







Dream to Control Learning Behaviors by Latent Imagination
0 摘要
Learned world模型总结了一个agent的经验,以促进学习复杂的action。虽然通过深度学习,从高维感官输入中学习WORLD MODELS变得可行,但从中获得action的潜在方法有很多。我们提出了Dreamer,一个强化学习agent,解决Long horizons任务的图像纯粹由潜在的想象力。我们通过传播学习states值的解析梯度,通过在学习WORLD MODELS的紧凑states空间中想象的轨迹,有效地学习action。在20个具有挑战性的视觉控制任务中,Dreamer在数据效率、计算时间和最终性能方面超过了现有的方法。
1 介绍
即使智能agent从未两次遇到完全相同的情况,也可以在复杂的环境中实现目标。此功能需要根据过去的经验来构建对世界的表示,以将其推广到新颖的情况。WORLD MODELS提供了一种明确的方式,可以在可以对未来进行预测的参数模型中表示agent对世界的了解。
当感官输入是高维图像时,潜在动态模型可以提取观测值以在紧凑states空间中进行预测(Watter等,2015; Oh等,2017; Gregor等,2019)。与图像空间中的预测相比,潜在states的内存占用量小,可以并行想象成千上万的轨迹。随着深度学习和潜在变量模型的发展,学习有效的潜在动态模型变得可行(Krishnan等人,2015; Karl等人,2016; Doerr等人,2018; Buesing等人,2018)。
action可以通过多种方式从动态模型得出。通常,通过参数化策略(Sutton,1991; Ha and Schmidhuber,2018; Zhang等,2019)或通过在线计划(Chua等,2018; Hafner等,2018),可以将想象中的回报最大化。然而,仅考虑固定想象力范围内的rewards会导致近视action(Wang等人,2019)。此外,先前的工作通常采用无导数优化来增强模型误差的鲁棒性(Ebert等人,2017; Chua等人,2018; Parmas等人,2019),而不是利用神经网络动态提供的解析梯度(Henaff等人,2019年; Srinivas等人,2018年)。
我们介绍了Dreamer,这是一个纯粹通过潜在的想象力从图像中学习长期action的agent。一种新颖的actor批评家算法可以有效地利用神经网络动态,从而在想象力范围之外解决rewards问题。为此,我们预测了学习到的潜在空间中的states值和动作,如图1所示。这些值优化了Bellman一致性以实现想象中的rewards,并且该策略通过将其解析梯度传播回动态中来最大化了这些值。
与在线学习或通过经验重播的actor评论家算法相比(Lillicrap等,2015; Mnih等,2016; Schulman等,2017; Haarnoja等,2018; Lee等,2019),WORLD MODELS可以插值过去的经验,并提供多步回报的分析梯度,以实现有效的policy优化。
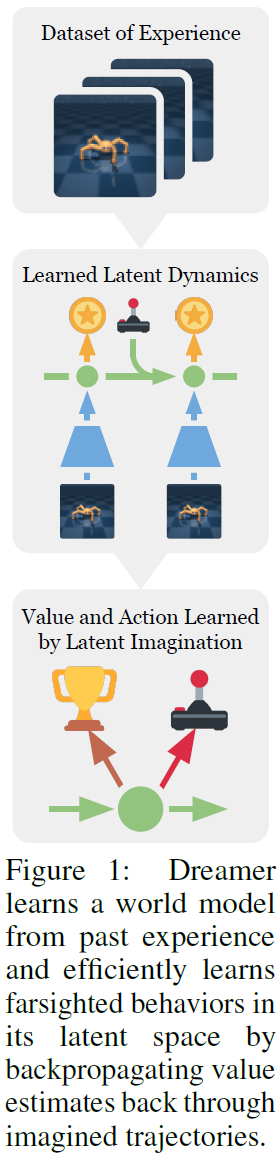
Dreamer从过去的经验中学习了一个WORLD MODELS,并通过将想象的轨迹向后传播value估算,从而有效地学习了其潜在空间中的有远见的action。
本文的主要贡献如下:
- 通过潜在的想象力学习长距离action:如果基于模型的agent使用有限的想象力视野,则它们可能是近视的。 我们通过预测动作和states值来解决此限制。 在潜在空间中纯粹凭空想象力进行训练,使我们能够通过潜在动力传播回解析值梯度来有效地学习策略。
- 视觉控制的经验表现:我们将Dreamer与现有的Representation learning方法配对,并在DeepMind control套件上使用图像输入对其进行评估,如图2所示。Dreamer对所有任务使用相同的超参数,在数据效率、计算时间和最终性能方面超过了以前基于模型和无模型的agent。
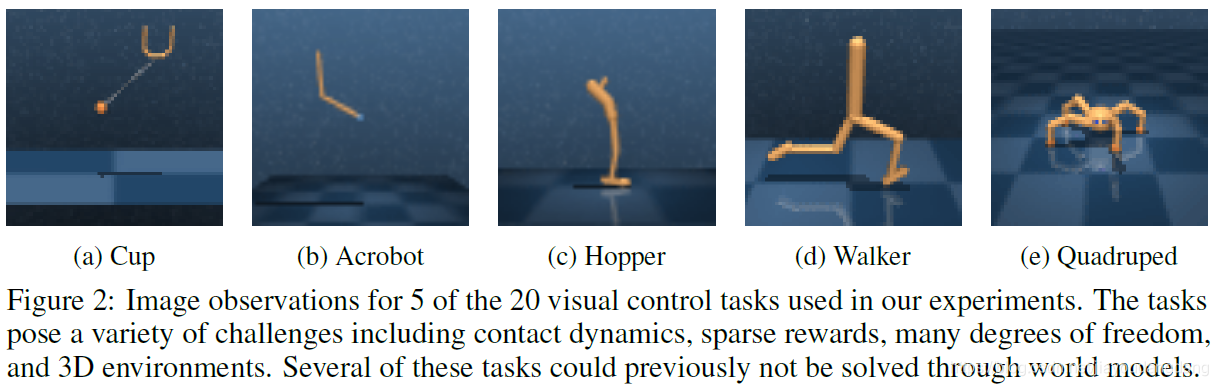
图2:在我们的实验中使用的20个视觉控制任务中的5个的图像观察结果。这些任务带来了各种挑战,包括接触动态,稀疏rewards,许多自由度和3D环境。其中的一些任务以前无法通过WORLD MODELS解决。
强化学习:我们将视觉控制公式化为部分可观察到的马尔可夫决策过程(POMDP),具有离散时间步长![]() ,由agent生成的连续向量值动作
,由agent生成的连续向量值动作![]()
![]() ,由未知环境生成的高维观测值和标量rewards
,由未知环境生成的高维观测值和标量rewards![]()
![]() 。 目标是开发一种可最大化预期回报
。 目标是开发一种可最大化预期回报![]() 的agent。图2显示了我们选择的任务。
的agent。图2显示了我们选择的任务。
- 主体组成部分:在想象中学习的主体的经典组成部分是动态学习,action学习和环境相互作用(Sutton,1991)。在Dreamer的情况下,通过预测world model的紧凑潜在空间中的假设轨迹来学习action。如图3概述并在算法1中进行了详细说明,Dreamer在agent的整个生命周期中执行以下操作,即交错或并行执行:
- 从过去的经验数据集中学习潜在的动态模型,以根据action和过去的观察预测未来的回报。可以将world model的任何学习目标与Dreamer合并。 我们将在第4节中回顾学习潜在动态的现有方法。
- 在世界范围内执行学习的action模型,以收集新的经验来增长数据集。
潜在动态:Dreamer使用由三个部分组成的潜在动态模型。 表示模型对观察和动作进行编码,以创建具有马尔可夫Transition的连续向量值模型states(Watter等人,2015; Zhang等人,2019; Hafner等人,2018)。Transition模型可以预测未来的模型states,而不会看到以后会引起它们的相应观察结果。rewards模型根据模型states预测rewards
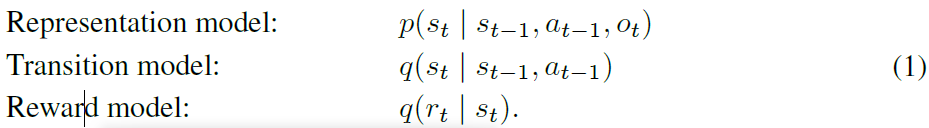
我们使用p表示在真实环境中生成样本的分布,使用q表示能够进行潜在想象的近似值。具体而言,Transition模型使我们无需预测或想象相应的图像就可以在紧凑的潜在空间中进行提前预测。这样可以减少内存占用,并快速并行预测成千上万条想象的轨迹。
该模型模仿非线性卡尔曼滤波器(Kalman,1960年),潜在states空间模型或具有实值states的HMM。但是,它以action为条件并预测rewards,使agent可以想象潜在action序列的结果,而无需在环境中执行。
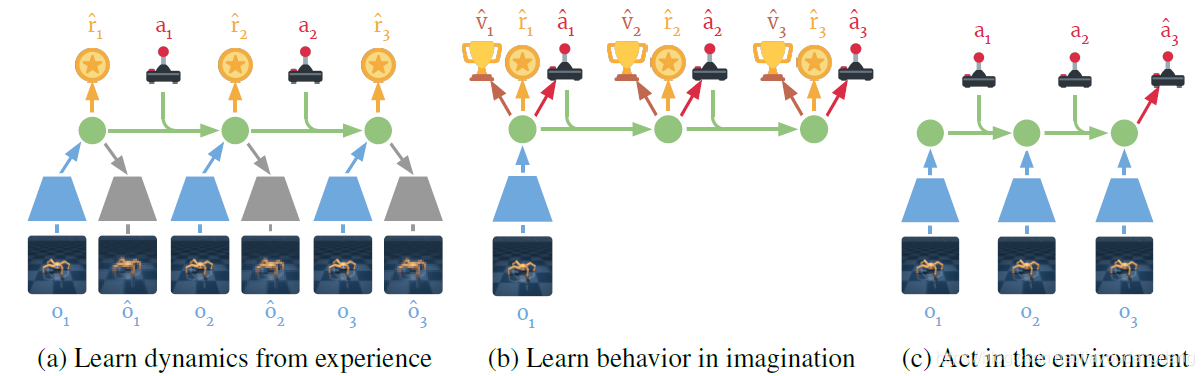
图3:Dreamer的组件。(a)agent从过去的经验数据集中学习,例如通过重建,将观察和行动编码为紧凑的潜在states(![]() ),并预测环境收益(
