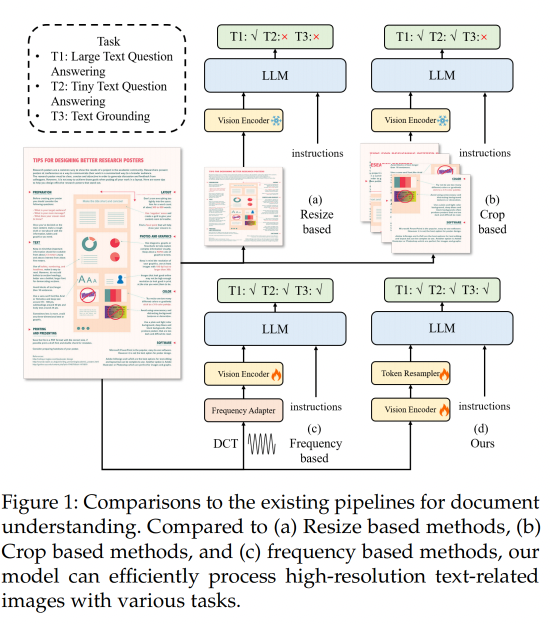
作者提出 TextMonkey 的出发点:继承 Monkey 的高效图像分辨率缩放特性,但能够解决由于切分 patch 导致的的跨 patch 的信息丢失
TextMonkey 的特点:
- 使用 Shifted Window Attention 建立 cross-window 之间的联系:
- 作者使用 Split Module 将高分辨率图片切分成 window patches
- 此外,还参考 Swin Transformer,作者将 CLIP 中的 self-attention layer 看做无重叠窗口之间的 self-attention。然后又额外引入了 Shifted Window Attention (zero-initialization)来建立 cross-window 的联系。
- 这样的操作能在处理高效处理高分辨率输入的同时建立不 patch 之间的联系
- 提出了 token 重采样来压缩图像特征,同时尽可能多的保留最重要的特征,然后使用重要的 token 作为 query,原始的特征作为 key-value pairs,促使特征重新聚合
- 使用 Split Module 拆分 patch 后会导致 token 的长度显著增加,且有许多重复的图像特征对应的语言空间一致(某些特征(比如纹理、形状、颜色块等)可能会在不同的位置重复出现。这与语言中的某些元素(如常见的单词或短语)重复出现是相似的。在图像中,这种重复的特征可能不需要每一处都被单独表示,因为它们不增加新的信息。)
二、方法
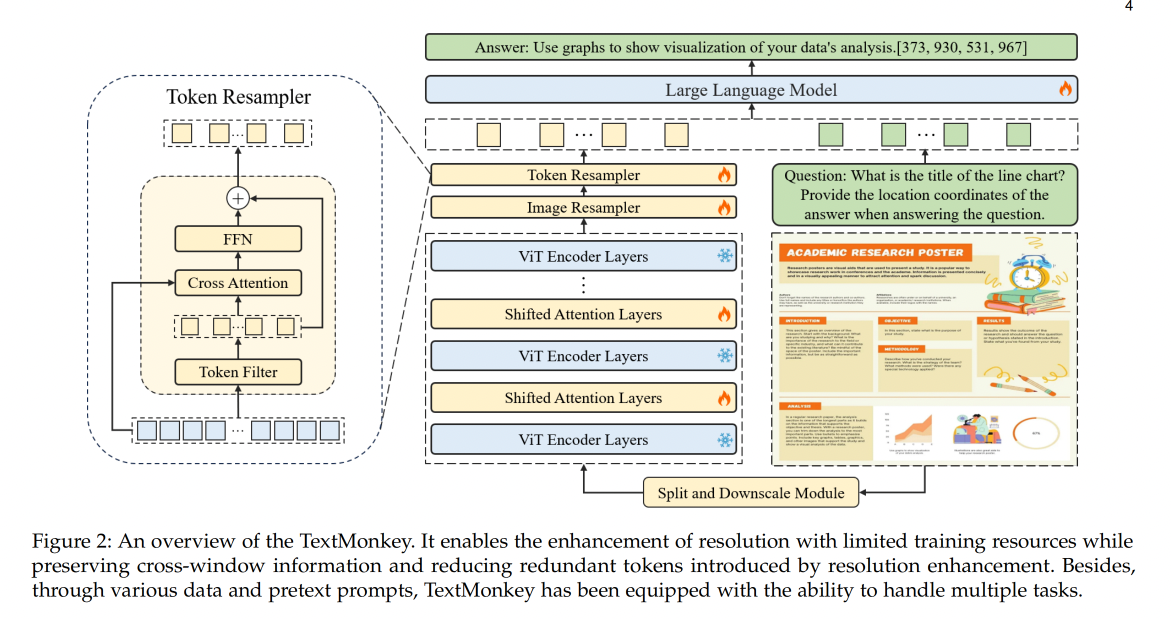
本文方法结构图如图 2 所示:
- 首先:使用 sliding window 将输入图像切分成无重叠的 patches(其实也是 window),patch 大小为 448x448,然后这些 patch 会被进一步细分为 14x14 的更小的 patches,每个小的 patches 被视为一个 token,然后在每个 window 内部使用预训练好的 CLIP model 来提取特征。为了建立不同 window 的连接,在 Transformer block 之间会使用 Shifted Window Attention
