








论文:mPLUG-Owl : Modularization Empowers Large Language Models with Multimodality
代码:https://github.com/X-PLUG/mPLUG-Owl
出处:阿里
时间:2023.08
贡献:
- 提出了 mPLUG-Owl,能够通过调制模块来实现语言和图像更好的对齐,更好的激发 LLM 对多模态的生成能力
- 构建了一个数据集 OwlEal,来评测不同模型在各类视觉任务上的能力
- mPLUG-Owl 在多模态理解和多轮对话任务上表现的都很好
一、背景
LLM 在很多任务上有很强的 zero-shot 能力,但现在有很多多模态任务直接使用 LLM 来进行多模态任务的生成
比如现有的扩展 LLM 的思路有两个:
- 不同系统的协作:Visual ChatGPT、MM-REACT、HuggingGPT,能够使用各种视觉模型和工具来协调,以实现多模态任务,但这些方法会缺乏不同模态的对齐,且效率不高
- 端到端的模型训练:Blip-2、LLaVA、MiniGPT-4,这些模型时使用统一的模型来支持不同的模态,但是一般会冻结视觉模型,也会导致不同模态对齐不充分。
本文作者提出了一个训练方法 mPLUG-Owl,通过对基础 LLM 模型的调制(modularized)来加强 LLM 模型在多模态任务上的推理能力,对 LLM 模型的调制包括两个模块, 一个 visual knowledge module 和一个 visual abstractor module。
mPLUG-Owl 引入了两阶段训练方法来对齐 image 和 text,能在借用 LLM 的能力来帮助学习视觉特征的同时,保持甚至提高 LLM 生成回答的能力