),并预测环境收益(![]() )。(b)在紧凑的潜在空间中,Dreamer通过通过想象的轨迹向后传播梯度来预测最大化未来value预测的states值(
)。(b)在紧凑的潜在空间中,Dreamer通过通过想象的轨迹向后传播梯度来预测最大化未来value预测的states值(![]() )和动作(
)和动作(![]() )。(c)agent对事件的历史进行编码,以计算当前模型states并预测在环境中要执行的下一个动作。有关agent的伪代码,请参见算法1。
)。(c)agent对事件的历史进行编码,以计算当前模型states并预测在环境中要执行的下一个动作。有关agent的伪代码,请参见算法1。
3 LEARNING BEHAVIORS BY LATENT IMAGINATION
Dreamer通过有效利用神经网络的潜在动态特性,在学习的world model的紧凑型潜在空间中学习了长期的action。为此,我们通过使用重新参数化对action,states,rewards和value进行神经网络预测,来传播多步骤收益的随机梯度。本节描述了本文的主要贡献。
想象环境:潜在动态定义了一个马尔可夫决策过程(MDP; Sutton,1991),因为紧凑模型状态st是马尔可夫,所以可以完全观察到。 我们用τ作为时间指标来表示想象的数量。 想象的轨迹开始于真实的模型状态,即根据特工的过去经验得出的观察序列。 他们遵循Transition模型![]() ,rewards模型
,rewards模型![]() 和策略
和策略![]() 的预测。目的是使有关该policy的预期预期rewards
的预测。目的是使有关该policy的预期预期rewards![]() 最大化。
最大化。

action和value模型:考虑有限水平的想象轨迹H.梦想家使用actor critic的方法来学习考虑超出水平rewards的action。为此,我们在world model的潜在空间中学习了一个action模型和一个value模型。action模型实施该策略,旨在预测解决想象空间的action。value模型估计action模型从每个状态sτ获得的预期预期rewards
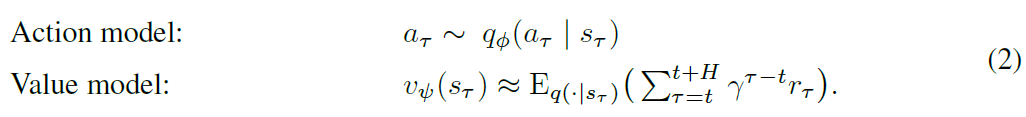
action和value模型按照策略迭代中的典型方式进行协作训练:action模型旨在最大化对value的估计,而value模型旨在匹配随着action模型变化而变化的value的估计。
对于参数分别为Φ和ψ的action和value模型,我们使用密集神经网络。 动作模型输出经过tanh变换的高斯(Haarnoja et al。,2018),并具有神经网络预测的足够统计量。 这允许重新参数化采样(Kingma and Welling,2013; Rezende et al..2014),将采样动作确定性地依赖于神经网络输出,从而使我们可以通过采样操作反向传播分析梯度
![]()
value估算:要学习行动和value模型,我们需要估算想象的轨迹![]() 的状态值。这些轨迹从agent的经验数据集中提取的序列批次的模型状态st分支,并使用从动作模型中采样的动作。可以通过多种方式估计状态值,以权衡偏差和方差(Sutton和Barto,2018年),
的状态值。这些轨迹从agent的经验数据集中提取的序列批次的模型状态st分支,并使用从动作模型中采样的动作。可以通过多种方式估计状态值,以权衡偏差和方差(Sutton和Barto,2018年),
