






背景
随着水下机器人的发展,水下图像增强引起了计算机视觉界越来越多的关注。然而,由于光线在水中传播时会被散射和吸收,水下捕捉到的图像往往存在偏色和能见度低的问题。现有的方法依赖于特定的先验知识和训练数据,在缺乏结构信息的情况下增强水下图像,结果效果不佳且不自然。
传统方法
在传统方法方面,常用的水下图像增强方法包括对数(或幂律)变换、对比度拉伸、直方图均衡化、锐化。这些方法可以有效拓宽图像的显示范围,实现对比度增强。但是,这些方法忽略了每个强度值的统计分布和位置信息,因此效果并不理想。随着深度学习的发展,现有的基于深度学习的方法通过领域或先验知识来增强水下图像,并达到较高的量化分数。但它们忽略了水下物体的颜色和结构信息。此外,这些基于数据驱动的方法依赖于数据信息。因此,在处理复杂的真实水下环境时,这些方法无法取得更好的性能。
提出的方法
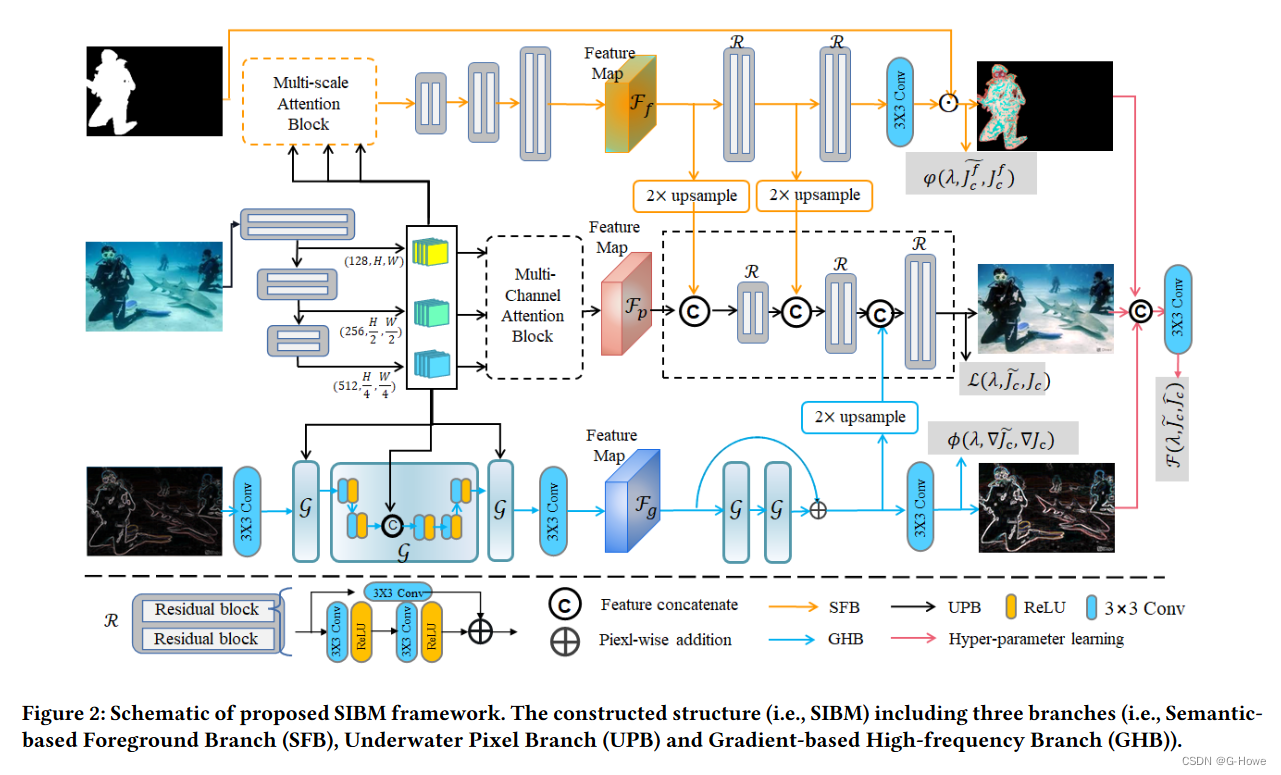
本文针对水下图像增强任务开发了一种具有分层增强网络的结构推断双层模型(命名为 SIBM),该网络由三个分支组成(即基于语义的前景分支(SFB)、基于梯度的高频分支(GHB)和水下像素分支(UPB))。所开发的方法采用了分层增强技术,可以利用图像到图像的转换技术来学习不同域之间的映射,即基于梯度域的高频域、基于语义域的前景目标域和基于像素域的图像域。
贡献
1)针对水下图像增强任务开发了一种结构引导的分层增强模型,该模型有三个分支(即 SFB、UPB 和 GHB),结合了不同的领域知识(即基于语义的领域、基于梯度的领域和基于像素的领域)。
2)设计了一个基于梯度的高频分支(即 GHB),利用梯度空间引导来保留纹理结构。为了避免背景颜色带来的不必要干扰,我们构建了基于语义的前景分支(SFB),以帮助我们的模型获得自然的水下图像。
3)通过输入语义和梯度信息来构建 UPB,以增强水下图像。为了利用不同领域的信息,我们进一步引入了超参数优化方案,以学习合适的超参数来融合上述三个领域的信息。
网络框架
该结构由三个分支组成。第一部分是基于语义的前景分支。第二部分是基于梯度的高频分支。第三部分是水下像素分支。
问题的提出
1)基于朦胧模型,退化图像可以通过以下模型进行建模:
![]()
Ic表示观测到的图像,Jc表示清晰图像,Ac表示均匀背景光,T𝑐(𝑥)=𝑒xp(−𝜷𝑑(𝑥))表示介质透射图,