- 第一阶段:冻结 LLM,训练 visual knowledge module 和 abstractor module,来对齐 image 和 text,即让系统学会如何将图像内容和相关的文本描述对应起来。
- 第二阶段:使用只包含语言的数据集和多模态(即包含图像和文本的)监督数据集联合微调 LoRA 模块和 abstractor module,冻结 visual knowledge module ,LoRA模块的作用可能是调整和优化语言模型(LLM)的参数,以便更好地与抽象器模块协同工作。
二、方法
2.1 模型结构
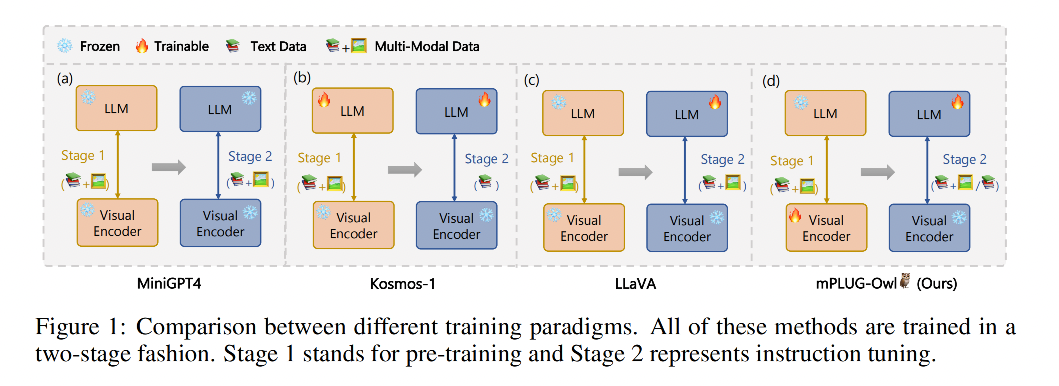
图 1 展示了现有的几种典型的端到端多模态 LLM 的结构:
- 第一种:在预训练和指令微调时都冻结 LLM 和 visual models
- 第二种:在预训练和指令微调时开放 LLM 的训练,冻结 visual 模型
- 第三种:在预训练时冻结 LLM 和 visual encoder,在指令微调时冻结 visual encoder,放开 LLM
- 第四种:本文方法,在预训练时放开 visual encoder,在指令微调时放开 LLM
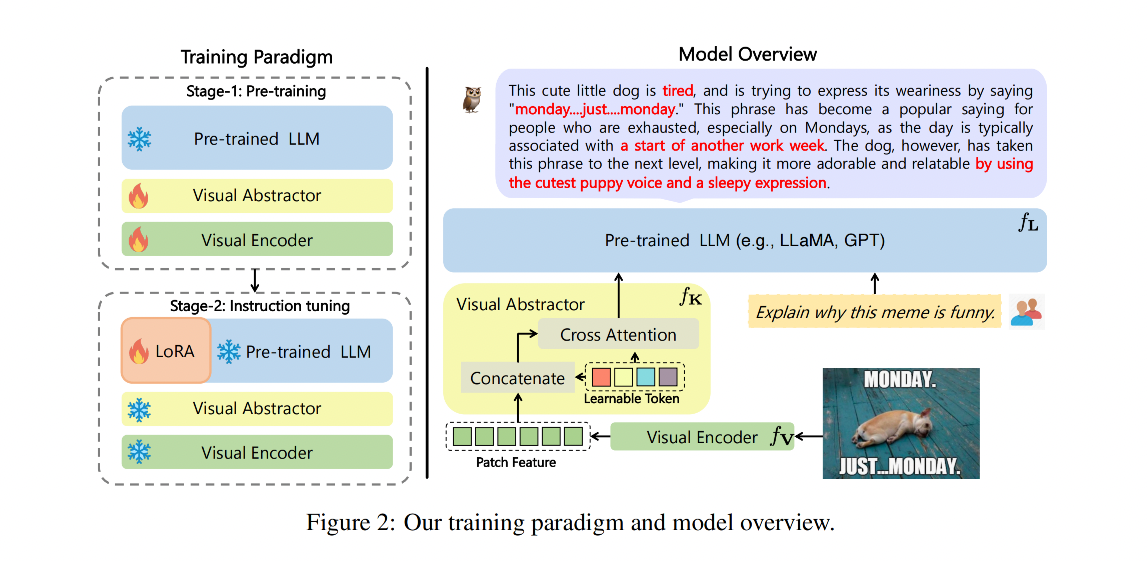
前三种方法都会导致不同模态之间对齐欠佳,本文的 mPLUG-Owl,如图 2 所示,由三个模块组成:
-
视觉基础模型:visual foundation model f V f_V fV,预训练时会方开,微调时会冻结。编码视觉知识,提取密集图像表达特征,预训练时会放开
-
视觉抽象模型:visual abstractor module f K f_K fK,预训练时会放开,微调时会冻结。使用 f V f_V fV 提取的密集图像特征很繁杂,所以在送入 f L f_L fL 之前,使用这个抽象模型将视觉特征进行一定程度的抽象, f V f_V fV 的作用也是总结提取重要的图像特征,来送入 f L f_L fL,总结的方式是使用可训练的 token 和 f V f_V fV 的输出特征进行 cross-attention。
