







上一期从线程安全的角度聊了聊系统设计要注意的事情,这次换个角度继续聊聊系统设计
这次主题围绕系统设计:有状态、无状态
惯例,先看栗子
网站登录校验,很普通的一个功能
对于这个功能我们要如何实现?
先分析一下登录校验是个啥意思
举个栗子,比如我们在登陆页输入用户名密码,登录了社交网站
这时候想去看自己的新鲜事,却告诉我请先输入用户名密码进行验证。。
这时候想去吐槽下这个2B体验,发个新鲜事,点完发布按钮时,又弹出框说请输入用户名密码进行验证。。。这时候脑子里上千个草泥马奔腾而过
这样的产品可以说拜拜了
对我们的用户来说,登录操作其实完成一次就够了,后续的操作服务应该能够自动识别出是这个合法用户
因此,我们就需要对用户的状态进行记录,后续直接在后台里自动帮用户进行校验
OK,需求分析完了,那该怎么实现呢?
in the old time
我们直接通过session的方式,单机时代很方便,也够用了 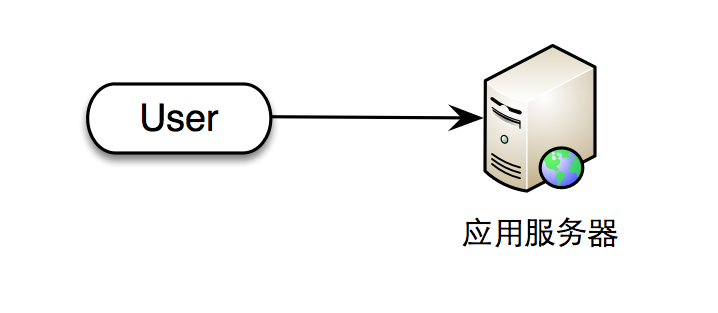
用户登录后我们通过session来保存,简单高效,done
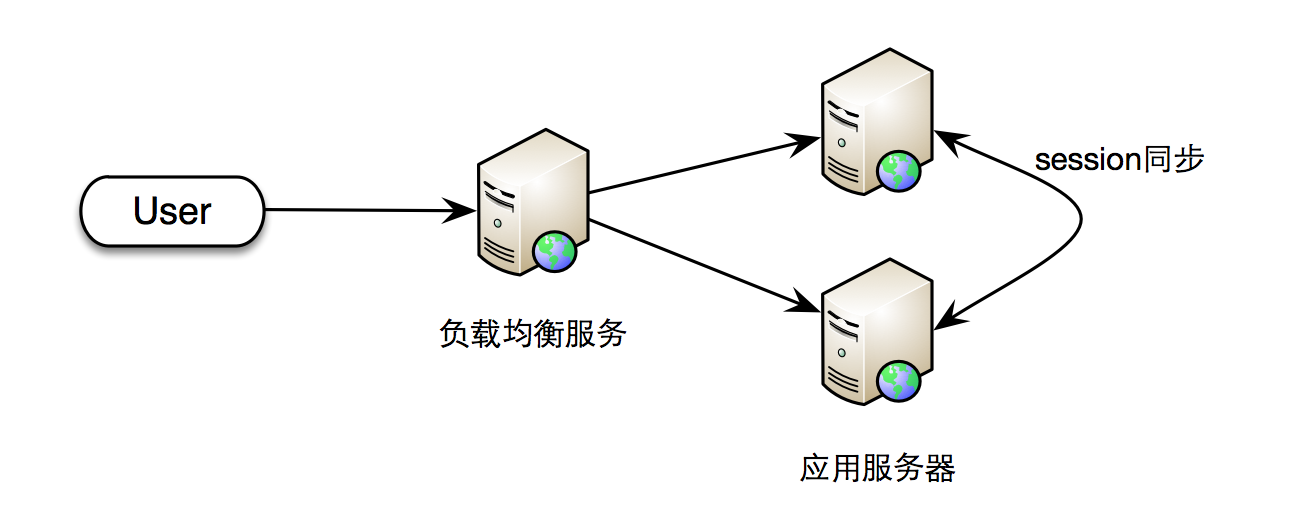
随着用户量和访问量的增大,单机似乎不够用了,加一台机器吧
这时候也引入了负载均衡服务,对应用服务器上的session也增加了同步的逻辑
比以前稍稍复杂了些,但也还好。但是如果用户量不断增加,访问量不断变多
继续加应用服务器,加一台,两台。。十台。。。?
这个session同步机制怎么保证依然快速有效?
这么大量的数据同步,带宽资源的消耗很可观啊
另外,N台应用服务器都有相同的session副本,这是对内存资源的极大糟蹋啊
那么有没有更加优雅的方案呢?
