







MoE:Mixture of Experts 混合专家模型
1、MoE优缺点:
推理速度:相当于占用更多的GPU显存,但是因为只使用其中1/4甚至更低的参数,推理时速度更快。相比于非MoE的模型,快多少倍?
低成本:与具有相同总参数数量的密集模型相比,训练和推理上是会好一些,但是效果也会差一些。
GPU VRAM 需求:一个问题是它们对 VRAM 的高需求,因为所有专家都需要加载到内存中,即使在某个特定时间只使用了 1 或 2 个。
微调困难:历史上,MoEs 在微调方面存在困难,经常导致过拟合。尽管现在在这方面已经取得了许多进展,并且变得更容易。
训练和推理的权衡:尽管提供了更快的推理,但它们需要对 VRAM 和计算资源进行谨慎管理。还是时间和空间的平衡问题。
GPT4的参数量预估:GPT4 -> 8 x 220B 参数 = 1.7T 参数 (1.7万亿参数)
GPT-3.5 大约有 175B 参数
2、Mistral 8x7B MOE
8 个专家模型,每次推理时激活 2 个专家模型。总参数量 46.7B,每次推理用 12.9B。其效果自然比 14B强、速度比 48B快。
3、Gshard MoE的核心架构
DeepSpeed的MoE模型架构是Gshard。
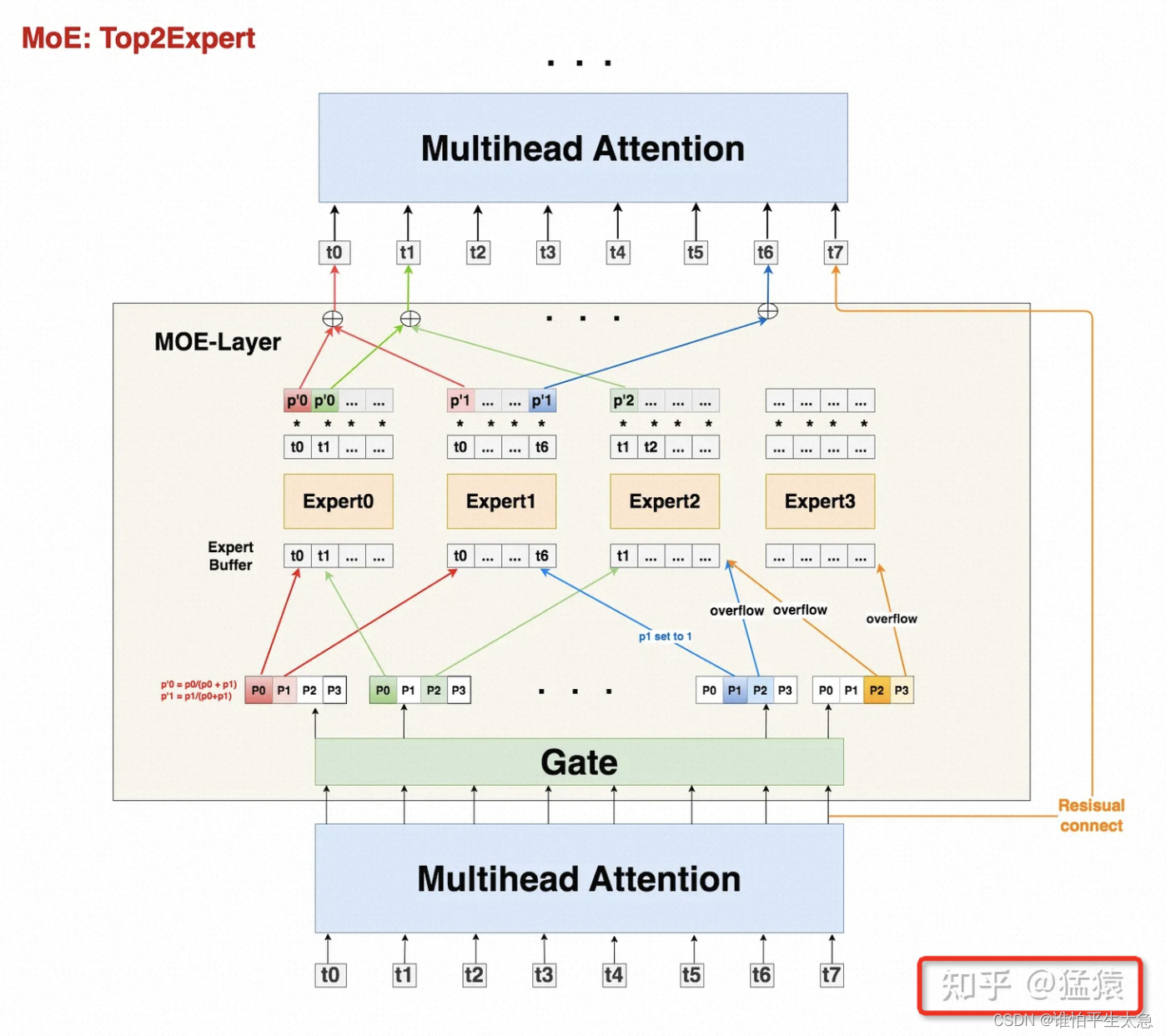
首先,我们有一串过Attention层后的token序列
我们通过Gate,计算每个token去往每个expert的概率
我们希望不同expert处理的token数尽量均衡,所以我们同时采取三方面优化:
Capacity: 为每个expert设置capacity(expert buffer),限制它能处理的最大token数量,多出来的token算为溢出,在top2Expert都溢出的情况下,该token会被直接发去下一层attention。
Random Routing: 每个token一定会被发去1st Expert,在此基础上我们通过random routing加噪的方式,重新选出2nd expert。在做完capacity + random routing后,我们最终确认了每个token要发去的top2expert和其对应的权重,通过加权计算的方式,确认Moe-Layer最终的输出结果。
Auxiliary Loss:添加辅助损失函数,对expert负载不均的情况做进一步惩罚。
回到上图的处理方式是:
如果只有单个expert溢出,那么就把另一个expert的权重值为1,然后正常参与加权计算(如图中t6)
如果2个expert都溢出,那么该token就不经过任何expert,直接通过残差连接的方式,原样发去下一层的Attention上(如图中t7)
Capacity的计算公式:
S是 token数,E是 专家总数, K是 选择专家数。
capacity_factor 调节每个expert多处理或少处理一些token,min_capacity 容量下界。
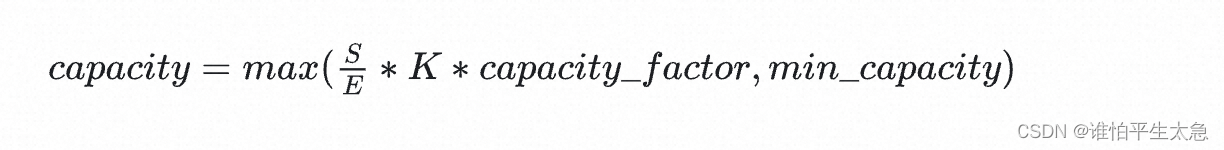

















 771
771

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









