






 本文详细介绍了Seq2Seq模型,包括其由encoder和decoder组成的结构,以及不同版本的语义向量C的使用。重点讨论了注意力机制如何解决长序列问题,并提到了TeacherForcing策略在训练中的作用。
本文详细介绍了Seq2Seq模型,包括其由encoder和decoder组成的结构,以及不同版本的语义向量C的使用。重点讨论了注意力机制如何解决长序列问题,并提到了TeacherForcing策略在训练中的作用。
Seq2Seq结构图:
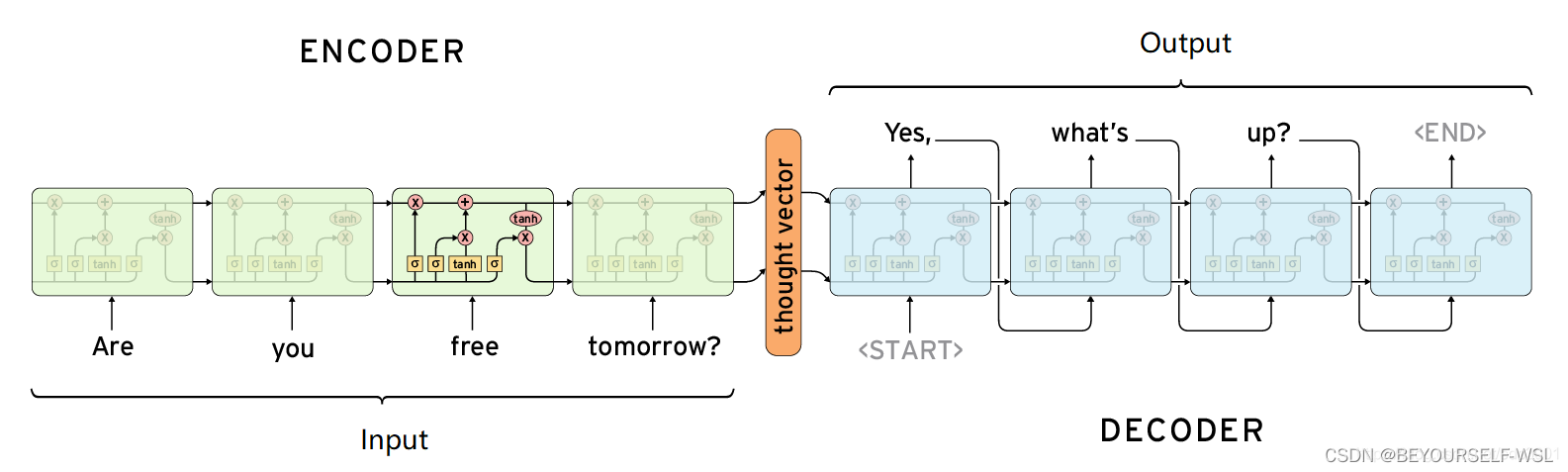
Seq2Seq是由encoder和decoder两个rnn结构组成。encoder负责理解输入的句子,把它转化为上下文向量,decoder负责对上下文向量进行处理解码,获得输出。Seq2Seq模型是输出的长度不确定时采用的模型。
