






原文地址 2015
摘要
与传统的统计机器翻译不同的是,神经机器翻译的目的是建立一个单一的神经网络,可以协同调整,使翻译性能最大化。
我们推测,固定长度向量的使用是编码-解码结构性能提升的瓶颈;因此,本文提出了下面的方法来提升性能,通过让模型自动(soft-)搜索与预测目标词相关的源句部分,而不需要显式地将这些部分分块(hard segment)。
通过定性分析,验证了我们方法的正确性。
引言
背景:神经机器翻译
RNN Encoder-Decoder
简单介绍一下RNN Encoder-Decoder(Cho et al 2014a 和 Sutskever et al 2014),我们再次基础上建立了一个能够同时进行对齐和翻译的新框架。
在Encoer-Decoder框架中,
解码器读取输入句子——矢量序列x =
(
x
1
,
x
2
,
.
.
.
,
x
T
x
)
(x_1, x_2, ..., x_{T_x})
(x1,x2,...,xTx), 得到向量c,最常用的方法时使用一个RNN:
h
t
 
=
 
f
(
x
t
,
 
h
t
−
1
)
h_t\,=\,f(x_t, \,h_{t-1})
ht=f(xt,ht−1)和
c
 
=
 
q
(
{
h
1
,
.
.
.
,
h
T
x
}
)
,
c\,=\,q(\{h_1, ..., h_{T_x}\}),
c=q({h1,...,hTx}),其中,
h
t
∈
R
n
h_t\in R^n
ht∈Rn是在时间步
 
t
 
\,t\,
t的隐藏状态,
 
c
 
\,c\,
c是由隐藏状态序列生成的向量。
 
f
 
和
 
q
 
\,f\,和\,q\,
f和q是非线性函数。
解码器利用上下文向量
 
c
 
\,c\,
c和所有之前预测的单词
{
y
1
,
.
.
.
,
y
t
′
−
1
}
\{y_1,...,y_{t'-1}\}
{y1,...,yt′−1}来预测下一个单词
y
t
′
y_{t'}
yt′。即,解码器通过将联合概率分解为有序条件来定义译文
 
y
 
\,y\,
y的概率:
p
(
y
)
 
=
 
∏
t
=
1
T
p
(
y
t
∣
{
y
1
,
.
.
.
,
y
t
−
1
,
c
}
)
,
(
2
)
p(y)\,=\,\prod_{t=1}^Tp(y_t|\{y_1,...,y_{t-1},c\}),\qquad\qquad(2)
p(y)=t=1∏Tp(yt∣{y1,...,yt−1,c}),(2)其中,
y
=
(
y
1
,
.
.
.
,
y
T
y
)
y ={(y_1, ..., y_{T_y})}
y=(y1,...,yTy),利用RNN,每个条件概率的模型如下:
p
(
y
t
∣
{
y
1
,
.
.
.
,
y
t
−
1
}
,
c
)
=
g
(
y
t
−
1
,
s
t
,
c
)
,
(
3
)
p(y_t|\{y_1,...,y_{t-1}\},c)=g(y_{t-1},s_t,c),\qquad\qquad(3)
p(yt∣{y1,...,yt−1},c)=g(yt−1,st,c),(3)其中,
g
g
g是一个非线性,潜在的多层函数,它输出概率
y
t
y_t
yt,
s
t
s_t
st是RNN的隐藏状态。注意还可以使用其他构架,如RNN和de-convolutional神经网络混合的结构Kalchbrenner and Blunsom 2013。
learning to align and translate
本文主体。结构包括一个双向RNN编码器和一个能够对源句子进行搜索的解码器。
解码器:一般描述
我们使用(2)
p
(
y
)
 