- 接着:为了生成层级式的表示,输入的原图会 resize 到 448x448 大小后输入 CLIP 中来抽取全局特征,并且将全局特征和每个 patch 的特征一起送入 shared image resampler 用于和 language domain 对齐
- 然后,输入 Token resampler 中,通过压缩 token 的长度来进一步最小化在 language space 中的冗余
- 最后,将得到的特征和输入的文本问题一起送入 LLM 中,得到最终的回答
2.1 Shifted Window Attention
对于输入图像 I,首先先使用 sliding window KaTeX parse error: Undefined control sequence: \time at position 14: W \in R^{H_v \̲t̲i̲m̲e̲ ̲W_v} 将图像切分成不重叠的块儿,在每个 window 内部,都使用 CLIP 的 transformer block 来提取特征,但这样就忽略了 cross-window 之间的关联
为了建立不同 window 之间的关联,作者借鉴了 swin transformer 中的 Shifted Window Attention,且为了让模型在开始训练时更加稳定,这些 shifted window 的参数都是使用全零来初始化的
2.2 Image Resampler
在所有 vit encoder 执行完后,作者使用了类似 Qwen-VL 中提出的 image resampler,其中,使用一系列可训练的参数作为 query,visual encoder 得到的 image feature 作为 key 和 value,然后做 cross-attention 操作
image resampler 操作之后,能够将 visual feature 压缩到固定的长度,也就是 256(2d 绝对位置编码也被集成到了 query-key pairs)
