










Dreamer是加拿大多伦多大学和谷歌的工作,有三个版本。
20年3月提出的Dreamer v1(“Dream To Control: Learning Behaviors By Latent Imagination“)。
学习的世界模型总结一个智体的经验,促进学习复杂的行为。虽然通过深度学习,从高维感官输入中学习世界模型变得可行,但有许多潜在的方法可以从中推导行为。Dreamer,一种强化学习智体,纯粹通过潜在的想象力来解决图像中的长期任务。将学习状态值的分析梯度传播回世界模型紧凑状态空间中所想象的轨迹,这样可有效地学习行为。
如图所示:Dreamer从过去的经验中学习世界模型,并通过想象的轨迹反向传播价值估计,有效地学习潜在空间中的远见卓识行为。
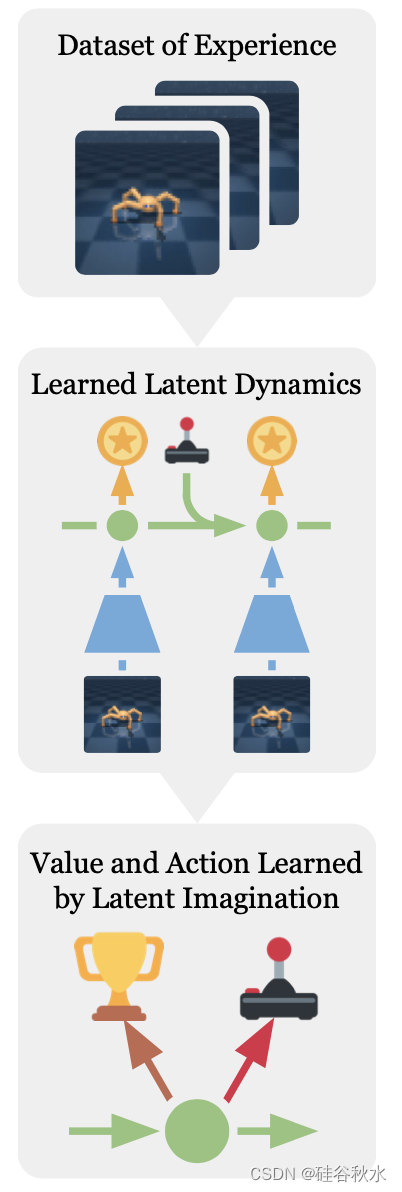
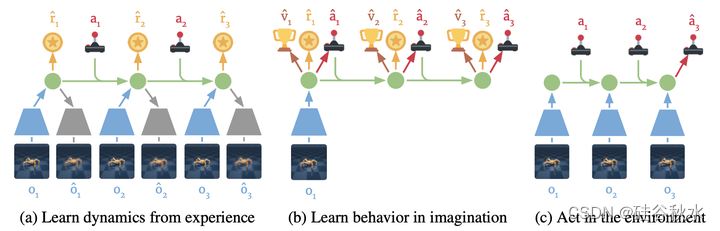
如图所示是Dreamer的组件。(a) 从过去经验的数据集中,智体学习将观察和行动编码为紧凑的潜状态,例如通过重建,并预测环境奖励()。(b) 在紧凑的潜空间中,Dreamer预测状态值和动作,将梯度传播回想象的轨迹,最大化未来价值预测。(c) 智体对事件的历史进行编码,计算当前模型状态并预测要在环境中执行的下一个动作。
关于智体的伪代码,见如下算法流程图:

22年2月提出Dreamer v2(“Mastering Atari With Discrete World Models”)。
Dreamer V2,是一种强化学习智体,纯粹从强大世界模型的紧凑潜空间预测中学习行为。世界模型用离散表示,并且与策略分开训练。Dreamer V2是一个在单独训练世界模型中学习行为,在Atari 55项任务的基准上实现类人性能的智体。在相同的计算预算和墙钟时间(wall-clock time)下,Dreamer V2达到了200M帧,并超过了顶级单GPU智体IQN和Rainbow的最终性能。DreamerV2也适用于具有连续动作的任务,可以学习复杂人形机器人的精确世界模型,并从像素输入解决站立和行走问题。
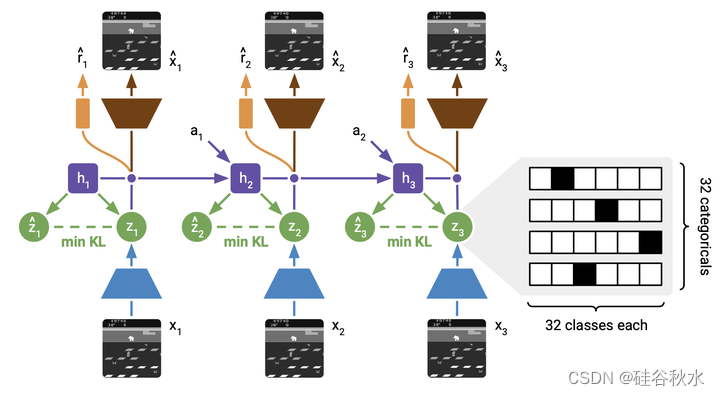
如图是世界模型学习框架。用CNN对图像的训练序列进行编码。RSSM用一系列确定性递归状态。在每一步,计算包含关于当前图像信息的后验随机状态,以及试图在不访问当前图像情况下预测后验的先验随机状态。与PlaNet和Dreamer V1不同,Dreamer V2的随机状态是多个分类变量的向量。KL损失既训练了先验,又正则化了后验从图像中融合了多少信息。正则化增加了对新输入的鲁棒性。它还鼓励重复使用过去步骤中的现有信息来预测奖励和重建图像,从而学习长期依赖关系。
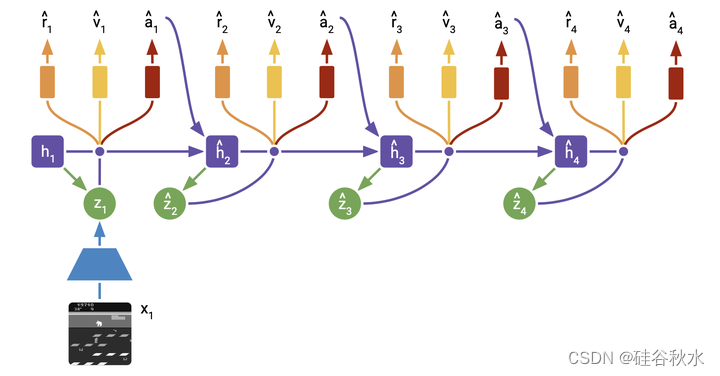
如图所示是AC学习,把学习的先验知识用于想象。上图中学习的世界模型用于从紧凑潜空间中想象的轨迹中学习策略。轨迹从模型训练期间计算的后验状态开始,并对行动者网络的动作进行采样进行前向预测。批评者网络预测了每个状态未来奖励的预期总和。批评者在想象奖励上使用了时间差(temporal difference)学习。强化梯度、世界模型的直通梯度或它们的组合。训练行动者最大化批评者的预测。
一些细节如算法1和2所示:


23年1月提出Dream v3(“Mastering diverse domains through world models”)。
DreamerV3,是一种基于世界模型的通用且可扩展的算法,在具有固定超参的广泛领域中优于以前的方法。这些领域包括连续和离散的动作、视觉和低维输入、2D和3D世界、不同的数据预算、奖励频率和奖励尺度。DreamerV3具有良好的规模特性,较大的模型直接转化为更高的数据效率和最终性能。DreamerV3开箱即用,是一个在没有人类数据或课程的情况下在Minecraft中从头开始收集钻石的算法。
如图是DreamerV3的训练过程。世界模型将感官输入编码为离散表示,由具有给定动作带递归状态的序列模型预测。输入重构为学习信号形成表示。行动者和批评者从世界模型预测的抽象表示轨迹中学习。
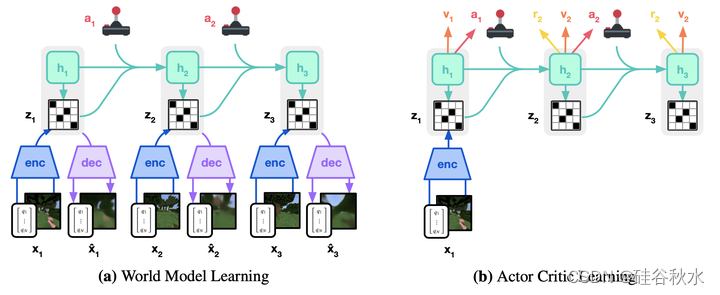
DreamerV3建立在DreamerV2算法的基础上,主要变化如下。
•符号预测。对世界模型的输入进行符号编码,并用具有平方差的符号预测来重建输入。奖励预测器和批评者使用twohot符号预测,这是分布式强化学习的一种简单形式。
•世界模型正则化。试验了不同的方法来消除调整KL正则化的需要,包括针对固定的KL值。一个简单而有效的解决方案是将DreamerV2中引入的KL平衡与原始Dreamer算法中使用的自由bits相结合。
•策略正则化。针对密集和稀疏奖励时,行动者使用固定熵正则化具有挑战性。将大的return范围缩小到[0,1]区间,而不放大接近零的return,可克服这一问题。使用百分位数来忽略return范围中的异常值,尤其是在随机环境中。将策略规范化到自己的EMA或CMPO规范化中,没有得到改进。
•Unimix分类。将世界模型表示和动力学以及行动者网络的分类分布参数化为1%均匀分布和99%神经网络输出的混合物,确保每个类别的概率质量最小,从而保持对数概率和KL偏差良好。
•架构。用类似的网络架构,但用层规范化(LN)和SiLU作为激活函数。为了更好的框架支持,用步长为2和内核大小为3的相同填充卷积,而不是使用较大内核的有效填充卷积。DreamerV3的鲁棒性能够用性能贡献的大型网络。
•批评者EMA正则化。用快速批评者网络计算λ- return,并将批评者输出正则化为其自身权重的EMA,而不是用慢速批评者计算return。然而,这两种方法在实践中表现相似。
•回放缓冲。DreamerV2使用的回放缓冲只回放已完成episodes的时间步。为了缩短反馈循环,DreamerV3从所有插入的批量长度大小的子序列中均匀采样,而不考虑事件边界。
•超参数。DreamerV3的超参经过调整,在视觉控制套件和Atari200M中同时表现良好。在没有进一步调整的情况下对新领域进行训练,验证其通用性,包括Crafter、BSuite和Minecraft。

















 465
465

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