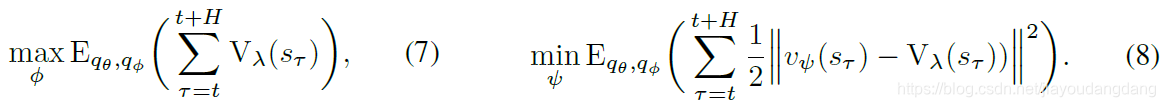
其中,期望值是在想像轨迹下估计出来的。VR只是简单地将从τ到视界的rewards相加,并忽略超过视界的rewards。这使得我们可以在没有value模型的情况下学习action模型,这是我们在实验中比较的一种侵蚀。VkN使用学习value模型评估超过k步的rewards。dreamer使用Vλ,对不同k的估计的指数加权平均值,以平衡偏差和方差。图4显示,在想象中学习一种value模型可以使dreamer解决长视域任务,同时对想象视域保持稳健。第6节描述了所有任务的实验细节和结果。

图4:想象的视野。 我们比较Dreamer的最终性能,学习没有value预测的action模型,并使用PlaNet进行在线计划。学习状态值模型以评估超出想象力范围的reward,可使Dreamer对范围的长度更加稳健。agent将像素重建用于表示学习和R = 2的动作重复。
学习目标为了更新动作和value模型,我们首先计算沿想象轨迹的所有状态![]() 的value估计sτ。action模型
的value估计sτ。action模型![]() 的目标是预测导致状态轨迹的action,并具有高value的估计值。 而value模型
的目标是预测导致状态轨迹的action,并具有高value的估计值。 而value模型![]() 的目标是回归value估算,
的目标是回归value估算,
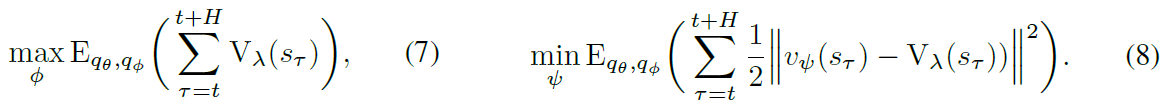
value模型以回归为目标进行更新,围绕目标我们停止了典型的梯度(Sutton和Barto,2018)。动作模型通过学习的动态使用分析梯度来最大化value估计。为了理解这一点,我们注意到value估计取决于reward和value预测,而reward和value预测取决于想象的状态,而想象的状态又取决于想象的action。由于所有步骤都作为神经网络实现,我们通过随机反向传播分析计算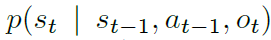 (Kingma和Welling,2013;Rezende等人,2014)。我们对连续动作和潜伏期使用重参数化,对离散动作使用直通梯度(straight-through gradients Bengio等人,2013)。学习action时world model(The world model)是固定的。在提前终止的任务中,world model还预测每个潜在状态的贴现因子,通过预测贴现因子的累积乘积来加权等式7和8中的时间步长,因此根据想象的轨迹结束的可能性来对项进行加权。
(Kingma和Welling,2013;Rezende等人,2014)。我们对连续动作和潜伏期使用重参数化,对离散动作使用直通梯度(straight-through gradients Bengio等人,2013)。学习action时world model(The world model)是固定的。在提前终止的任务中,world model还预测每个潜在状态的贴现因子,通过预测贴现因子的累积乘积来加权等式7和8中的时间步长,因此根据想象的轨迹结束的可能性来对项进行加权。