2.3 Token Resampler
随着分辨率的提升, token 的数量也会增加,但是很多 language model 的输入长度是有限的,所以减少 token 的个数很重要
对于自然语言,冗余信息是重复的语言元素,那么提升图像的分辨率后,同样也会存在冗余信息,所以作者会同时度量语言元素之间的相似度和图像特征之间的相似度,而且图像特征之间的相似度也是投影到语言特征空间中来度量的。
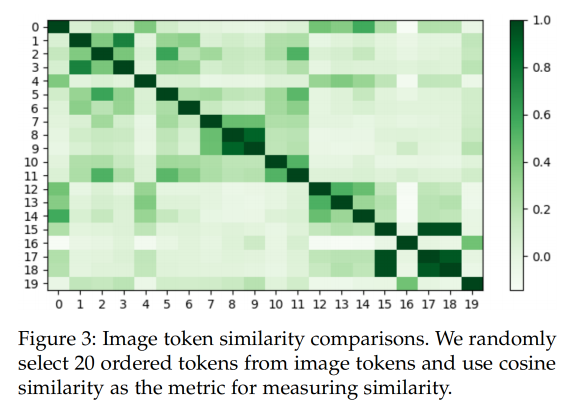
作者随机选择了 20 个经过 image resampler 的特征,且使用 cosine 相似度度量了各个特征和其他不同特征的相似度,如图 3 所示,可以看出很多 token 特征都存在很多相似的 token 特征
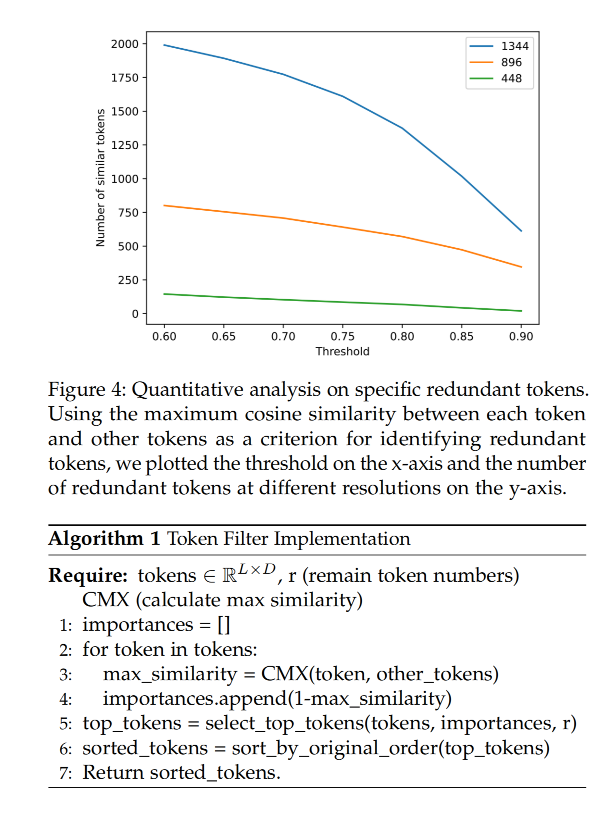
作者又对比了不同分辨率情况下的 token 冗余度,作者选择阈值为 0.8 作为相似度阈值,当分辨率分别为 448,896 和 1334 时,冗余的 token 分别为:68/256 (26.6%),571/1024 (55.8%), 1373/2304 (59.5%),所以可以得到结论,分辨率越大,token 冗余越大
那么虽然 token 有冗余,如何判断一个 token 是冗余的还是重要的呢,作者发现当一个 token 有高度的独一性(很少有相似度高的 token,也就是只有它自己和自己很相似,比如 4 号 token,只有和自己的相似度很高,和其他 token 的相似度都不高)时,其就是重要的。所以,作者使用相似度来衡量一个 token 是否重要。
虽然扔掉一些 token 能降低冗余,但肯定会有一些信息丢失,所以作者又使用挑选出来的 token 作为 query,然后使用 cross-attention 来进一步聚合所有特征。
2.4 Position-Related Task
为了缓解 LLM 的幻觉问题(幻觉问题就是大语言模型可能会生成和图像无关的错误回答),所以本文作者将视觉信息纳入了 LMM 的回答中,因为文本任务的答案一般可以在图像中找到,所以作者认为大模型能在产生回答的同时找到支撑其答案的特定视觉证据