=
 
∏
t
=
1
T
p
(
y
t
∣
{
y
1
,
.
.
.
,
y
t
−
1
,
c
}
)
p(y)\,=\,\prod_{t=1}^Tp(y_t|\{y_1,...,y_{t-1},c\})
p(y)=∏t=1Tp(yt∣{y1,...,yt−1,c})式定义条件概率:
p
(
y
i
∣
{
y
1
,
.
.
.
,
y
i
−
1
}
,
x
)
=
g
(
y
i
−
1
,
s
i
,
c
i
)
,
(
4
)
p(y_i|\{y_1,...,y_{i-1}\},x)=g(y_{i-1},s_i,c_i),\qquad\qquad(4)
p(yi∣{y1,...,yi−1},x)=g(yi−1,si,ci),(4)其中,
s
i
s_i
si是RNN在时间
i
i
i 的隐藏状态:
s
i
=
f
(
s
i
−
1
,
y
i
−
1
,
c
i
)
.
s_i = f(s_{i-1},y_{i-1},c_i).
si=f(si−1,yi−1,ci).注意:与现有的Encoder-Decoder方法不同(2),这里,每个目标单词
y
i
y_i
yi的概率以一个distinct(明显的)上下文向量
c
i
c_i
ci为条件。
c
i
c_i
ci由注释序列
(
h
1
,
.
.
.
,
h
T
x
)
(h_1,...,h_{T_x})
(h1,...,hTx)决定,而
(
h
1
,
.
.
.
,
h
T
x
)
(h_1,...,h_{T_x})
(h1,...,hTx)是输入句子经过编码器映射的输出。每个
h
i
h_i
hi都包含了关于整个输入序列的信息,并着重于围绕输入序列的第i个单词的部分。
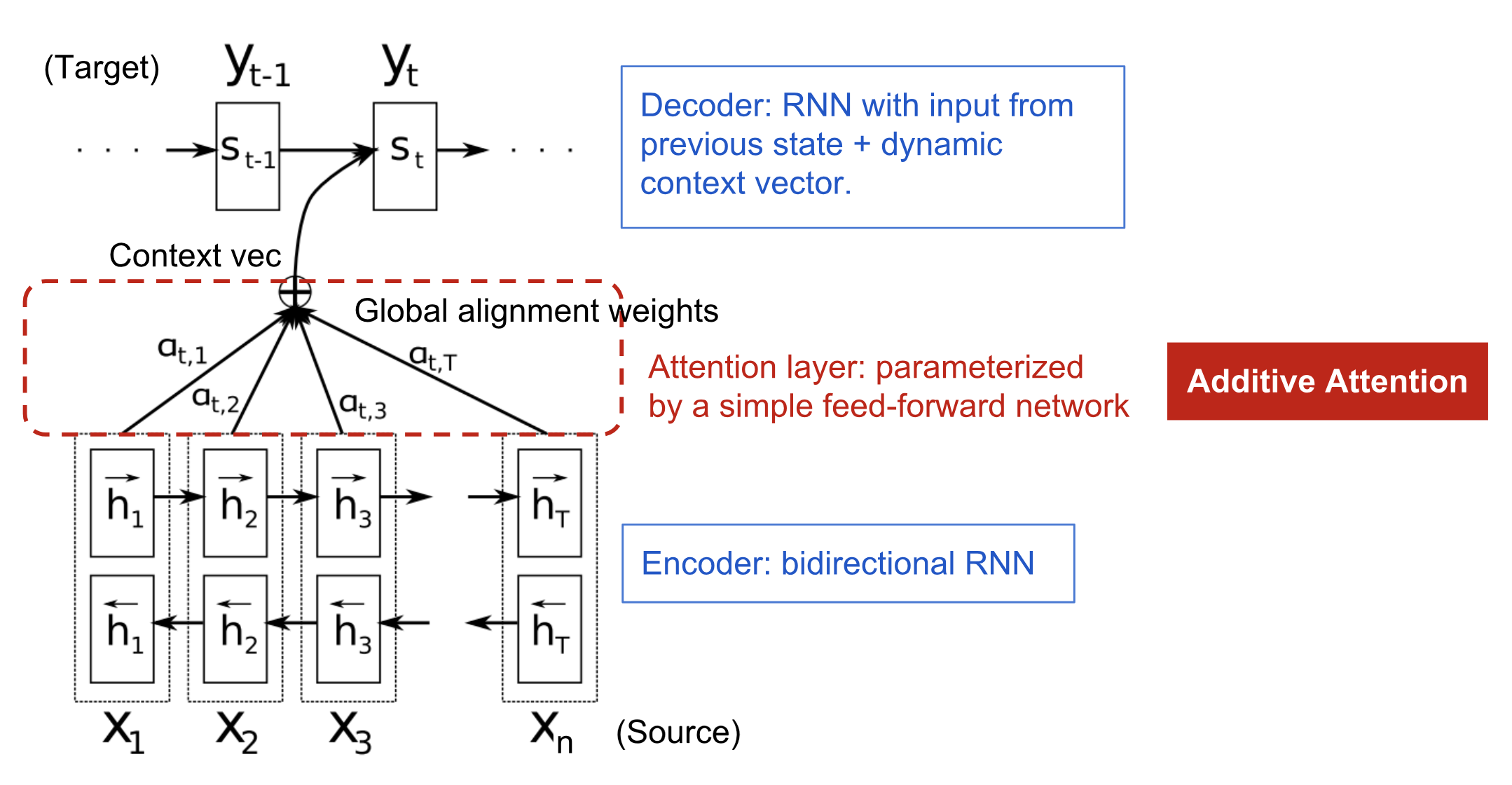
图1:给定源句子
(
x
1
,
x
2
,
.
.
.
,
x
T
)
(x_1,x_2,...,x_T)
(x1,x2,...,xT),生成
t
t
t个目标单词
y
t
y_t
yt模型的图形化注释。
上下文向量
c
i
c_i
ci通过对这些
h
i
h_i
hi加权得到:
c
i
=
∑
j
=
1
T
x
α
i
j
h
j
c_i=\sum_{j=1}^{T_x}\alpha_{ij}hj
ci=j=1∑Txαijhj权值
α
i
j
\alpha_{ij}
αij计算方法如下:
α
i
j
=
e
x
p
(
e
i
j
)
∑
k
=
1
T
x
e
x
p
(
e
i
k
)
,
(
6
)
\alpha_{ij} = \frac{exp(e_{ij})}{\sum_{k=1}^{T_x}exp(e_{ik})},\qquad (6)
αij=∑k=1Txexp(eik)exp(eij),(6)其中,
e
i
j
=
a
(
s
i
−
1
,
h
j
)
e_{ij}=a(s_{i-1},h_j)
eij=a(si−1,hj)是对齐模型,它是对位置j出的输入和位置i出的输出匹配程度的度量。得分是基于RNN隐藏状态
s
i
−
1
s_{i-1}
si−1(Eq(4))和输入句子的第
j
j
j个注释
h
j
h_j
hj。
我们将对齐模型参数化为一个前馈神经网络,该神经网络与所提系统的所有其他组件共同训练。注意:对齐不被认为是一个潜在变量,Instead, the alignment model directly com-putes a soft alignment, which allows the gradient of the cost function to be backpropagated through.
