






 本文介绍了DETR(DetectedTransformers)这一端到端目标检测方法,基于Transformer架构,无需预定义候选框和NMS。文章详细讲解了DETR的网络结构,包括CNNbackbone、Transformer编码器和解码器,以及FFN模块。重点阐述了如何通过位置编码和二分图匹配算法解决无序输出的问题。
本文介绍了DETR(DetectedTransformers)这一端到端目标检测方法,基于Transformer架构,无需预定义候选框和NMS。文章详细讲解了DETR的网络结构,包括CNNbackbone、Transformer编码器和解码器,以及FFN模块。重点阐述了如何通过位置编码和二分图匹配算法解决无序输出的问题。
DETR论文题目中有提到end-to-end一词,到底什么是端到端检测呢? end-to-end(端对端)的方法,一端输入我的原始数据,一端输出我想得到的结果。 只关心输入和输出,中间的步骤全部都不管。大白话解释就是跟传统目标检测算法不同,DETR不需要预定义候选框,也不需要NMS算法处理冗余的框,理想状态就是一个目标一个检测框。DETR是基于transformer的,不熟悉transformer的可以移步我的另一篇文章做简单了解。DETR是把一个目标检测的问题直接看作一个集合预测问题。
大白话transformer学习笔记(个人理解)_transformer白话-CSDN博客
DETR网络结构:
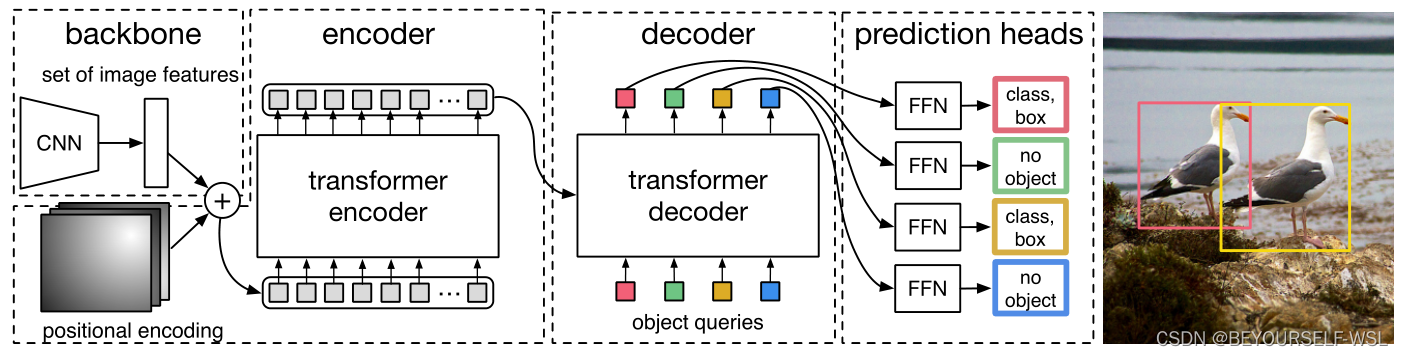