这里举一个方案
采用cookie + session服务器的方案
1.用户在登录页完成登录操作后,服务器会生成一个登录session信息,保存起来,设置个失效时间,并设置到用户的cookie里
2.用户后续的每次请求里会带着这个cookie信息,服务端会对这个cookie信息进行校验,通过了就认为是合法用户,执行请求操作
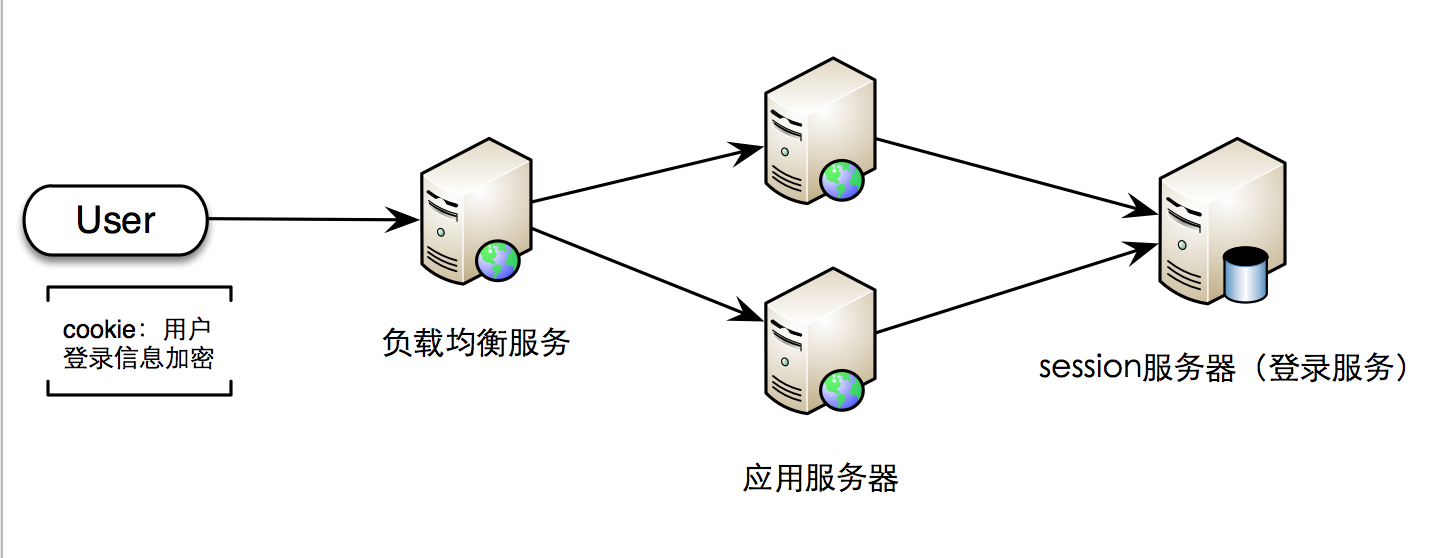
这个方案的好处比较明显
应用服务器变成无状态了,对session的统一管理由专门的服务来处理
引出了今天的主题:有状态和无状态
什么是有状态和无状态
这个话题结合系统设计,拿应用服务器来说会容易理解
像刚才介绍的,应用服务器里持有用户的session,这时应用服务器是有状态的
因为保存了用户会话这个上下文信息,后续的用户请求都会需要访问这个session信息
多个应用服务器之间是副本的关系,需要保持session数据的同步
无状态的应用服务器,像刚才把session挪出应用服务器,由专门的服务进行管理
此时应用服务器不保存上下文信息,只负责对用户的每次请求提交数据进行处理然后返回处理结果
无状态应用服务器之间是对等的关系,无依赖,请求到哪个服务器,处理结果都一样的
有状态的服务,会有比较明显的缺点,服务间数据需要同步,成为副本关系,逻辑复杂也浪费资源
相对来说,无状态的服务,就会简单多了
可以来做个比较
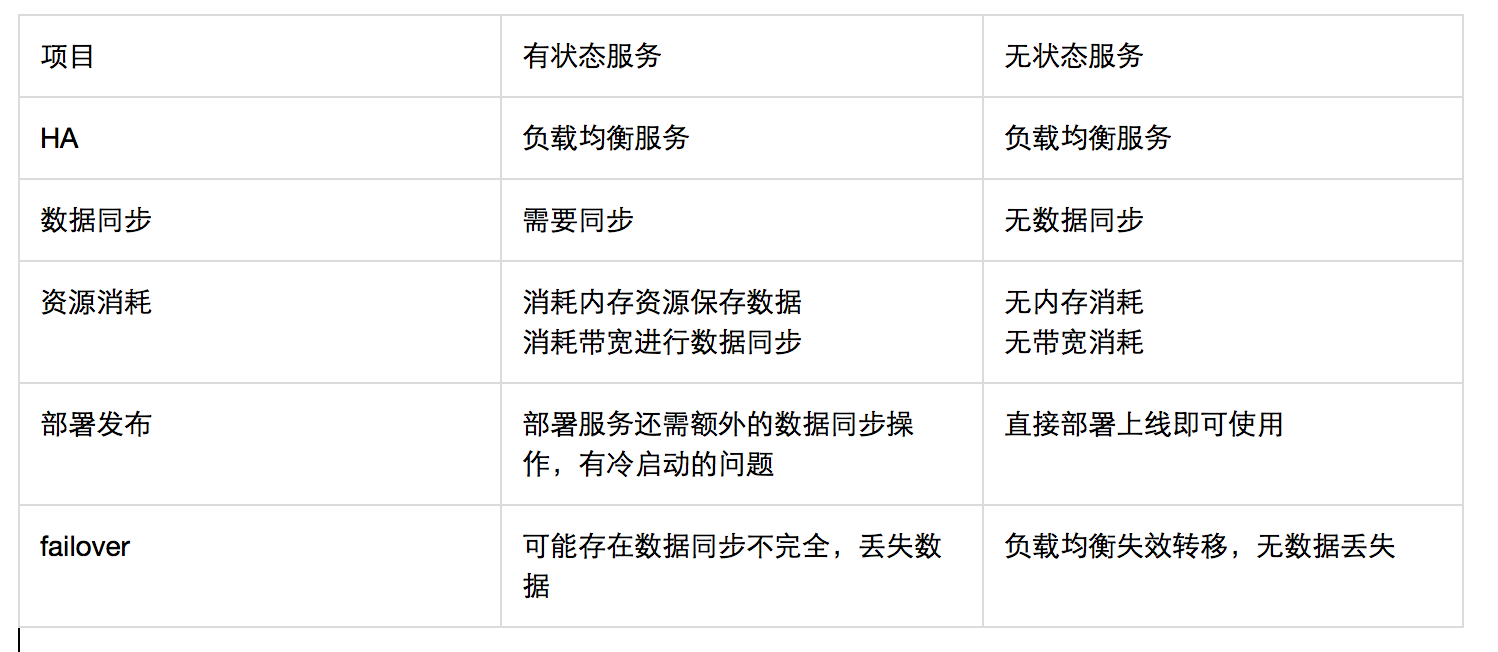
对于高可用服务的构建要求来说,快速failover以及快速扩容是非常重要的
服务有状态,服务当机就可能会存在数据丢失
关键是快速扩容,有状态服务会有冷启动的问题,还需要先加载数据才能对外提供服务,太麻烦了
所以大家在进行系统设计时,时刻要有这个意识,我们的应用服务器,要设计成无状态
不保存任何上下文信息
拓展学习: CAP理论
其实有状态服务也有其自身的好处,数据状态在服务中保存,无需额外的调用,低延迟
不需要额外的存储,服务本身已经存了
关于构建可伸缩的有状态服务,可以看下这篇文章的介绍
http://www.infoq.com/cn/news/2015/12/scaling-stateful-services
如果要构建有状态的服务,那就有必要了解CAP理论了
先看下维基百科对CAP的介绍:
In theoretical computer science, the CAP theorem also known as Brewer’s theorem, states that it is impossible for a distributed computer system to simultaneously provide all three of the following guarantees
- Consistency (all nodes see the same data at the same time)
- Availability (a guarantee that every request receives a response about whether it succeeded or failed)
- Partition tolerance (the system continues to operate despite arbitrary partitioning due to network failures)
大名鼎鼎的CAP理论的意思是说,一个分布式系统无法同时满足三个条件
一致性、可用性、分区容忍性
一致性,数据要保证一致,保证准确性
可用性,我们的服务要保证24小时可用
分区容忍性,访问量太大了,要扩容,体现为系统的可伸缩性了,部署多个实例或副本
但是呢,扩容了,保证了可用性,数据一致性怎么保证?
副本这么多,同步机制太难做好了。有个经典有趣的问题:拜占庭将军问题,感谢可以去了解
互联网公司一般会选择保证AP,保证高可用,但是一致性呢,该怎么办
CAP理论并不完全适用于指导实际的工程开发,所以对于一致性,一般会这样去考虑
强一致性,必须保证一致性,任意时刻都能读到最新值。这个,呵呵
弱一致性,写入新值后,在副本上可能读出来,也可能读不出来
最终一致性,在某个时间后,能够读到最新的值
CAP理论相关的知识涉及面比较广,大家感兴趣可以多看看,这里就先介绍到这里
左耳朵耗子有篇文章,对分布式系统的理论进行了些介绍,感兴趣可以看看
http://coolshell.cn/articles/10910.html
最后回到今天的主题,我们在系统设计上,遵循的原则还是简单为主
通过简单的设计来满足我们的业务需求
如何简单?非特殊情况,都设计成无状态的吧
最后再补充个题外话:
开头所讲的栗子里提到使用cookie,这个可能会存在安全的问题
比如XSS,跨站脚本攻击。可能会导致cookie信息被窃取,所以需要对XSS进行安全防护了
web安全又是一大块知识啊,感兴趣可以自己深入学习














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