-
语言基础模型:language foundation model f L f_L fL,预训练时冻结,微调时会使用 LoRA 来微调。接收 f K f_K fK 输出的抽象图像特征和文本问题,输出回答
2.2 训练
2.2.1 预训练
大型语言模型一般都是使用大量且多样的文本数据来训练的,所以其有很强的对复杂问题的理解能力,为了让大语言模型具有对视觉任务的理解能,作者引入了可训练的 visual backbone f V f_V fV 和一个 visual abstractor f K f_K fK,冻结 f L f_L fL,让模型捕捉图像特征的同时也能和 LLM 模型对齐
2.2.2 指令微调
经过预训练后的模型有能够对问题有较好的回答,但回答的不是很连贯,所以作者还使用了指令微调,能让模型更好的理解用户的意图
视觉模型已经能很好的提取图像特征了,所以作者冻结的图像编码器,使用了 LoRA 来微调 f L f_L fL,用于促进模型和人类指令的更好的对齐
2.3 训练目标
最大化 token 的对数似然函数
三、效果
实验设置:
- visual foundation model:ViT-L/14,24 layers,patch size=14,hidden dimension=1024,为了加速训练,使用了 CLIP ViT-L/14 来初始化模型参数
- language foundation model:原始的 LLaMa-7B,没有使用经过指令微调的变体(Alpaca/Vicuna)
- mPLUG-Owl 总参数量:7.2B
数据:
