







贝叶斯
2019-06-25
参考的寒老师多篇博客进行的总结:
https://blog.csdn.net/han_xiaoyang/article/details/50616559/
1、条件概率与贝叶斯定理
1.1、条件概率
条件概率条件概率是指事件A在另外一个事件B已经发生条件下的发生概率
蒙提霍尔悖论
参赛者面前有三扇关闭着的门,其中一扇的后面是一辆汽车,选中后面有车的那扇门就可以赢得该汽车,而另外两扇门后面则各藏有一只山羊。当参赛者选定了一扇门,但未去开启它的时候,主持人会开启剩下两扇门中的一扇,露出其中一只山羊。主持人其后会问参赛者要不要更换选择,选另一扇仍然关着的门。
- 再不换门的情况下获胜的概率为1/3
- 再换门情况有如下几种:换门获胜的概率为2/3

通过概率计算:

条件概率:

1.2、贝叶斯定理
通过上式中化简得,朴素贝叶斯公式:

-
先验概率:
先验概率仅仅依赖于主观上的经验估计,也就是事先根据已有的知识的推断,先验概率就是没有经过实验验证的概率,根据已知进行的主观臆测 -
后验概率:
后验概率是指在得到“结果”的信息后重新修正的概率
举个例子理解:
假设我们出门堵车的可能因素有两个(就是假设而已,别当真):车辆太多和交通事故。
堵车的概率就是先验概率 。
那么如果我们出门之前我们听到新闻说今天路上出了个交通事故,那么我们想算一下堵车的概率,这个就叫做条件概率 。也就是P(堵车|交通事故)。这是有因求果。
如果我们已经出了门,然后遇到了堵车,那么我们想算一下堵车时由交通事故引起的概率有多大,
那这个就叫做后验概率 (也是条件概率,但是通常习惯这么说) 。也就是P(交通事故|堵车) 。这是有果求因。 -
似然度:
-
标准化常量:
贝叶斯公式展开如下:



2、贝叶斯定理——机器学习视角
把A理解成“具有某特征”
B可以理解为“类别标签”
P ( “ 属 于 某 类 ” ∣ “ 具 有 某 特 征 ” ) = P ( “ 具 有 某 特 征 ” ∣ “ 属 于 某 类 ” ) P ( “ 属 于 某 类 ” ) P ( “ 具 有 某 特 征 ” ) P(“属于某类”|“具有某特征”)=\frac{P(“具有某特征”|“属于某类”)P(“属于某类”)}{P(“具有某特征”)} P(“属于某类”∣“具有某特征”)=P(“具有某特征”)P(“具有某特征”∣“属于某类”)P(“属于某类”)
f ( B ∣ A ) = P ( A ∣ B ) P ( B ) P ( A ) f(B|A)= \frac{P(A|B)P(B)}{P(A)} f(B∣A)=P(A)P(A∣B)P(B)
f ( c l a s s ∣ f e a t u r e ) = P ( f e a t u r e ∣ C l a s s ) P ( C l a s s ) P ( f e a r t u r e ) f(class|feature)= \frac{P(feature|Class)P(Class)}{P(fearture)} f(class∣feature)=P(fearture)P(feature∣Class)P(Class)
2.1、垃圾邮件识别
判断 P(“垃圾邮件”∣“具有某特征”)是否大于1/2
训练数据:10000垃圾邮件、10000正常邮件
A =”我司可办理正规发票(保真)17%增值税发票点数优惠!”
计算后验概率时,如果按句子进行判断,则统计句子在语料中的频数,这样看来时稀疏且不合理的,难以满足大数定律,算出的概率会失真。数据集不能够覆盖所有的句子,而且完全可以构造一句不在训练语料中的句子出来。
为此引入了分词技术!!
句子是无限的,但是词语是有限的~~
拿分词后的序列作为特征:(可以再加入停用词和关键字技术)
“我”,“司”,“可”,“办理”,“正规发票”,“保真”,“增值税”,“发票”,“点数”,“优惠”

2.2、条件独立假设——朴素贝叶斯(Naive Bayes)
假设各个特征之间是相互独立的(即各个单词,没有考虑前后顺序和上下文之间的语义)
![[外链图片转存失败(img-f6krnZyV-1562567261823)(en-resource://database/581:1)]](https://img-blog.csdnimg.cn/20190708144701674.png)
这样处理后式子中的每一项都变得好求了,只需要分别统计各类邮件中该关键词出现得概率,例如:
![[外链图片转存失败(img-m3d3I6F8-1562567261824)(en-resource://database/583:1)]](https://img-blog.csdnimg.cn/20190708144716302.png)
朴素贝叶斯是简化了计算过程,但是存在一定得影响,没有考虑词语之间得现后顺序,不同得顺序可能会导致完全不同得含义。
eg:“武松打死了老虎”与“老虎打死了武松”会被认为是一个意思。
但是效果确实惊人得好!!
为什么呢?“有人对此提出了一个理论解释,并且建立了什么时候朴素贝叶斯的效果能够等价于非朴素贝叶斯的充要条件,这个解释的核心就是:有些独立假设在各个分类之间的分布都是均匀的所以对于似然的相对大小不产生影响;即便不是如此,也有很大的可能性各个独立假设所产生的消极影响或积极影响互相抵消,最终导致结果受到的影响不大。具体的数学公式请参考这篇paper 。
2.3、垃圾邮件——重复词处理方式

1、多项式模型

2、伯努利模型

3、混合模型
第三种方式是在计算句子概率时,不考虑重复词语出现的次数,但是在统计计算词语的概率P(“词语”|S)时,却考虑重复词语的出现次数,这样的模型可以叫作混合模型。
2.4、平滑技术
在朴素贝叶斯计算中,会存在概率为0得情况。(eg,训练模型中没有出现过词语“正规发票”,这样就会出现概率为0)面对这种情况引入了平滑技术。
1、对于伯努利模型
 2、对于多项式模型
2、对于多项式模型

3、垃圾邮件识别——贝叶斯模型的技巧
3.1、为什么不直接匹配关键词来识别垃圾邮件
错误率高
关键词得变形会影响匹配(eg,“涐司岢办理㊣規髮票,17%增値稅髮票嚸數優蕙”),而且关键词也是不断变化的,需要大量的工作整理。
而,朴素贝叶斯就不会出现这种情况,他是基于样本数据的概率统计
3.2、技巧
1、取对数
在进行似然函数P(X|C)概率计算的时候会涉及到一堆概率的乘积,如下图所示,

计算的时间开销比较大,为此引入对数函数log,这样就变成了加法,左右两边同时取对数,得到如下所示结果:

在训练模型的时候就进行log计算,保存在模型中,实时分类时就会提升运算速度。
2、转换为权重
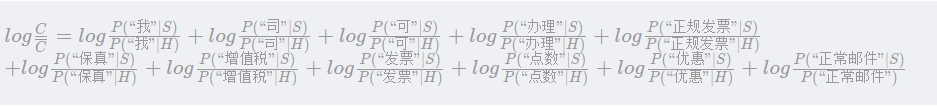
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 638
638











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









