







 本文详细介绍了四种常见的排序算法:冒泡排序、快速排序、归并排序和基数排序,包括它们的原理、时间复杂度分析以及C++实现。冒泡排序是简单的交换排序,时间复杂度为O(n^2);快速排序平均时间复杂度为O(nlog2n),是基于比较的排序算法中效率较高的;归并排序也是O(nlog2n),利用分治法,适合大规模数据;基数排序适用于位数小的数列,时间复杂度为O(d(r+n)),其中d是位数,r是每位的取值范围。
本文详细介绍了四种常见的排序算法:冒泡排序、快速排序、归并排序和基数排序,包括它们的原理、时间复杂度分析以及C++实现。冒泡排序是简单的交换排序,时间复杂度为O(n^2);快速排序平均时间复杂度为O(nlog2n),是基于比较的排序算法中效率较高的;归并排序也是O(nlog2n),利用分治法,适合大规模数据;基数排序适用于位数小的数列,时间复杂度为O(d(r+n)),其中d是位数,r是每位的取值范围。
一. 交换排序
1. 冒泡排序
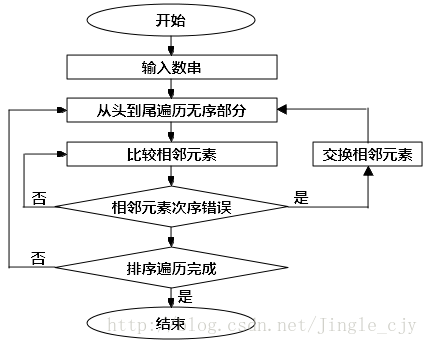
冒泡排序是所有排序算法中最原始的,重复的遍历要排序的数串,一次比较两个元素,假如顺序错误就交换这两个元素,直到不再需要交换,则数串已经排序完毕。数串中的最大元素会逐渐冒上来,所以称之为“冒泡排序”。
冒泡排序流程图如下所示:
时间复杂度分析
无论数串的紊乱状态如何,只要数串的长度确定,比较次数就是确定的。假设数串的长度为n,那么每次遍历(即内层循环)需要的比较操作为 (n-i-1) 步,而i又是从0遍历到 (n-1) 。因此最后得出的比较步数为 n(n−1)2 ,比较操作时间复杂度为 O(n2) 。
另外,交换操作也十分费时,每次交换两个数字至少需要三步,但是交换操作受数串的紊乱程度的影响。最好情况是一开始就有序,不需要交换。最坏情况是全部需要交换,也就是需要 3n(n−1)2 步,时间复杂度也为 O(n2) 。空间复杂度分析
只开数组不用递归,因此空间复杂度就维持在O(1)的常数级水平。优劣及稳定性
冒泡排序的效率比较一般,虽然都是 O(n2) ,但是冒泡排序前面的系数比较大,而且还有余项,因此实际用时都比较长。
但是冒泡排序是稳定的。
2. 快速排序
快速排序也是分治的思想,将不断缩小一个大问题的规模,使其变成可处理的小问题。假设有如下场景时,有两堆数,一堆只有一位数,另外一堆只有两位数,那么要如何实现排序?显然是分别对两个堆进行排序,然后再直接拼接起来就可以了。回归到本质,我们是找到一个分隔标准分成两个堆,然后再向上述的做法进行处理。这也就是快速排序算法的由来。此时距离构建算法我们还要解决三个关键问题:一是怎样分数组,二是要将数组分到多小;三是怎么合并这些数组。
对于第一个问题,我们发现要把数组缩小规模,类似于归并排序取中间元素,快速排序也要找到一个对照的标准元素,然后以这个元素为参照,比这个元素小的放在一起,比这个元素大的放在另一堆,这就完成了拆分的过程。但这又引发了一个问题,如何找标准元素。首先考虑标准元素要找数组里面的还是数组外面的,这一点很好判断,如果是数组外的元素,我们不好确定到底要取多大,这样很容易造成划分的不均匀(极端的例子就是都被放在一个堆里),因此应当要选择数组里面的元素(这样的好处是就算被选择的数字是最大元素或者最小元素,也无需担心出现死循环的问题,所以这个元素的选取其实是任意的),我们可以直接选取数串的第一个元素作为先导元素。但是此时假如数串原本是有序的,那么每次选取的先导元素都是最小/最大值,这导致了算法的效率十分低下,所以我们可以随机选取先导元素。
对于第二个问题,显然我们要将数组划分到最原始最简单的小问题,对于排序来说最原始的数组就是只含有一个元素的数组,因为此时的数组一定是有序的。
对于第三个问题,快速排序比归并排序要简单。因为递归之后第一堆元素都比对照元素要小,第二堆元素都比对照元素要大。因此我们直接将排完序后的第一堆元素放在对照元素前面,将排完序后的第二堆元素放在对照元素的后面,就完成了合并过程。
弄清楚算法的大致过程后,我们应当考虑用什么数据结构来存储数据。对比数组的随机读取结构及链表的链式结构:对于划分数据,此时需要频繁地移动数据,对于链表来说需要从头遍历到对应元素,而且需要大量的指针交换,而数组只需要控制下标即可,虽然交换时间差不多,但是数组更好实现,所以数组优于链表;对于合并两个有序串,数组通过控制首末位置的下标就能够很好的实现,链表也不难,直接把第二段的头指针接到第一段的末尾即可,但是找到第一段的末尾需要遍历整个前半段链表,因此链表在此操作上也没有优势,所以一般选择数组实现快速排序。
照例简单的模拟一下过程,有待排序数串5 2 4 6 1 3,具体如下:
时间复杂度分析
快速排序中递归函数相当于任务分配,其调用过程中用时基本上可以忽略不计,因此主要耗时的环节落在了比较和交换上,我们先分析某一层递归的情况,假设这一层递归传进的数串长度为n,那么每个元素都要与pivot做一次比较,一共 n-1 次,因

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 410
410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









