







 本文通过一个矩阵加法的测试案例分析OpenCL的性能。在取消调用clfinish()函数后,GPU性能显著提升,表明在处理复杂计算任务时,应合理利用指令队列以避免不必要的等待,从而提高计算效率。优化后,LSTM项目计算性能翻倍,证明正确编程对发挥计算机性能的重要性。
本文通过一个矩阵加法的测试案例分析OpenCL的性能。在取消调用clfinish()函数后,GPU性能显著提升,表明在处理复杂计算任务时,应合理利用指令队列以避免不必要的等待,从而提高计算效率。优化后,LSTM项目计算性能翻倍,证明正确编程对发挥计算机性能的重要性。
用的公司的电脑,配置如下:
CPU: AMD Athlon X4 830 (3.0GHz 四核)
内存: 8GB
GPU: nVIDIA GT710 (0.954GHz 192cores 1CU)
显存: 1GB
上图,浮点性能测试。
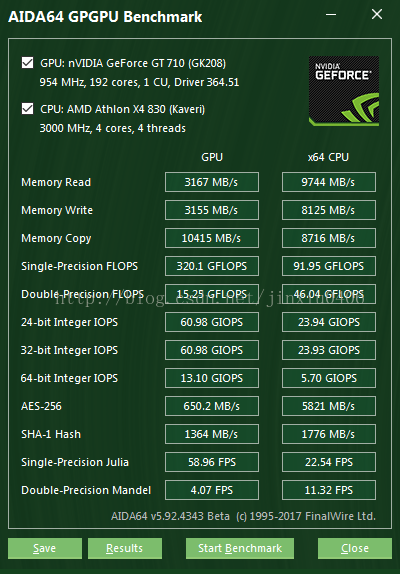
CPU的 float 浮点性能 91.95GFlops。GPU为 320.1GFlops。浮点数计算 GPU领先 3倍多。
然而 这是面对简单计算任务的情况。算是理想性能,不是项目的实际情况。
----------------------------
下面上案例分析:这是一个矩阵加法的测试项目。水平有限,性能一般般。两个矩阵相加,重复1000次。评估单次计算的耗时。
/// <summary>
/// func opencl特性测试,host to gpu 传输特性。
/// </summary>
[TestMethod]
public void NC07_gpu()
{
string code = OpenCLMode.OCL.oclModel.LoadCode(filename);
oclm = new OpenCLMode.OCL.oclModel(code);
int i = 100, j = 100;
float[,] A = new float[i, j];
float[,] B = new float[i, j];
float[,] C = new float[i, j];
RandomData(A);//产生随机数据
RandomDa 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1216
1216

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