α i j 可 以 看 成 是 概 率 — — 从 源 句 子 x j 翻 译 成 ( 对 准 为 ) 目 标 单 词 y i 的 概 率 。 t h e   i − t h   c o n t e x t   v e c t o r   c i   i s   t h e   e x p e c t e d   a n n o t a t i o n   o v e r   a l l   t h e   a n n o t a t i o n s   w i t h   p r o b a b i l i t i e s   α i j . ( 第 i 个 上 下 文 向 量 c i 是 在 具 有 概 率 α i j 的 所 有 注 释 H 的 期 望 注 释 , 即 对 映 射 h 用 α i j 的 加 权 和 ) 概 率 α i j ( e i j ) 反 映 了 在 决 定 下 一 状 态 s i 和 生 成 y i 时 , h j 和 前 一 隐 藏 状 态 s i − 1 的 重 要 性 。 \color{blue}{\begin{array}l\\\alpha_{ij}可以看成是概率——从源句子x_{j}翻译成(对准为)目标单词y_i的概率。\\ the\, i-th \,context\, vector\, c_i \,is \,the\, expected \,annotation \,over\, all \,the \,annotations \,with\, probabilities\, α_{ij}.\\(第i个上下文向量c_i是在具有概率α_{ij}的所有注释H的期望注释,即对映射h用α_{ij}的加权和)\\概率α_{ij}(e_{ij})反映了在决定下一状态s_i和生成y_i时,h_j和前一隐藏状态s_{i-1}的重要性。\end{array}} αij可以看成是概率——从源句子xj翻译成(对准为)目标单词yi的概率。thei−thcontextvectorciistheexpectedannotationoveralltheannotationswithprobabilitiesαij.(第i个上下文向量ci是在具有概率αij的所有注释H的期望注释,即对映射h用αij的加权和)概率αij(eij)反映了在决定下一状态si和生成yi时,hj和前一隐藏状态si−1的重要性。
解码器中的注意力机制使编码器能够从将所有源信息都编码成一个固定维度的向量的繁重任务中解脱出来。
解码器:双向RNN生成注释序列h
每个单词的注释(h)涵盖了前面单词和后面单词。
前向隐藏状态:
(
h
→
1
,
.
.
.
,
h
→
T
x
)
(\overrightarrow h_1,...,\overrightarrow h_{T_x})
(h1,...,hTx),从
x
1
到
x
T
x
x_1到x_{T_x}
x1到xTx
后向隐藏状态:
(
h
←
1
,
.
.
.
,
h
←
T
x
)
(\overleftarrow h_1,...,\overleftarrow h_{T_x})
(h1,...,hTx),从
x
T
x
到
x
1
x_{T_x}到x_1
xTx到x1
对于每个单词
x
j
x_j
xj,连接其前后向隐藏状态作为最终状态,
h
j
=
[
h
→
j
T
;
h
←
j
T
]
T
h_j = [\overrightarrow h_j^T;\overleftarrow h_j^T]^T
hj=[hjT;hjT]T
实验设置
对所提出的英法翻译进行了评价。我们使用ACL WMT’14提供的双语平行语料库,并与Cho et al (2014a)所提方法做对比。
4.1 数据集
4.2 模型
训练了两类模型:
第一个是RNN Encoder-Decoder(Cho et al(2014a))提出的
第二个是本文提出的。
m
a
x
o
u
t
 