自己搜索相关知识的时候,发现一会儿是这样的模型结构一会儿是那样的模型结构,把我都搞晕了。原来是Seq2Seq模型有几种常见的结构:
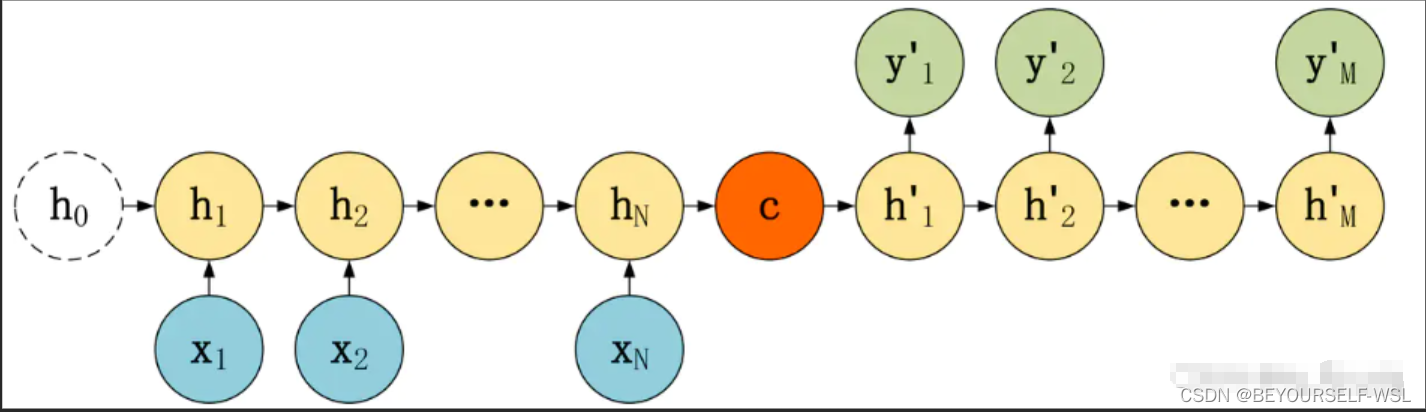
(1)语义向量C只作为初始状态参与运算,后面的运算都与语义向量C无关。
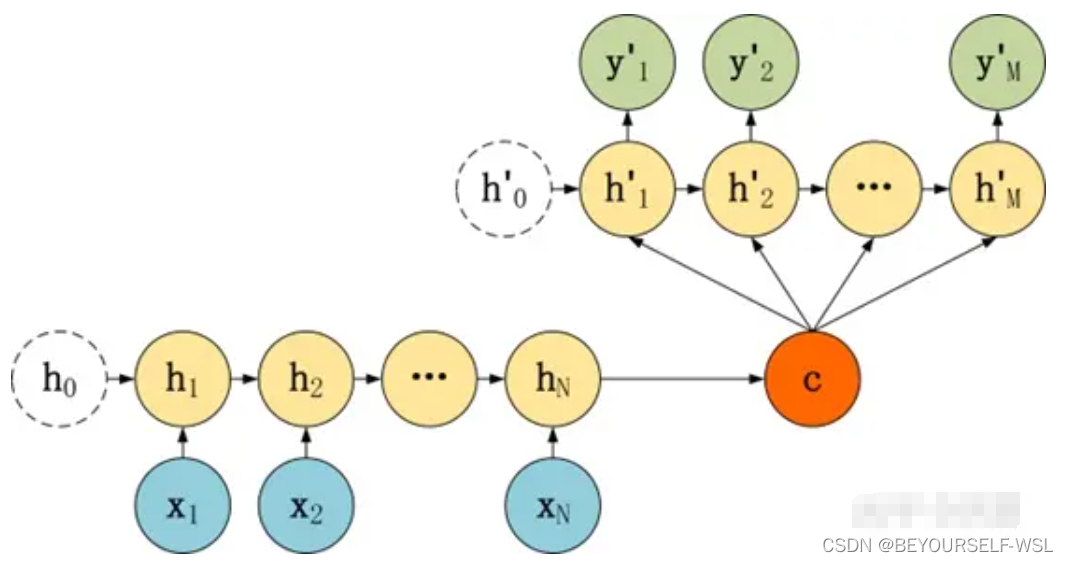
(2) 语义向量C参与了序列所有时刻的运算
(3) 语义向量C参与序列所有时刻的运算,另外上一时刻的输出也参与下一时刻的运算。
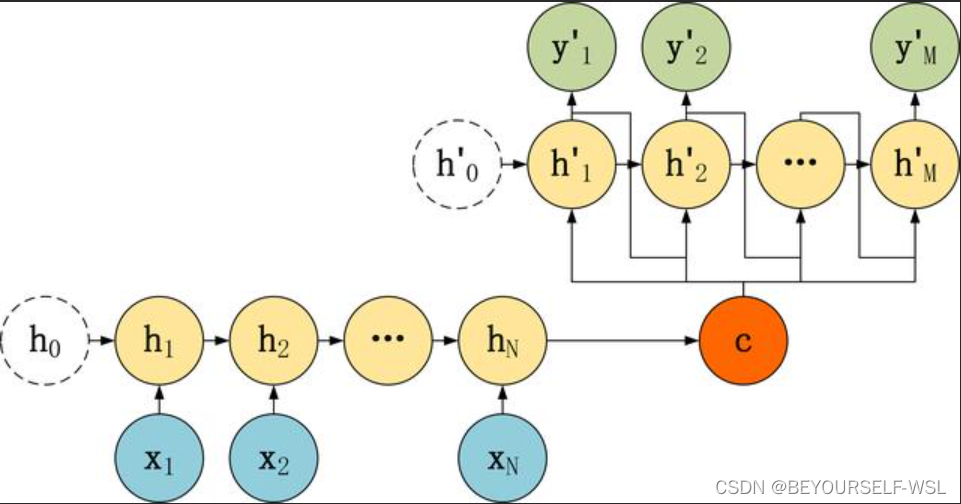
encoder部分都是一样的,主要是decoder部分的差异。 其中向量C可以通过多种方式得到,可以直接就是最后一个隐藏状态的值hN,也可以是最后一个隐藏状态的值经过变换得到,也可以是所有隐藏状态通过变换得到。如下图q表示某种变换。

