






 第二届多模态基础模型挑战赛聚焦于改进文档图像理解,包含两阶段,第一阶段提供公开数据集进行训练,第二阶段发布非公开测试集以避免过度拟合。参与者有机会展示模型实践并赢取奖项。
第二届多模态基础模型挑战赛聚焦于改进文档图像理解,包含两阶段,第一阶段提供公开数据集进行训练,第二阶段发布非公开测试集以避免过度拟合。参与者有机会展示模型实践并赢取奖项。

第二届多模态基础模型挑战赛开始啦
多模基础模型(MMFM)在许多计算机视觉任务中显示出前所未有的优异性能。然而,在一些非常具体的任务(如文档理解)上,它们的性能仍然不太尽如人意。为了评估和改进这些用于文档图像理解任务的强大多模态模型,我们利用了大量公开和非公开的数据,提出了一个挑战赛。我们面临的挑战赛分为两个阶段。在第一阶段,我们发布了一个由公开数据组成的训练集,在第二阶段,我们会发布一个额外的测试集供大家测试使用。
As part of our upcoming “What is Next in Multimodal Foundation Models?” , we have a cool challenge on enterprise applications (understanding document and other text-rich images). This is a great opportunity to test the most practical implications of your models and showcase your work in front of a large audience. Prizes and award certificates will be provided to the winners!
我们的数据集
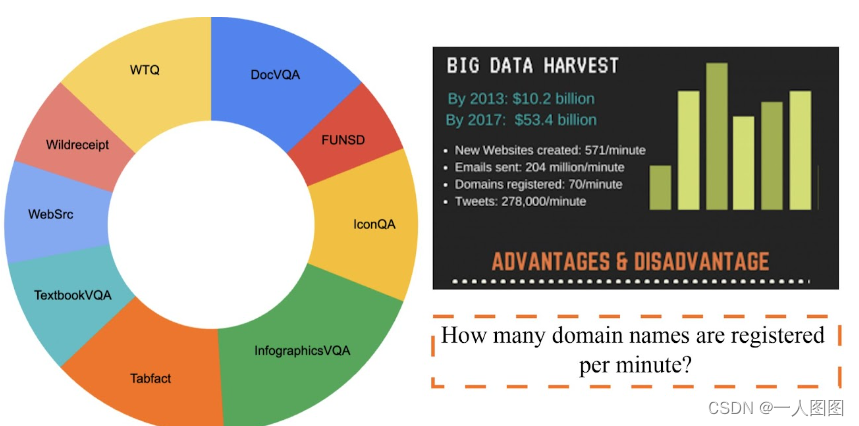
第1阶段
在这一阶段,我们建立了一个全面的数据集,包括公开可用的数据集,包括DocVQA、FUNSD、IconQA、InfogrpacisVQA、Tabfact、TextoolVQA、WebSrc、Wilderreceive、WTQ。所有这些数据集都与图像文档理解挑战的目标相一致,这些挑战涉及特定的领域,如表格核查、图文问答、视频图文问答问题等。该集合由一个训练集和测试集组成,如果您需要可以从MMFM数据集下载。
第2阶段
在这个阶段,将发布一个额外的测试集。该数据集的初衷是防止人们在公开可用的数据集上训练过度拟合。该测试集将由与第1阶段数据集的分布类似的数据组成,但不会由任何公开可用的数据源组成。这些数据将由组织者适时分享给团队。
如果您想要了解更多的信息,请点击链接:https://sites.google.com/view/2nd-mmfm-workshop/challenge?authuser=0 了解更多的内容。
欢迎您加入MMFM Challenge!

重要的时间节点
一些比赛的重要时间节点提供给您,不要错过哦~~


















 1157
1157

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









