







交流群 | 进“传感器群/滑板底盘群/汽车基础软件群/域控制器群”请扫描文末二维码,添加九章小助手,务必备注交流群名称 + 真实姓名 + 公司 + 职位(不备注无法通过好友验证)

作者 | 张萌宇
自动驾驶战争的上半场拼的是硬件和算法,下半场拼的则是数据和将数据点石成金的能力,即数据闭环能力。
然而,笔者在跟业内人士的交流中了解到,目前,通过量产车大规模采集数据来支持自动驾驶系统迭代升级的设想尚未实现。有的公司尚未搭建好这样一套数据闭环的流程;有的公司虽然搭建好了流程,也已经采集了一些数据,但是由于数据闭环系统还不够先进,因而尚未将数据很好地用起来。
传统的自动驾驶数据闭环,存在着大量不够高效的部分。例如,几乎每家公司在数据标注环节都需要依靠“人海战术”,需要依靠人工一个个地对采集回来的数据做场景分类等。
幸运的是,我们处在一个技术快速更新的时代,随着深度学习技术的发展,尤其是,随着大模型的潜能逐步得到释放,人们很欣喜地发现,数据闭环中的很多环节都可以实现自动化或者半自动化,效率也会显著提升。
由于参数量大带来的容量优势,大模型的性能和泛化能力相比小模型显著提高。在数据预处理、数据标注等传统数据闭环中需要消耗大量人力且效率低下的环节,大模型的表现都可圈可点。很多公司都在积极探索,希望将大模型运用于数据闭环从而加速算法迭代。
大模型,或将助力数据闭环步入2.0时代(自动化程度低的时代可以称之为数据闭环“1.0”时代),从而影响到自动驾驶下半场的竞争态势。
然而,训练大模型需要大量的数据以及极高的算力,对底层的硬件设施以及AI研发平台都有很高的要求。
特斯拉为了打造一套效率高的数据闭环系统,还自研了DOJO超算中心,目前,特斯拉的Autopilot系统已收集了超过20.9亿公里的路采数据。在某种程度上,在数据闭环系统上的投入,是特斯拉得以在自动驾驶研发上大幅领先的原因之一。
然而,特斯拉这种做法的投入也是巨大的。据悉,2024年,特斯拉在DOJO超算上的投入将超过10亿美金。在国内,有这个财力的公司屈指可数。
那么,对国内的主机厂和自动驾驶公司来说,一个更可行的选择就是,上云,借助于云厂商开放出来的大模型能力、算力、工具链等基础设施及开发平台,快速步入数据闭环2.0时代。
尤其是,假如云厂商具备全栈自研能力,能提供一整套基础设施,那么主机厂和自动驾驶公司在使用时,就无需考虑不同公司提供的工具接口不一致等问题,可以减少很多适配的工作,从而进一步提高开发效率。
1. 大模型如何加速数据闭环2.0
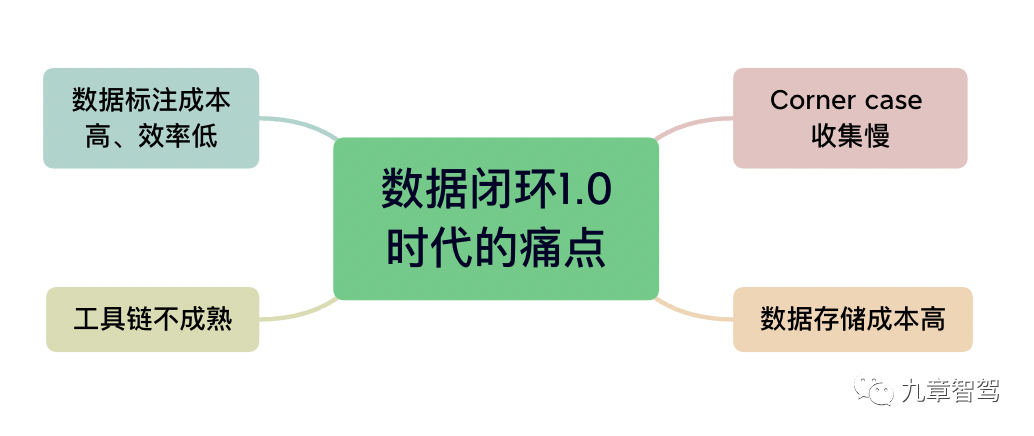
数据闭环1.0时代,人们还没有准备好应对自动驾驶系统研发对大量数据的需求,各个模块的自动化程度不够高,效率也不够高。
数据闭环2.0时代需要一套能快速处理大量数据的系统,让数据在系统内更快地流转,提高算法迭代的效率,让车越开越聪明。
在7.21华为云智能驾驶创新峰会上,华为云自动驾驶开发平台重磅发布,在盘古大模型的加持下,该平台在corner case的解决能力、数据预处理能力、数据挖掘能力、数据标注能力方面,相比于传统的数据闭环体系,都表现出了明显提升。
1.1 盘古大模型助力corner case的解决
传统解决corner case的方式主要是通过实车路采尽力采集到足够多的相关数据,然后训练模型,从而让模型具备应对能力。这种方式成本较高而且效率较低,更何况,很多特殊场景出现的频率特别低,实车很难采集到。
近年来,人们发现可
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1320
1320

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