DETR主要分别分为三部分backbone用于提取特征,transformer的encoder,decoder 进行特征图处理,FFN进行目标预测。
Backbone:
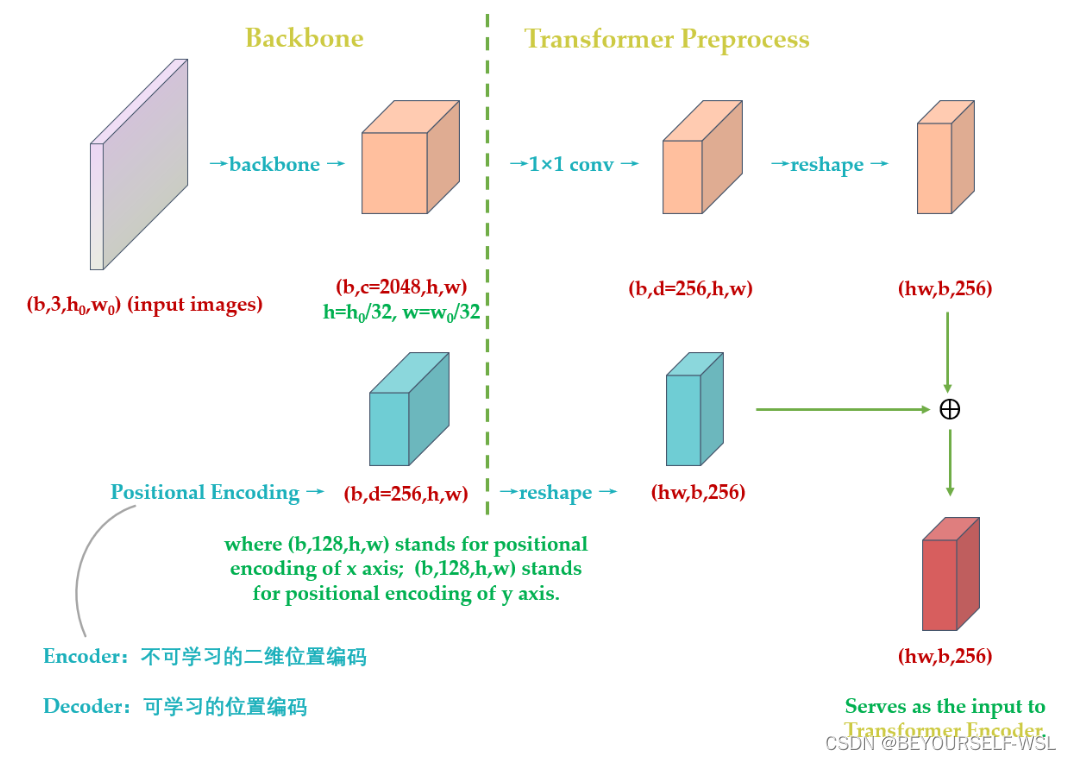
主干网络主要是使用cnn卷积得到特征图,输入是H*W*3大小的图片,经过卷积之后得到H'×W’×C大小的特征图,C在论文中是2048,H‘,W’分别为H/32,W/32。在输入到encoder块之前,特征图经过1×1卷积把通道数压缩为d(d=256)大小,之后再转化为序列数据为(HW,256)的特征图。特征图还添加了位置编码信息,此处的位置编码也是[HW,256]维度的,他与transformer的位置编码不同(transformer的位置编码只考虑x方向),它考虑了x和y两个方向,这更加符合图像特点。[HW,128]前128维为x方向的位置编码,[HW,128]后128维为y方向的位置编码。两个拼接起来就是[HW,256],这里我借用一位博主的图来展示位置编码与特征图的相加过程,详情参考知乎博主解答Vision Transformer 超详细解读 (原理分析+代码解读) (一) - 知乎 (zhihu.com)
Encoder:
此块与transformer的encoder一样,唯一不一样的地方就是在特征图输入到encoder块之后,在进行多头自注意力操作之前加了位置编码信息,且只对Q,K矩阵加了位置编码。如下图对比
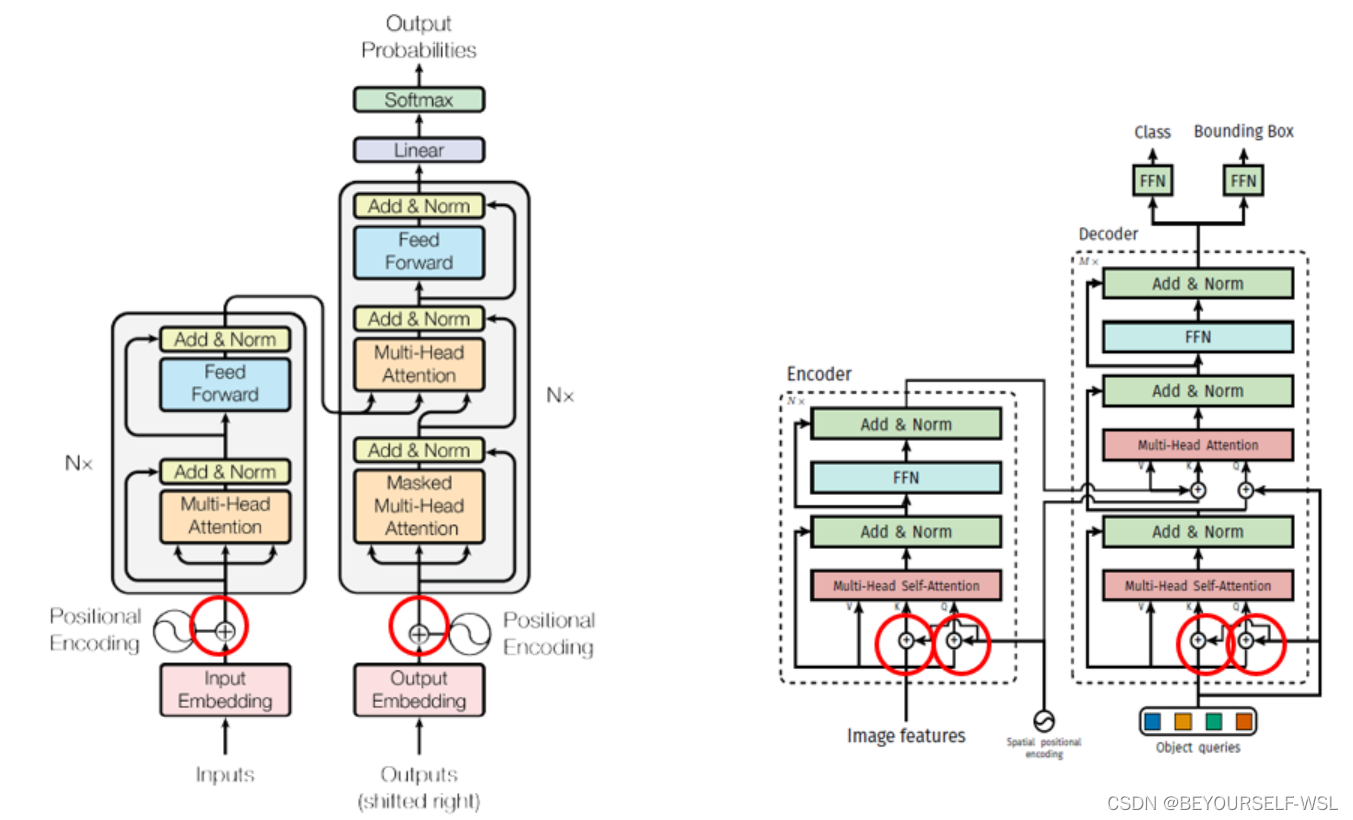
直接用cnn卷积后给decoder提供特征图ok嘛?舍弃encoder层