其中d(x)表示像素x处的场景深度,𝜷表示水质的通道消光系数。
2)为了避免背景颜色造成不必要的干扰,我们引入了语义掩码 M,将水下图像分成两部分:前景图像![]() 和背景图像。且
和背景图像。且![]() ,其中 ◦ 表示点积。类似地,有
,其中 ◦ 表示点积。类似地,有![]() 。在这一模型下,我们采用以下方案同时优化
。在这一模型下,我们采用以下方案同时优化 ![]() 和 Jc:
和 Jc:![]() , L 和 φ 表示的损失函数。
, L 和 φ 表示的损失函数。
3)为了进一步改善水下图像的纹理结构,我们引入了一个利用梯度信息的最小化模型。
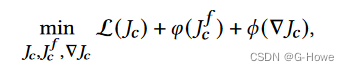
4)受双层优化模型的启发,我们将最小化问题重构为以下超参数优化形式:
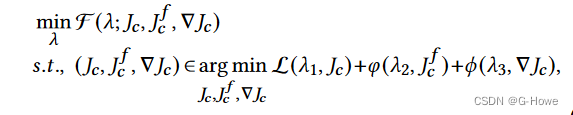
各个分支
1)基于语义的前景分支(SFB)
有目的地增强水下图像的目标区域。SFB 是一个由多个特征金字塔块组成的常规残差网络模块。通过多尺度注意力块,我们可以在六个残差块之后获得语义域中的特定前景特征![]() 。
。
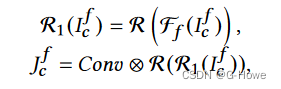
多尺度注意力块的具体流程如图所示
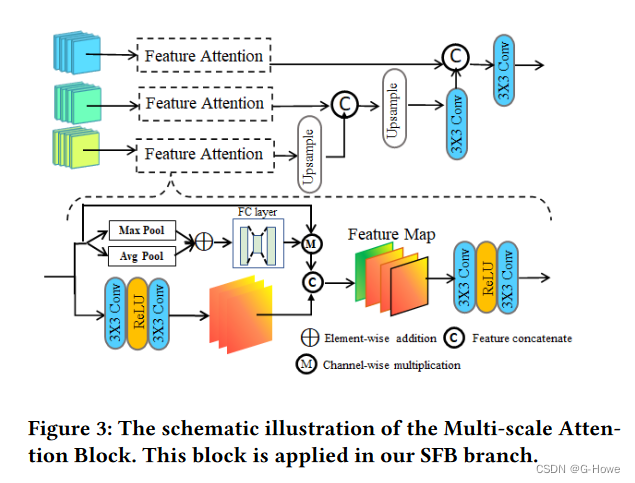
为了增强水下图像的客观性(即前景信息),我们引入 l2 范式来评估估计语义信息与参考信息之间的距离。因此,![]()
2)基于梯度的高频分支
目标是增强水下退化图像的细节信息。水下图像的梯度图是通过计算相邻像素之间的差值获得的。对于目标输入 Ic (x),高频结构 ∇Ic 定义为![]()
∇1Ic 和∇2Ic 代表两个垂直方向上的梯度。这两个梯度可以描述为 ∇1Ic = Ic (x1 + 1, x2) - Ic (x1 -1, x2) 和 ∇2Ic = Ic (x1, x2 +1) -Ic (x1, x2 -1) 。
在这一分支中,我们首先构建三个 u 型卷积块(记为 G),它们介于两个 3 × 3 卷积之间。估计的∇Jc 为![]()
![]()
为了使学习到的特征对细节结构有足够的表示能力,一般的策略是通过给定的损失函数迫使网络对正确的标签进行分类。我们使用 l1 损失作为目标函数。