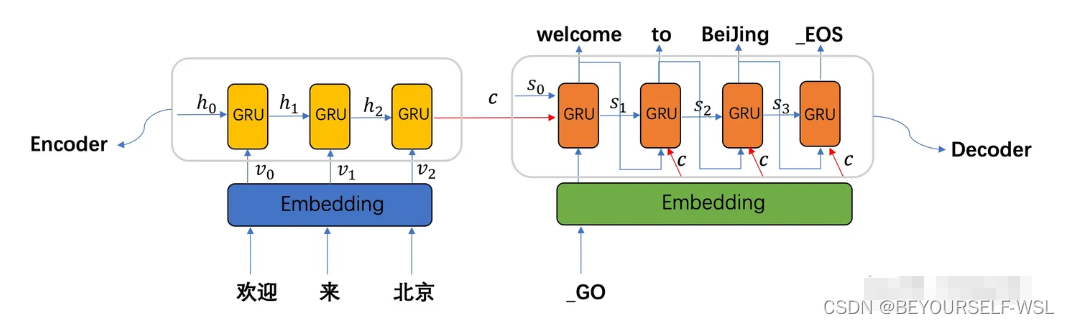
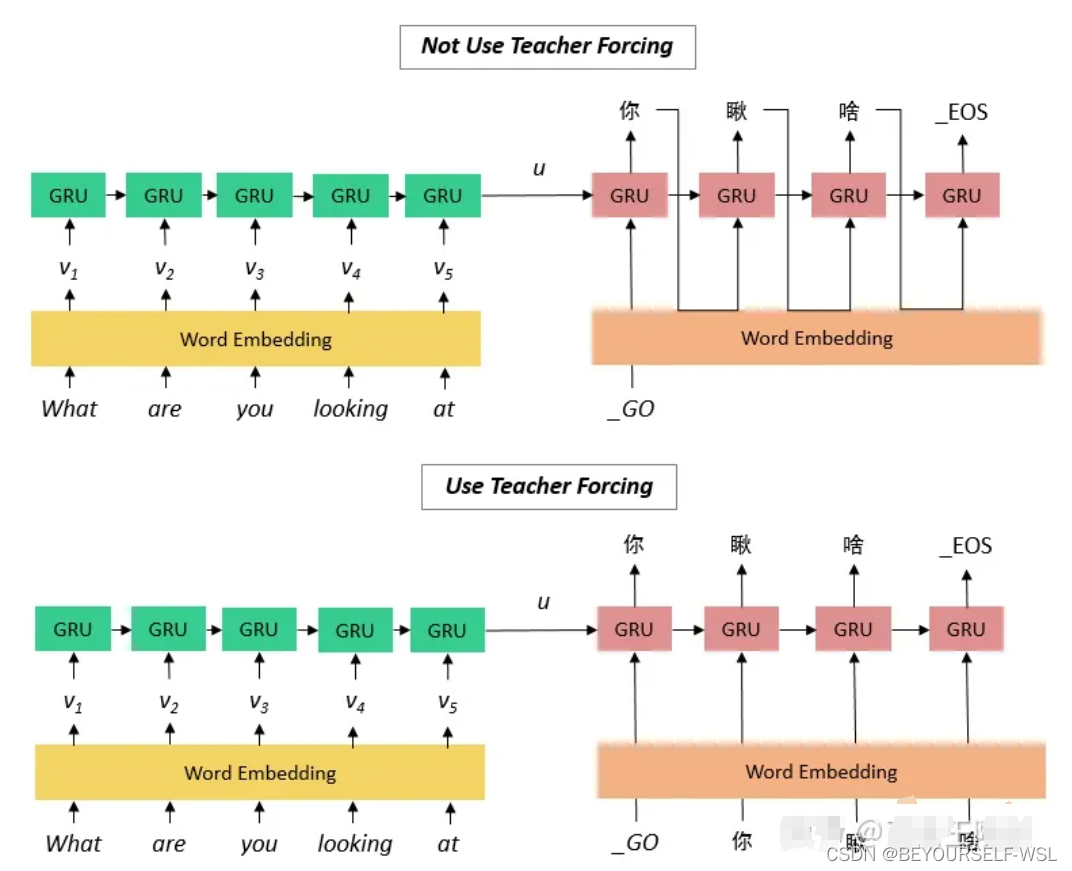
训练时: decoder第三种方法会把上一时刻解码的输出作为下一时刻的输入,但是如果上一时刻的解码出现很大的误差,就会持续往下传递,使得结果误差越来越大。Teacher Forcing(翻译下应该是老师push你,就是知道上一时刻正确答案的老师在此时刻拿上一时刻正确答案提示你)在一定程度上解决了这个问题,它的流程如下图所示,直接使用正确的输出作为输入。(测试阶段不可用teacher forcing)
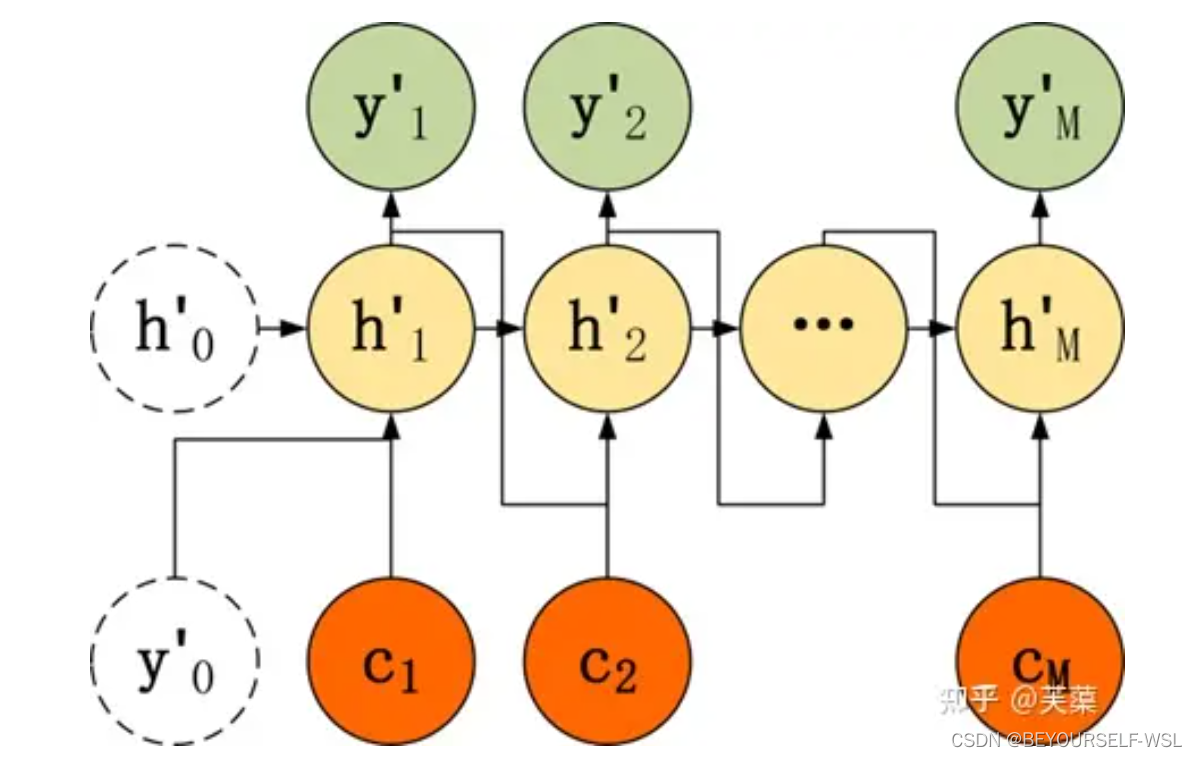
encoder把原输入句子所有的信息都编码在了一个向量C中, 但是RNN 存在长序列梯度消失的问题,只使用最后一个时刻隐藏状态得到的向量 C 效果不理想。so加入了一种注意力机制,例如翻译 "欢迎来北京",翻译到 "welcome" 时,要将注意力放在源句子的 "欢迎" 上,翻译到 "beijing" 时要将注意力放在源句子的 "北京" 上。那他怎么关注到对应的词呢?就是拿decoder上一时刻的隐藏状态,与编码器的每个时刻的隐藏状态做attention计算,然后经过线性变换得到当前时刻的一个上下文向量C输入到当前时刻。如下图(晕乎乎的 不知道解释的对不对 希望指出错误)参考:Seq2Seq 模型知识总结 - 知乎 (zhihu.com)















 1349
1349











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