n
e
t
w
o
r
k
 
(
G
o
o
d
f
e
l
l
o
w
 
e
t
 
a
l
,
(
2013
)
)
\color{red}{maxout \,network\,(Goodfellow\,et\,al,(2013))}
maxoutnetwork(Goodfellowetal,(2013))
h
o
w
 
t
o
 
c
o
n
n
e
c
t
 
r
e
c
u
r
r
e
n
t
 
n
e
u
r
a
l
 
n
e
t
w
o
r
k
,
(
P
a
s
c
a
n
u
 
e
t
 
a
l
,
(
2014
)
)
\color{red}{how\, to\, connect\, recurrent\, neural\, network,(Pascanu\,et\,al,(2014))}
howtoconnectrecurrentneuralnetwork,(Pascanuetal,(2014))
利用SGD和Adadelta (Zeiler, 2012)来训练模型
随后,利用 b e a m   s e a r c h \color{green}{beam \,search} beamsearch寻找最佳解
结果
定性分析(qualitative)和定量(quantitative)分析
定
性
和
定
量
分
析
是
两
种
不
相
同
但
是
有
潜
在
联
系
的
分
析
方
法
。
不
同
:
定
性
就
是
用
文
字
语
言
进
行
相
关
描
述
。
它
是
主
要
凭
分
析
者
的
直
觉
、
经
验
,
运
用
主
观
上
的
判
断
来
对
分
析
对
象
的
性
质
、
特
点
、
发
展
变
化
规
律
进
行
分
析
的
一
种
方
法
。
定
量
就
是
用
数
学
语
言
进
行
描
述
。
它
是
依
据
统
计
数
据
,
建
立
数
学
模
型
,
并
用
数
学
模
型
针
对
数
量
特
征
、
数
量
关
系
与
数
量
变
化
去
分
析
的
一
种
方
法
。
相
同
:
它
们
一
般
都
是
通
过
比
较
对
照
来
分
析
问
题
和
说
明
问
题
的
。
正
是
通
过
对
各
种
指
标
的
比
较
或
不
同
时
期
同
一
指
标
的
对
照
才
反
映
出
数
量
的
多
少
、
质
量
的
优
劣
、
效
率
的
高
低
、
消
耗
的
大
小
、
发
展
速
度
的
快
慢
等
等
,
才
能
为
作
鉴
别
、
下
判
断
提
供
确
凿
有
据
的
信
息
。
优
缺
点
:
相
比
而
言
,
定
量
分
析
方
法
更
加
科
学
,
但
需
要
较
高
深
的
数
学
知
识
,
而
定
性
分
析
方
法
虽
然
较
为
粗
糙
,
但
在
数
据
资
料
不
够
充
分
或
分
析
者
数
学
基
础
较
为
薄
弱
时
比
较
适
用
。
在
分
析
过
程
中
通
常
会
运
用
定
性
与
定
量
相
结
合
的
分
析
方
法
。
\color{green}{\begin{array}l定性和定量分析是两种不相同但是有潜在联系的分析方法。\\不同:\\\qquad定性就是用文字语言进行相关描述。\\\qquad它是主要凭分析者的直觉、经验,运用主观上的判断来对分析对象的\\\qquad性质、特点、发展变化规律进行分析的一种方法。\\定量就是用数学语言进行描述。\\它是依据统计数据,建立数学模型,\\并用数学模型针对数量特征、数量关系与数量变化去分析的一种方法。\\相同:\\它们一般都是通过比较对照来分析问题和说明问题的。\\正是通过对各种指标的比较或不同时期同一指标的对照才反映出数量的多少、质量的优劣、\\效率的高低、消耗的大小、发展速度的快慢等等,才能为作鉴别、下判断提供确凿有据的信息。\\优缺点:\\相比而言,定量分析方法更加科学,但需要较高深的数学知识,\\而定性分析方法虽然较为粗糙,但在数据资料不够充分或分析者数学基础较为薄弱时比较适用。\\在分析过程中通常会运用定性与定量相结合的分析方法。\end{array}}