与actor critic方法的比较:使用A3C和PPO等Reinforce梯度(Williams,1992)的agent(Mnih等人,2016; Schulman等人,2017)使用值基线来减小梯度方差,而Dreamer则通过value模型。这类似于确定性或重新参数化的actor critic(Silver等人,2014),例如DDPG和SAC(Lillicrap等人,2015; Haarnoja等人,2018)。 但是,这些方法不通过转换来利用渐变,而仅最大化立即Q值。MVE和STEVE(Feinberg等人,2018; Buckman等人,2018)将它们扩展到具有学习动态的多步Q学习,以提供更准确的Q值目标。我们预测状态值,这对于策略优化是足够的,因为我们通过动态反向传播。有关与相关工作的更详细比较,请参阅第5节。
想像力中的学习action需要一个能很好地概括的world model。我们关注潜在动态模型,这些模型可以在紧凑的潜在空间中进行前瞻性预测,有利于进行长期预测,并使agent能够同时想象成千上万条轨迹。 已经提出了学习用于控制的表示的几个目标(Watter等人,2015; Jaderberg等人,2016; Oord等人,2018; Eslami等人,2018)。 我们回顾了三种学习与Dreamer结合使用的表示方法:reward预测,图像重建和对比估计。
reward预测:潜在的想象力需要一个表示模型![]() ,Transition模型
,Transition模型![]() 和reward模型
和reward模型![]() ,如本节所述 2.原则上,这可以通过简单地学习预测给定行动和过去观察到的未来reward来实现(Oh等,2017; Gelada等,2019; Schrittwieser等,2019)。对于庞大且多样化的数据集,此类表示应足以解决控制任务。 然而,由于数据集有限,尤其是当reward稀疏时,了解与reward相关的观察结果可能会改善world model(Jaderberg等,2016; Gregor等,2019)。
,如本节所述 2.原则上,这可以通过简单地学习预测给定行动和过去观察到的未来reward来实现(Oh等,2017; Gelada等,2019; Schrittwieser等,2019)。对于庞大且多样化的数据集,此类表示应足以解决控制任务。 然而,由于数据集有限,尤其是当reward稀疏时,了解与reward相关的观察结果可能会改善world model(Jaderberg等,2016; Gregor等,2019)。
重构:我们首先描述PlaNet所使用的world model(Hafner等人,2018),该模型通过重构图像来学习潜伏动态,如图3a所示。 world model由以下组件组成,其中观察模型仅用于提供学习信号
θθ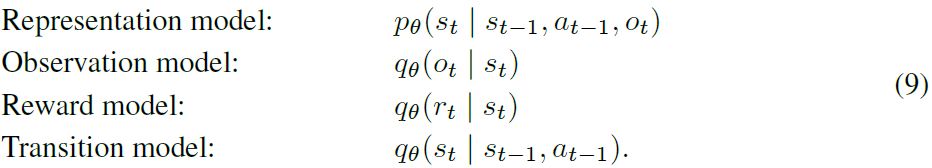
共同优化组件以增加变异下限(ELBO; Jordan等,1999),或更普遍的是变异信息瓶颈(VIB; Tishby等,2000;Alemi等,2016)。 如附录B所示,边界包括观察和reward的重构项以及KL正则化器。期望值是在数据集和表示模型下得出的
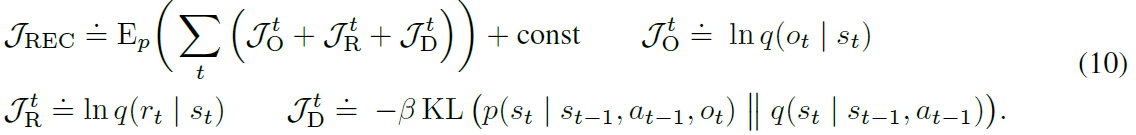
我们将Transition模型作为递归状态空间模型(RSSM; Hafner et al。,2018)实施,通过将RSSM与卷积神经网络(CNN; LeCun et al。,1989)相结合来实现表示模型, 观察模型作为转置的CNN,reward模型作为密集的网络。 组合参数向量θ通过随机反向传播进行更新(Kingma and Welling,2013; Rezende et al。,2014)。 图5显示了此模型的视频预测。 我们参考附录A和Hafner等(2018)模型详细信息。