为了支持模型找到和回答相关的目标,作者对数据集进行了修改,提取出了图像中大部分答案的位置信息,然后将位置信息无缝集成到答案中,保留了直接对话的原始能力,也保留了问答任务
为了更好地感知文本对应目标的空间位置,这就要求模型具有强大的空间理解能力。在上述模型设计的基础上,我们增加了额外的训练任务以提高模型对文本位置的感知,例如文本定位和阅读文本。如表 1 中,为了确保文本和位置数据之间有强烈的联系,需要严格保持它们的对齐,确保文本信息始终在任何相关的位置细节之前。
为了标准化不同比例的图像,作者使用 ( 0 , 1000 ) (0, 1000) (0,1000) 的比例来表示位置信息。因此,在一个分辨率为 ( H r × W r ) (Hr × Wr) (Hr×Wr)的图像中,文本坐标 ( x , y ) (x,y) (x,y) 将被标准化为 [ ( x / H r ∗ 1000 ) ] [(x/Hr * 1000)] [(x/Hr∗1000)],y 坐标也采用相同的方法进行标准化。
在处理不同比例的图像时,标准化是一个常见的步骤,目的是确保图像的位置信息在不同分辨率和尺寸的图像之间是一致的。这里使用的标准化方法是将图像的坐标转换到一个统一的尺度(在这个例子中是0到1000的范围内),以便于处理和比较图像中的位置信息。
为什么要这样做:
-
一致性:当你有多个图像,它们的分辨率(Hr × Wr)可能各不相同,直接比较或处理图像中的位置数据(如文本坐标)会很困难。通过将所有图像的位置数据标准化到同一个尺度,可以确保不同图像的数据是可比较的。
-
无关分辨率:这种方法使得位置信息独立于图像的原始尺寸和分辨率。这意味着无论图像的原始大小如何,位置数据都会保持一致,这对于图像分析和机器学习应用非常重要。
-
简化计算:在一个统一的尺度上工作可以简化图像之间的计算,因为所有的计算都基于相同的尺度。
2.5 Dataset Construction
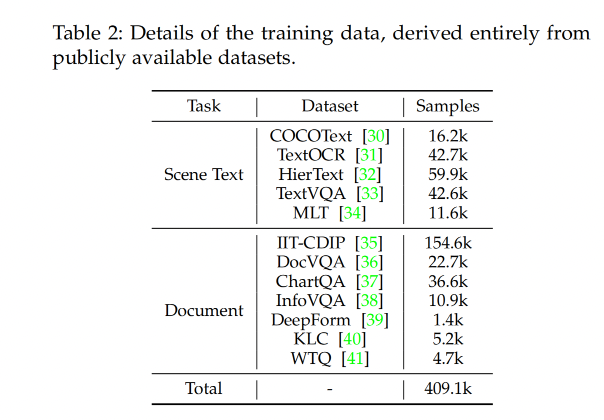