- 预训练阶段:数据集为 LAION-400M、COYO-700M、CC、MSCOCO。token batch 大小为 210 万,训练 50k steps,大约共 1040 亿个 token,优化器为 AdamW,输入图像为 224x224,且使用 SentencePiece 和 tokenizer 对文本输入进行分词,学习率为 0.0001
- 指令微调阶段:收集了多种不同的数据,从 Alpaca 收集 102k,从 Vicuna 收集 90k,从 Baize 手机 50k,从 LLaVA 数据集中拿出了 150k,然后训练 2k steps,batch size 为 256,学习率为 0.00002
Baseline:
- OpenFlamingo-9B
- BLIP-2
- MiniGPT-4
- LLaVA
- MM-REACT
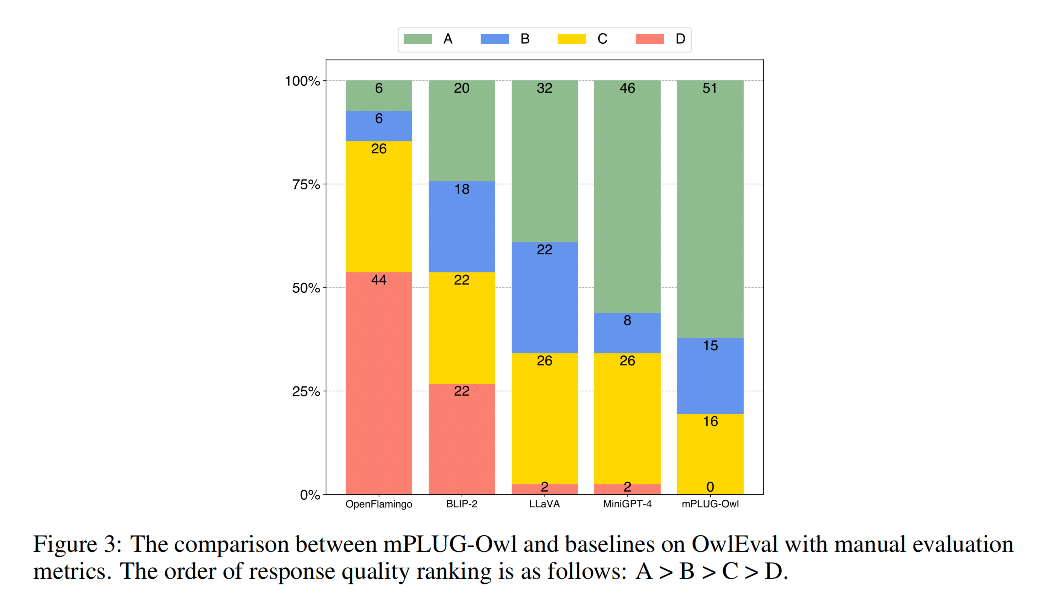
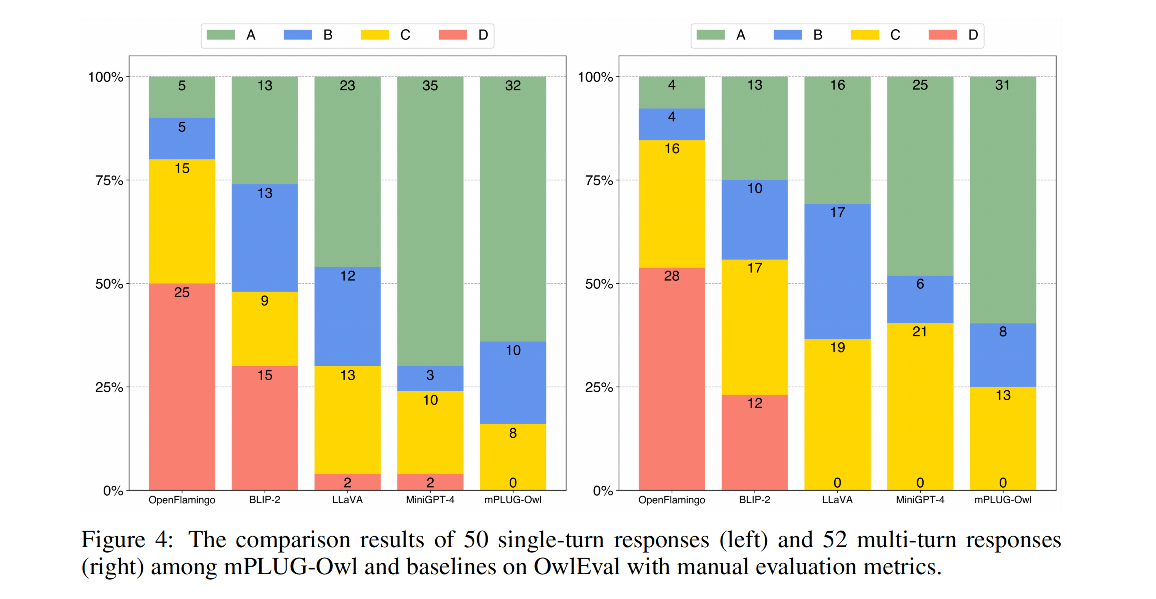
数据集 OwlEval:
- 对 50 张图片收集了 82 个人类的问题,部分图片有多轮对话
- 测评的能力包含自然图像理解,图表和表格理解,OCR, Knowledge-intensive QA (知识密集型问答,设计很多专业知识)
- 评测使用人工评估,给模型的回答打分,评估成 A B C D 四个等级
3.1 知识密集型问答
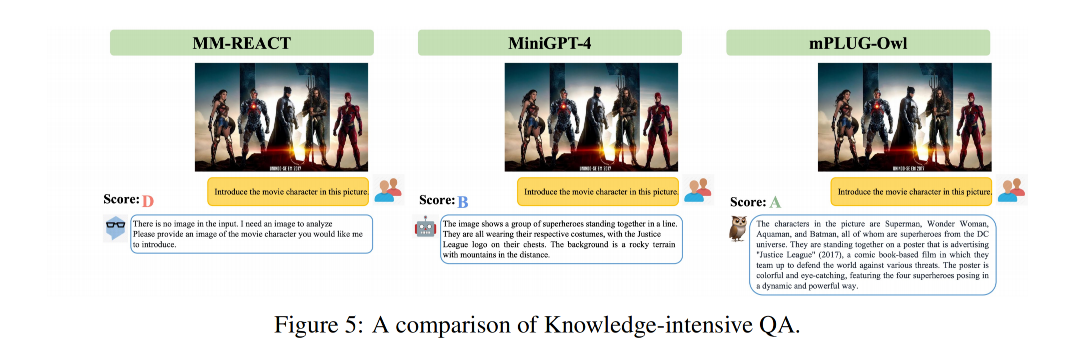
3.2 多轮问答

3.3 推理

3.4 笑话理解
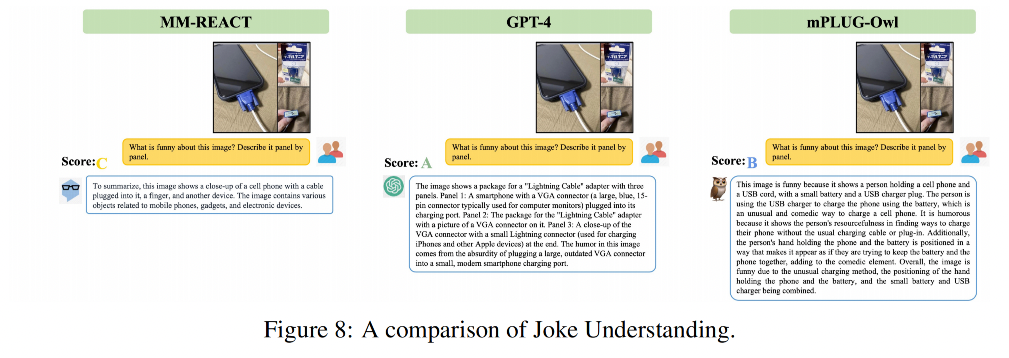


















 411
411

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