encoder的作用相当于就是把特征图中的目标区域加了大的权重,得到各个目标的注意力结果。让decoder解码查询encoder的输出特征图的时候重点关注有目标的区域。

Decoder:(这一块感觉难理解,有错望指正)
transformer中decoder的输入是一个一个词的顺序输入,此处是输入object queries可以并行计算所有类别物体。这里指定object queries为[100,256],也就是最多同时检测出100个类别物体,b为batch size大小。
【Decoder的输入一开始也初始化成维度为 (100,b,256) 维的全部元素都为0的张量,和Object queries加在一起之后充当第1个multi-head self-attention的Query和Key。第一个multi-head self-attention的Value为Decoder的输入,也就是全0的张量。】看图感觉Object queries做了位置编码的作用,且他是可学习的位置编码。然后第一个self-attention的输出作为Q,encoder的输出作为K,V矩阵,在把Q,K矩阵加上位置编码,传入到下一个attention块。DETR输出张量的维度是 (b,100,class+1) 和 (b,100,4)。前者是指100个预测框的类型,后者是指100个预测框的Bounding Box。
FFN:
最后的 FFN 是由具有 ReLU 激活函数且具有隐藏层的 3 层线性层计算的,或者说就是 1×1 卷积。FFN 预测框标准化中心坐标,高度和宽度,然后使用 softmax 函数激活获得预测类标签。