作者主要使用开源数据,并应用各种特定任务的增强手段来改进不同数据集。通过整合多种数据集并为不同任务使用不同的指令,提高了模型的学习能力和训练效率。
- 对于场景文本场景,有 COCOText、TextOCR、HierText、TextVQA、MLT进行训练
- 对于文档图像,有 IIT-CDIP、DocVQA、ChartQA、InfoVQA、DeepForm、Kleister Charity (KLC) 和 WikiTableQuestions (WTQ)。
- 为了加快训练速度,将单图像问答转变为多轮图像基问答,显著提高了图像特征的利用率,这一方法遵循了LLaVA中介绍的成功方法。
数据细节如表 2,数据集中总共有 40.9 万对对话数据和 210 万对问答对
为了进一步增强模型处理结构化文本的能力,在 TextMonkey 上进行了一个 epoch 的微调,使用结构化数据来增强其结构化能力,从而得到了 TextMonkey+。
微调数据主要由之前阶段的 5% 数据组成,以及一部分结构化数据,包括文档、表格和图表。结构化数据图像也来源于公开可用的数据集,并使用它们的结构信息生成。因此,在结构化数据中总共有 55.7k 的数据。
2.6 Loss
TextMonkey 的训练目标是像 LLM 一样预测 next token,所以就需要最大化似然函数:
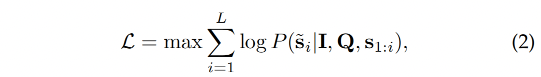
- I:输入图像
- Q:question sequence
- s:input sequence
- s ~ \tilde s s~:output sequence
- L:output sequence
s 代表输入序列,它可能包含了与当前问题 Q 相关的历史对话内容。在多轮对话系统中,输入序列 s 通常包括当前轮次之前的所有交互内容,这样模型就可以利用这些历史信息来更好地理解当前的问题并给出更合适的回答。
三、效果
模型细节设置
作者使用 Vit-BigG 作为 visual encoder,使用 Qwen-VL 的 LLM 作为大语言模型