图5:长期预测的重建。 我们将表示模型应用于两条保持轨迹的前5张图像,并在仅给出动作的情况下使用潜在动态向前预测45个步骤。 循环状态空间模型(RSSM; Hafner等人,2018)执行准确的长期预测,使Dreamer能够在紧凑的潜在空间中学习成功的action。
对比估计:预测像素可能需要较高的模型容量。 我们也可以通过从图像中预测状态来鼓励模型状态与观察值之间的相互信息(Guo et al。,2018)。 这将观察模型替换为状态模型
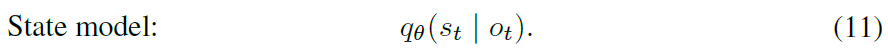
虽然重建目标使用的是观察边缘是一个常数的事实,但是我们现在面对状态边际。 如附录B所示,可以通过在当前序列批次的观察值o’上对状态模型求平均,通过噪声对比估计(NCE; Gutmann和Hyvärinen,2010; Oord等人,2018)进行估计。直观地讲,![]() 使状态可从当前图像预测,而
使状态可从当前图像预测,而![]() 保持状态多样化以防止崩溃
保持状态多样化以防止崩溃
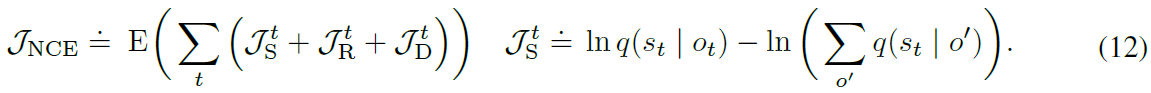
我们将状态模型实现为CNN,并再次使用随机反向传播对组合参数矢量θ进行优化。 在避免像素预测的同时,此绑定可以有效提取的信息量有限(McAllester和Statos,2018)。 我们在图8的实验中根据经验比较reward,重建和对比目标。
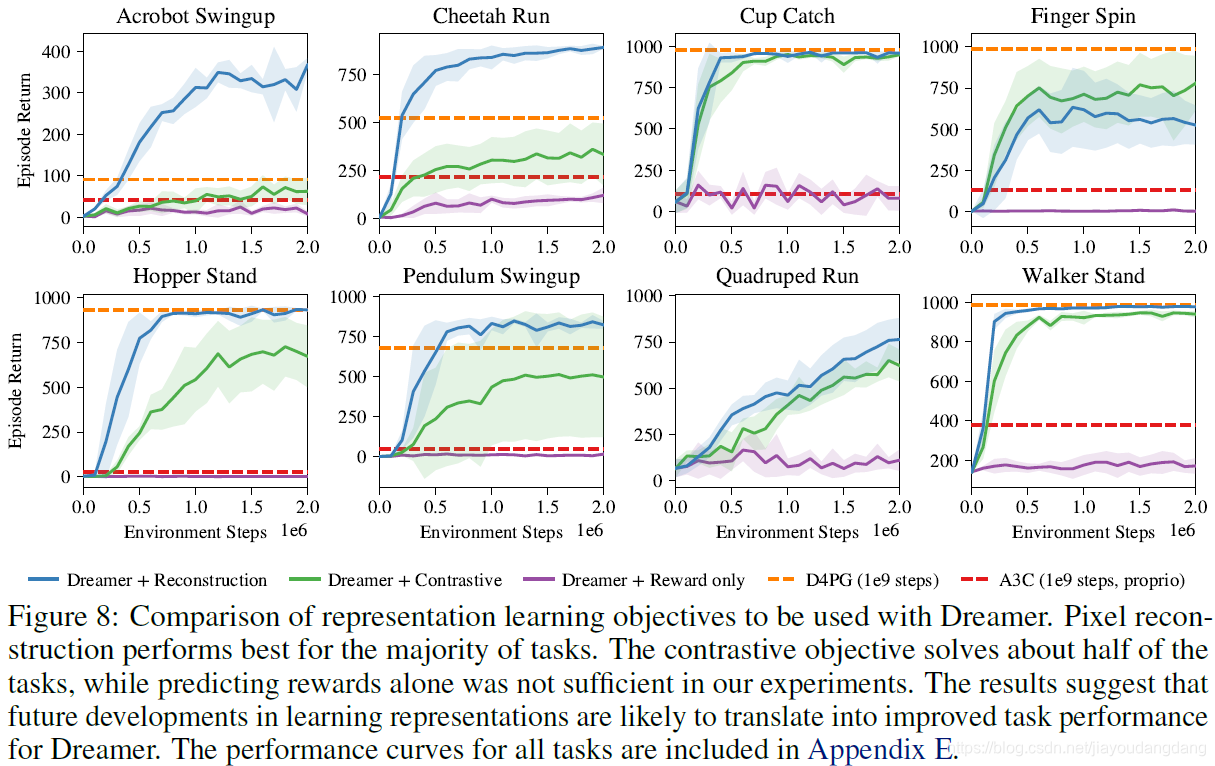
图8:与Dreamer一起使用的Representation learning目标的比较。 像素重建在大多数任务中表现最佳。 对比目标可以解决大约一半的任务,而仅靠预测reward在我们的实验中是不够的。 结果表明,学习表示形式的未来发展可能会转化为Dreamer改进的任务性能。 附录E中包含所有任务的性能曲线。
5 相关工作
先前的工作通过无导数策略学习或在线计划来学习潜在的动态视觉控制,通过多步预测来增强无模型agent,或者使用Q值的解析梯度或多步reward,通常用于低维任务。相比之下,Dreamer使用解析梯度来纯粹通过潜在的想象力来有效地学习Long horizonsaction,以进行视觉控制。
潜在动态控制:E2C(Watter等,2015)和RCE(Banijamali等,2017)将图像嵌入以在紧凑的空间中向前预测以解决简单任务。world model(Ha and Schmidhuber,2018)通过两个阶段的过程学习潜在动态,以发展想象中的线性控制器。 PlaNet(Hafner et al。,2018)共同学习它们并通过潜在的在线计划解决视觉运动任务。 SOLAR(Zhang et al。,2019)通过在潜在空间中进行有指导的策略搜索来解决机器人任务。 I2A(Weber et al。,2017)尝试了无模型策略的轨迹,而Lee et al。 (2019)和Gregor等。 (2019)学习信念表示以加速无模型agent人。