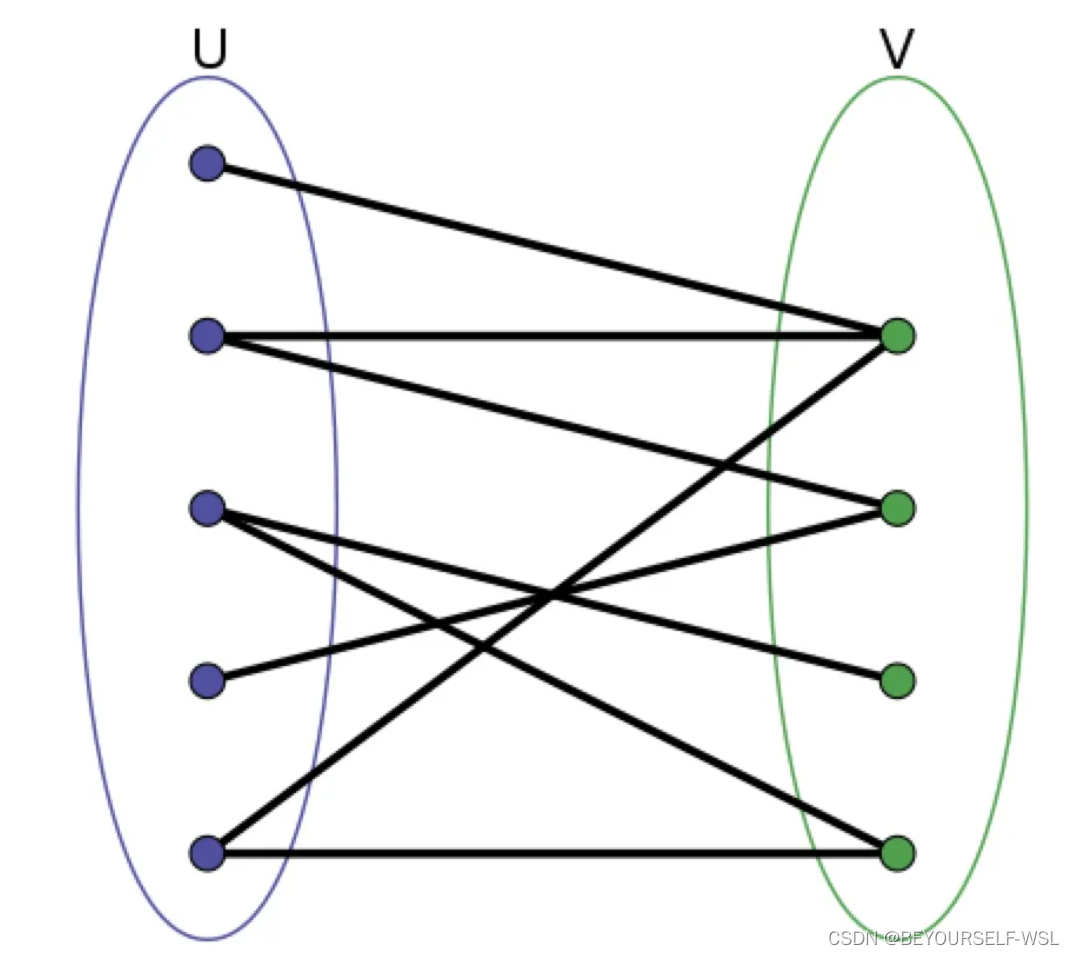
DETR得到的输出结果是无序的,我怎么确定现在这个类别,对应这个预测框?用匈牙利算法找到每个类别对应的预测框是哪个。这个算法相当于做了一个预测框与类别之间的映射关系,如下图。
详情解释:Vision Transformer 超详细解读 (原理分析+代码解读) (一) - 知乎 (zhihu.com)
目标函数:
DETR最后的输出是一个固定的集合,无论图片是什么都会得到N个框(N=100)
二分图匹配:比如现在有三个工人abc需要完成三个工作xyz,他们需要的时间工钱是不同的,就会构成一个三乘三的矩阵,二分图匹配呢就是最后能够找到唯一的一个解能够给每个人一个对应的最擅长的工作,又能使得三个工作完成后所花费的价钱最低。用匈牙利算法。此模型中可以假设行表示真实类别,列表示100个框,矩阵中的每个(i,j)处存放的值为下式计算得到的值,我们取出每个类别行对应的最优解,最优解对应的此列作为这个标签的预测框。
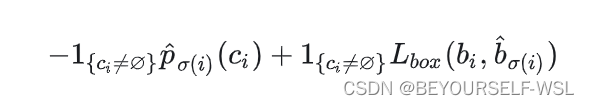
然后我们再把选出的框都挑出来,根据下式计算损失,损失计算公式为:
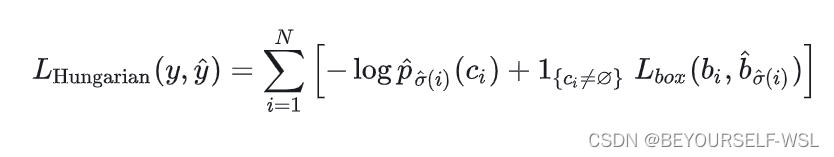
通过一步步最小化损失,进行反向传播更新Object queries。
个人理解,如有错误,望指出互相学习!!















 9930
9930











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