对图像进行切分时,窗口大小和 Qwen-VL 一样,都是 448,image sampler 处理后的长度为 256,token resampler 的 ratio r 设置为 512 (分辨率为 896时),r 设置为 1024(分辨率为 1344 时),为了快速训练和验证,大多实验都在 896 分辨率上做的
TextMonkey 的大语言模型参数量是 7.7B,image sampler 参数量为 90M,token resampler 的参数量为 13M,encoder 参数量为 1.9B,Shifted Window Attention 参数量为 45M,总参数量为 9.7M
训练:
- 使用 AdamW 优化器,初始学习率为 1e-5,最终会降低到 5e-6
- batch size 为 128
- 一个 epoch 训练需要 12 A800 days
评测:
- accuracy 指标:如何模型产生的响应包含真值,则判定为正确
- 为了和其他方法更公平的对比,还对某些数据集进行了补充评估,使用了原有的 F1 和 ANLS
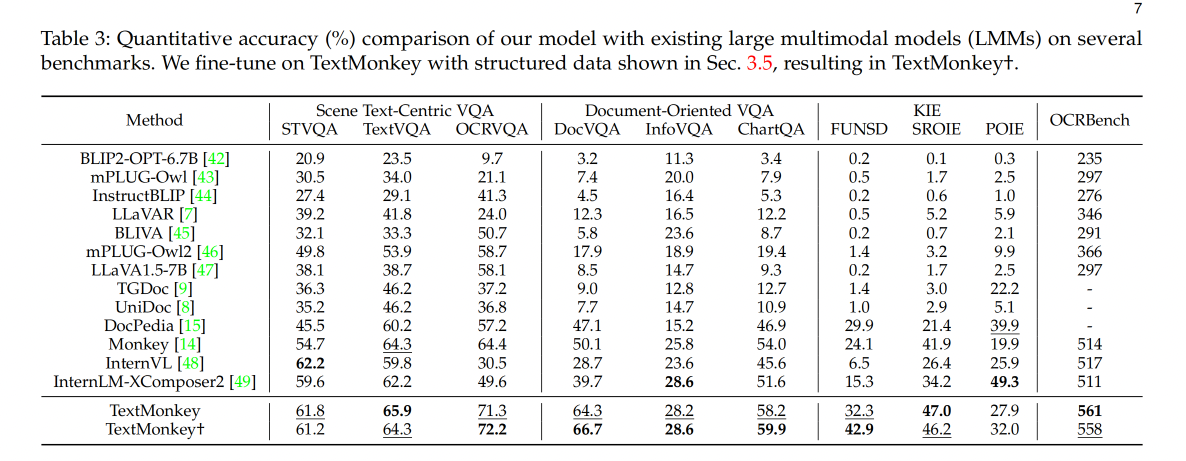
3.1 OCRBench
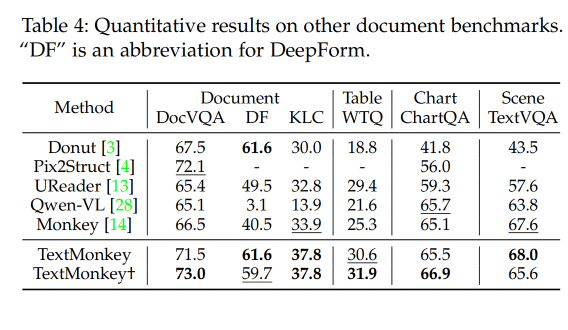
3.2 Document Benchmarks results
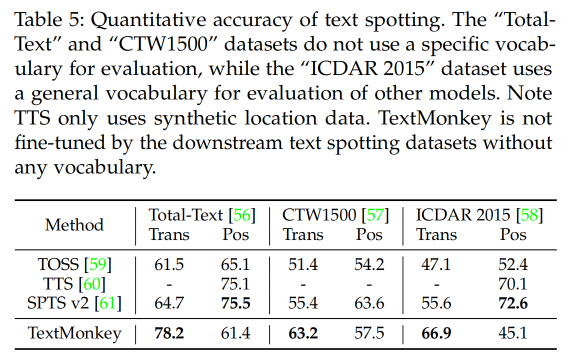
3.3 Text spotting results
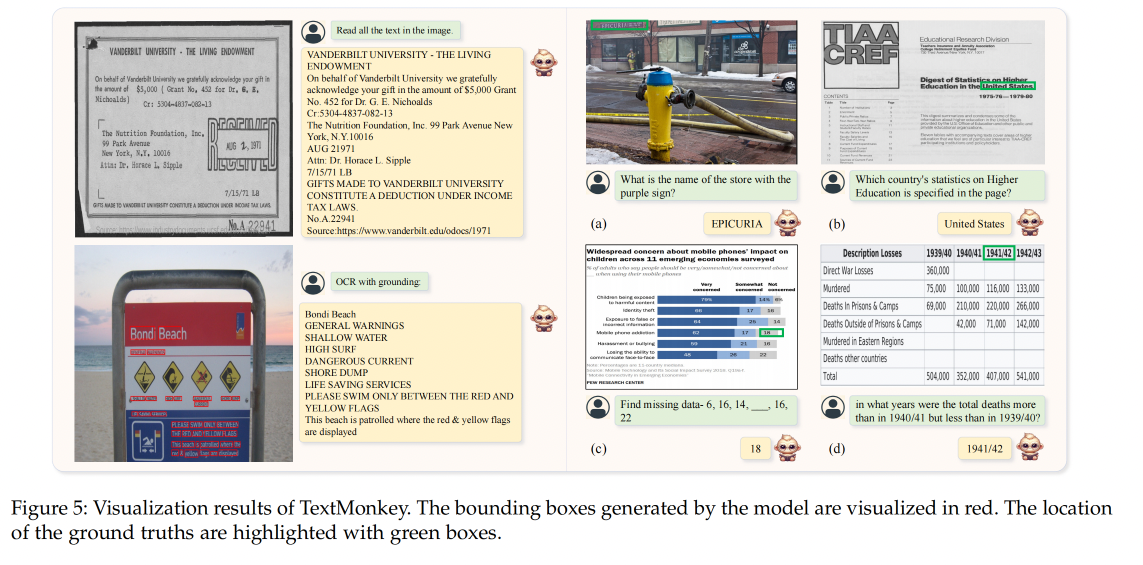
3.4 Visualization
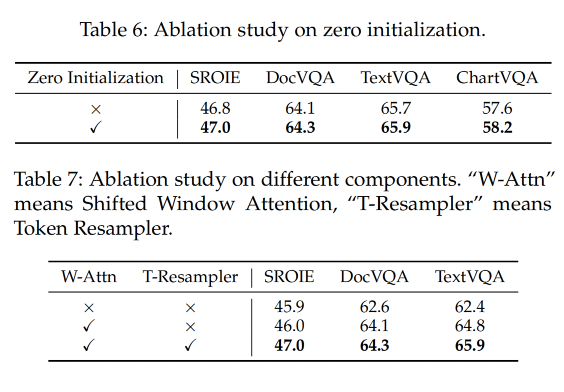
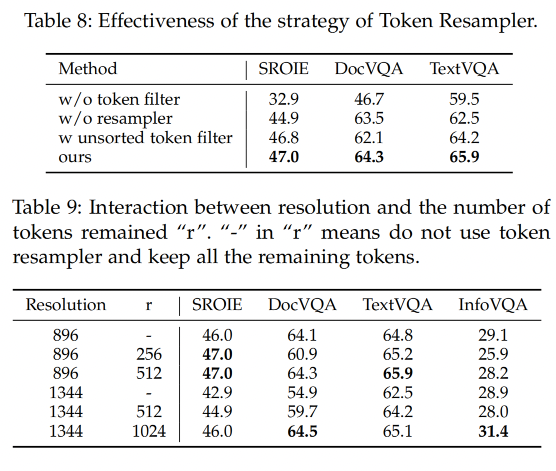
3.5 Ablation Study
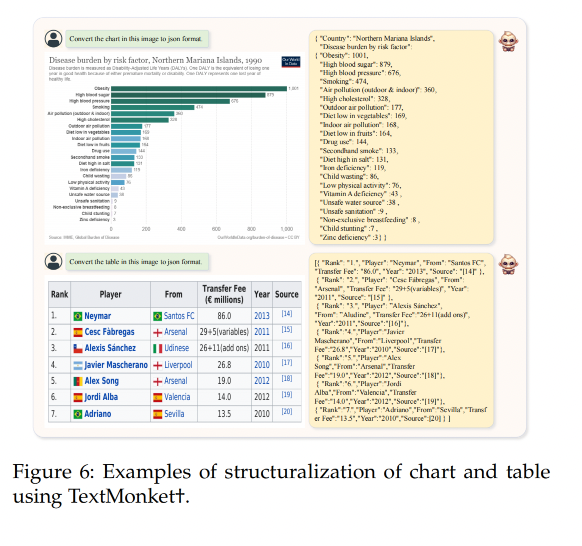
3.6 Sturcturalization
3.7 APP Agent



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