想象的多步返回:VPN(Oh等,2017),MVE(Feinberg等,2018)和STEVE(Buckman等,2018)从重播缓冲区中学习多步Q学习的动态。 AlphaGo(Silver et al。,2017)将行动和状态值的预测与计划结合起来,并假设获得了真正的动力。同样假设访问动态,POLO(Lowrey等人,2018)计划通过学习value集成来探索。 MuZero(Schrittwieser et al。,2019)学习特定于任务的reward和value模型来解决具有挑战性的任务,但需要大量经验。 PETS(Chua等人,2018),VisualMPC(Ebert等人,2017)和PlaNet(Hafner等人,2018)使用无导数优化在线计划。 POPLIN(Wang and Ba,2019)通过自我模仿改善了在线计划。 Piergiovanni等。 (2018)通过潜在的动态模型通过想象力学习机器人策略。使用神经网络梯度进行规划已显示出了一些小问题(Schmidhuber,1990; Henaff等,2018),但在规模上一直面临挑战(Parmas等,2019)。
分析value梯度:DPG(Silver等人,2014),DDPG(Lillicrap等人,2015)和SAC(Haarnoja等人,2018)利用学习到的即时行动value的梯度来通过经验重播来学习策略。 SVG(Heess et al。,2015)通过分析一步模型预测的值梯度来减少无模型的基于策略的算法的方差。 Byravan等人的并行工作。(2019)使用潜在的想象力和确定性模型进行导航和操纵任务。 ME-TRPO(Kurutach et al。,2018)通过对本体感受输入的预期reward梯度来加速原本无需模型的药物。 DistGBP(Henaff et al。,2017; 2019)在简单任务中使用模型梯度进行在线规划。
6 实验
我们通过实验评估Dreamer在各种控制任务上的作用。 我们设计了实验,以将Dreamer与文献中当前的最佳方法进行比较,并评估Dreamer解决远景,连续动作,离散动作和提早终止任务的能力。 我们进一步比较了world model的学习目标的正交选择。 有关我们所有Dreamer实验和视频的源代码,请访问https://danijar.com/dreamer。
控制任务:Dreamer在DeepMind Control Suite的20个视觉控制任务上进行了评估(Tassa等人,2018),如图2所示。这些任务带来了各种各样的挑战,包括稀疏的reward,联系动态和3D场景。 我们选择了Tassa等人完成的任务(2018)报告图像输入的非零性能。 特工观察是形状为64*64*3的图像,动作范围是1到12维,reward范围是0到1,情节持续1000步,并且具有随机初始状态。 我们在任务之间使用R = 2的固定动作重复。 我们进一步评估Dreamer对Atari游戏(Bellemare等,2013)和DeepMind Lab级别(Beattie等,2016)的子集上的离散动作和提前终止的适用性,如附录C中所述。
实施:我们的实施使用TensorFlow概率(Dillon等,2017)。 每次训练我们都使用单个Nvidia V100 GPU和10个CPU内核。 我们的Dreamer实施的培训时间约为控制套件上每106个环境步骤3个小时,而使用PlaNet进行在线规划则需要11个小时,而D4PG则需要24个小时才能达到类似的性能。 我们在所有连续任务中使用相同的超参数,在所有离散任务中使用相同的超参数,详细信息请参见附录A。除非另有说明,否则通过重构学习world model。
