







数据集和地图可以点赞关注收藏后评论区留下QQ邮箱或者私信博主要
聚类是一类机器学习基础算法的总称。
聚类的核心计算过程是将数据对象集合按相似程度划分成多个类,划分得到的每个类称为聚类的簇
聚类不等于分类,其主要区别在于聚类所面对的目标类别是未知的
k-means聚类也称为K均值聚类算法,是典型的聚类算法,对于给定的数据集和需要划分的类数K,算法根据距离函数进行迭代处理,动态 的把数据划分成K个簇,直到收敛为止,簇中心也称为聚类中心
先来个小例子
这个是通过聚类算法对鸢尾花数据集的预测结果
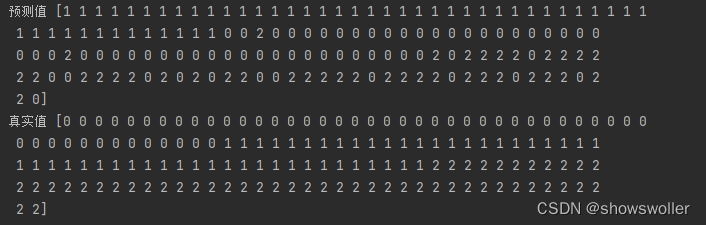
代码如下
from sklearn.cluster import KMeans
from sklearn import datasets
import numpy as np
iris=datasets.load_iris()
x=iris.data
y=iris.target
clf=KMeans(n_clusters=3)
model=clf.fit(x)
predicted=model.predict(x)
print("预测值",predicted)
print("真实值",y)
print()
<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1357
1357

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