定性和定量分析是两种不相同但是有潜在联系的分析方法。不同:定性就是用文字语言进行相关描述。它是主要凭分析者的直觉、经验,运用主观上的判断来对分析对象的性质、特点、发展变化规律进行分析的一种方法。定量就是用数学语言进行描述。它是依据统计数据,建立数学模型,并用数学模型针对数量特征、数量关系与数量变化去分析的一种方法。相同:它们一般都是通过比较对照来分析问题和说明问题的。正是通过对各种指标的比较或不同时期同一指标的对照才反映出数量的多少、质量的优劣、效率的高低、消耗的大小、发展速度的快慢等等,才能为作鉴别、下判断提供确凿有据的信息。优缺点:相比而言,定量分析方法更加科学,但需要较高深的数学知识,而定性分析方法虽然较为粗糙,但在数据资料不够充分或分析者数学基础较为薄弱时比较适用。在分析过程中通常会运用定性与定量相结合的分析方法。
5.1 定量结果
本文方法背后的动机之一是针对 基 本 编 码 器 − 解 码 器 方 法 中 使 用 固 定 长 度 的 上 下 文 向 量 , 固 定 长 度 的 上 下 文 向 量 会 限 制 性 能 \color{green}{基本编码器-解码器方法中使用固定长度的上下文向量,固定长度的上下文向量会限制性能} 基本编码器−解码器方法中使用固定长度的上下文向量,固定长度的上下文向量会限制性能。
 由图二知,随着句子长度的增加,RNNencdec的性能急剧下降
由图二知,随着句子长度的增加,RNNencdec的性能急剧下降
5.2 定性结果
alignment:
long sentences
相关工作
6.1 Learning to align
6.2 Neural Networks for machine translation
本文提出的方法,是将神经网络作为独立模型,直接将源句子翻译成目标句子
结论
将源句子编码为固定长度向量存在问题。
为了解决这一问题,提出了attention机制,使模型能够搜索整个源句子,将注意力集中了和下一个目标词相关的信息熵。
α
i
j
α_{ij}
αij代表第
j
j
j个源词到第
i
i
i个目标词的权重
留
给
未
来
的
挑
战
之
一
是
如
何
更
好
地
处
理
未
知
或
罕
见
的
单
词
。
这
将
让
模
型
得
到
更
广
泛
的
应
用
。
\color{green}{\begin{array}l留给未来的挑战之一是如何更好地处理未知或罕见的单词。\\这将让模型得到更广泛的应用。\end{array}}
留给未来的挑战之一是如何更好地处理未知或罕见的单词。这将让模型得到更广泛的应用。
模 型 结 构 \color{green}{模型结构} 模型结构
A
.
1
 
体
系
结
构
的
选
择
\color{green}{A.1\, 体系结构的选择}
A.1体系结构的选择
A
.
1.1
  
循
环
神
经
网
络
\color{green}{A.1.1\,\,循环神经网络}
A.1.1循环神经网络
解码器隐藏状态公式(我们展示解码器的公式。在编码器中可以使用相同的公式,只需忽略上下文向量
c
i
c_i
ci和相关术语):
s
i
 
=
 
f
(
s
i
−
1
,
y
i
−
1
,
c
i
)
 