基准方法:D4PG(Barth-Maron等人,2018)是DDPG的改进版本(Lillicrap等人,2015),使用分布式收集,分布式Q学习,多目标步骤返回,并按优先顺序重播。我们将D4PG的像素输入和A3C的分数(Mnih等,2016)与Tassa等的状态输入包括在内。(2018)。 PlaNet(Hafner et al。,2018)学习了与Dreamer相同的world model,并通过在线计划选择了行动而没有行动模型,并大大提高了D4PG和A3C的数据效率。 我们使用R = 2重新运行PlaNet以进行统一的实验设置。 对于Atari,我们展示了Castro等人报告的SimPLe(Kaiser等人,2019),DQN(Mnih等人,2015)和Rainbow(Hessel等人,2018)的最终性能。 (2018),并为DeepMind Lab的IMPALA(Espeholt et al。,2018)提供指导。
性能:为了评估Dreamer的性能,我们将其与最新的强化学习代理进行了比较。 结果汇总在图6中。在经过5106个环境步骤后,Dreamer在所有任务中的平均得分为823,超过了强大的无模型D4PG代理的性能,该代理在108个环境步骤中的平均得分为786。 同时,Dreamer继承了PlaNet的数据效率,确认了学习的world model可以帮助从少量经验中推广。 Dreamer的经验成功表明,通过world model通过潜在的想象力学习action可以胜过基于经验重播的顶级方法。
Long horizons:为了研究其学习Long horizonsaction的能力,我们将Dreamer与从世界模型在不同视距长度得出action的替代方法进行了比较。为此,我们学习了一种action模型,可以在没有价值模型的情况下最大化想象中的reward,并与使用PlaNet的在线计划进行比较。图4显示了在不同的想象力范围内的最终性能,证实了价值模型使Dreamer对范围更加稳健,即使对于较短的范围也表现良好。附录D中显示了水平范围为20的所有19项任务的性能曲线,其中Dreamer在20条任务中有16条具有4条联系,胜过其他方案。
Representation learning:Dreamer可以与任何可区分的动态模型一起使用,该模型可以预测给定动作和过去观察结果的未来回报。由于表示学习目标与我们的算法正交,因此我们将比较第4节中描述的三种自然选择:像素重建,对比估计和纯收益预测。图8显示了不同表示学习方法在任务性能方面的明显差异,其中像素重建在大多数任务上的表现优于对比估计。这表明Dreamer在表示学习方面的未来改进很可能转化为更高的任务性能。仅reward预测在我们的实验中还不够。本文的附录中还包括其他消融。
7 总结
我们介绍了Dreamer,这是一个纯粹通过潜在的想象力学习长距离action的代理。 为此,我们提出了一种演员批评者方法,该方法通过传播多步值的解析梯度通过学习的潜在动力学来优化参数策略。 在图像输入的各种挑战性连续控制任务上,Dreamer在数据效率,计算时间和最终性能方面均优于以前的方法。 我们进一步证明Dreamer适用于具有离散操作和情节提前终止的任务。 未来关于表征学习的研究可能会将潜在的想象力扩展到视觉复杂度更高的环境。
代码:https://github.com/danijar/dreamer


















 904
904

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