=
 
(
1
−
z
i
)
∘
s
i
−
1
+
z
i
∘
s
~
i
,
s_i \,=\,f(s_{i-1},y_{i-1},c_i)\,=\,(1-z_i)\circ s_{i-1}+z_i\circ \widetilde s_i,
si=f(si−1,yi−1,ci)=(1−zi)∘si−1+zi∘s
i,其中,
∘
\circ
∘代表对应元素相乘,
z
i
z_i
zi更新们的输出:
s
~
i
=
t
a
n
h
(
W
e
(
y
i
−
1
)
+
U
[
r
i
∘
s
i
−
1
]
+
C
c
i
)
,
\widetilde s_i = tanh(We(y_{i-1})+U[r_i\circ s_{i-1}]+Cc_i),
s
i=tanh(We(yi−1)+U[ri∘si−1]+Cci),其中,
e
(
y
i
−
1
)
∈
R
m
e(y_{i-1})\in R^m
e(yi−1)∈Rm是一个词
y
i
−
1
y_{i-1}
yi−1的m维嵌入,
r
i
r_i
ri是reset gate的输出。
y
i
y_i
yi由1-of-K 向量表示,
e
(
y
i
)
e(y_i)
e(yi)是嵌入矩阵
E
∈
R
m
×
K
E\in R^{m\times K}
E∈Rm×K的一列。
更新门
z
i
z_i
zi允许每个隐藏的单元保持它之前的激活状态,复位门
r
i
r_i
ri控制应该复位多少和来自以前状态的信息。
z
i
=
σ
(
W
z
e
(
y
i
−
1
)
+
U
z
s
i
−
1
+
C
z
c
i
)
,
z_i = \sigma (W_ze(y_{i-1})+U_zs_{i-1}+C_zc_i),
zi=σ(Wze(yi−1)+Uzsi−1+Czci),
r
i
=
σ
(
W
r
e
(
y
i
−
1
)
+
U
r
s
i
−
1
+
C
r
c
i
)
,
r_i=\sigma (W_re(y_{i-1})+U_rs_{i-1}+C_rc_i),
ri=σ(Wre(yi−1)+Ursi−1+Crci),其中,
σ
(
⋅
)
\sigma(\cdot)
σ(⋅)是logistic Sigmoid function
A
.
1.2
  
对
齐
模
型
\color{green}{A.1.2\,\,对齐模型}
A.1.2对齐模型
模型需要被评估
T
x
×
T
y
T_x\times T_y
Tx×Ty次,为了减少计算,使用一个单层的多层感知机(a singlelayer multilayer perceptron such that)
a
(
s
i
−
1
,
h
j
)
=
v
a
T
t
a
n
h
(
W
a
s
i
−
1
+
U
a
h
j
)
,
a(s_{i-1},h_j)=v_a^Ttanh(W_as_{i-1}+U_ah_j),
a(si−1,hj)=vaTtanh(Wasi−1+Uahj),其中,
W
a
∈
R
n
×
n
,
U
a
∈
R
n
×
2
n
,
v
a
∈
R
n
W_a\in R^{n\times n},U_a\in R^{n\times 2n},v_a\in R^n
Wa∈Rn×n,Ua∈Rn×2n,va∈Rn是权重矩阵。因为
U
a
h
j
U_ah_j
Uahj的计算并不取决于i所以我们可以提前计算,使成本最小。
A
.
2
  
模
型
详
细
描
述
\color{green}{A.2\,\,模型详细描述}
A.2模型详细描述
A
.
2.1
  
解
码
器
\color{green}{A.2.1\,\,解码器}
A.2.1解码器
为了增加可读性,我们省略了所有的偏置项;
输入:源句子,1-of-K 编码向量
x
=
(
x
1
,
.
.
.
,
x
T
x
)
,
x
i
∈
R
K
x
x = (x_1, ...,x_{T_x}),x_i\in R^{K_x}
x=(x1,...,xTx),xi∈RKx输出:目标句子,1-of-K编码向量
y
=
(
y
1
,
.
.
.
,
y
T
y
)
,
y
i
∈
R
K
y
y=(y_1,...,y_{T_y}),y_i\in R^{K_y}
y=(y1,...,yTy),yi∈RKy其中,
K
x
K_x
Kx和
K
y
K_y
Ky分别是源语言和目标语言的词汇表大小,
T
x
T_x
Tx和
T
y
T_y
Ty分别表示源句和目标句的长度。
首
先
\color{purple}{首先}
首先
BiRNN的前向状态计算如下:
h
→
i
=
{
(
1
−
z
→
i
)
∘
h
→
i
−
1
+
z
→
i
∘
h
‾
i
→
)
,
if
i
>
0
0
,
if
i
=0
\overrightarrow h_i=\begin{cases}(1-\overrightarrow z_i)\circ \overrightarrow h_{i-1}+\overrightarrow z_i\circ \overrightarrow {\underline h_{i}}),& \text {if $i>0$} \\ 0,& \text{if $i$=0} \end{cases}
hi={(1−zi)∘hi−1+zi∘hi),0,if i>0if i=0















 818
818

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