![]()
3)水下像素分支(UPB)
基于水下像素的分支水下图像增强结构的基础部分。首先,为了挖掘不同尺度深度-纹理特征的分层特征,我们在该分支中采用了基于金字塔的多通道注意力块来估计初步像素特征 Fp。
多通道注意力块,沿用了SENet方案。
为了利用语义和梯度域信息,我们将语义和梯度产生的特征图以如下形式输入 UPB
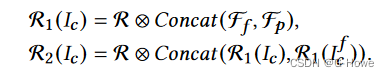
![]()
对于训练损失,我们使用 l2 损失和最常用的 SSIM 损失
3)通过![]() 输𝜌入𝜌
输𝜌入𝜌
𝜌代表l2损失和lssim损失的加权参数
至于 λ,我们设计了一种注意力机制来获得自适应映射,它可以直接从全局上下文中学习通道间信息,以学习一个合适的超参数来融合上述三个领域的信息,从而提高我们的性能。实际上,超参数机制能自动协调不同领域的信息,有助于提高网络的泛化能力。
在融合阶段,利用整体损失来保持融合图像更好的强度分布,其计算公式为
![]()
![]()
实施细节
数据集:
五个不同数据集的训练/测试图像数量和水下图像类型汇总。
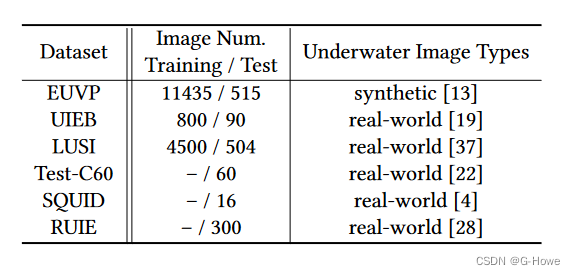
衡量标准:
峰值信噪比(PSNR)和结构相似性指数(SSIM),来评估不同方法的性能
为了进一步衡量真实世界水下图像的性能,我们引入了另外四个没有参考(即地面实况)图像的指标。引入了无参考水下图像质量测量(UIQM)、水下彩色图像质量评估(UCIQE)、自然图像质量评估器(NIQE)和感知分数(PS)来定量评估不同的方法。UCIQE、UIQM 或 PS 分数越高,表示人类的视觉感知能力越强。NIQE 分数越低,表示图像质量越好。
比较:
与一些最先进的方法进行了比较,包括传统方法(即 UDCP、Fusion)、基于 GAN 的方法(FUnIE-GAN 、UGAN 、Ucolor )、基于 CNN 的方法(WaterNet)和无监督方法(USUIR)。我们在合成和真实世界水下数据集上进行了定量和定性比较。
定量比较:
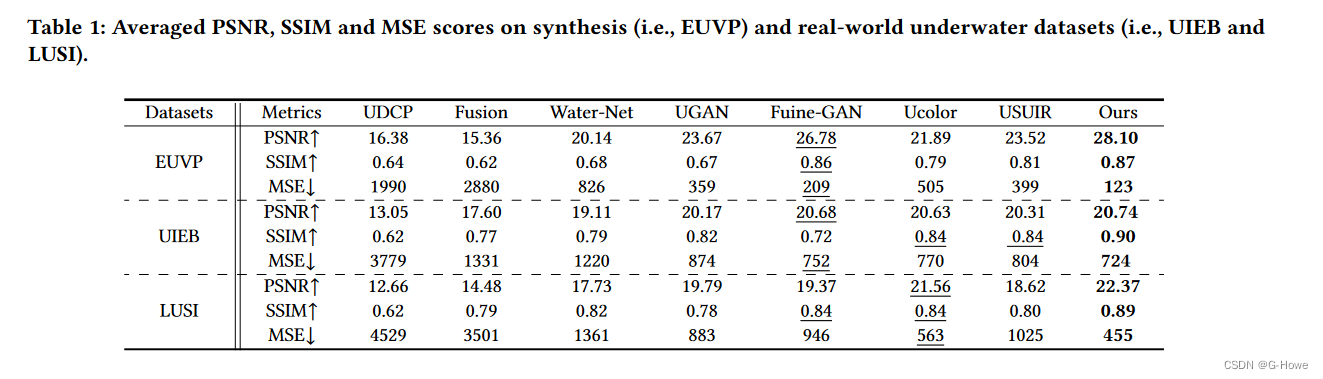
没有参考图像的情况下,对具有挑战性的真实世界水下数据集(即 Test-C60、SQUID 和 RUIE)进行了实验。
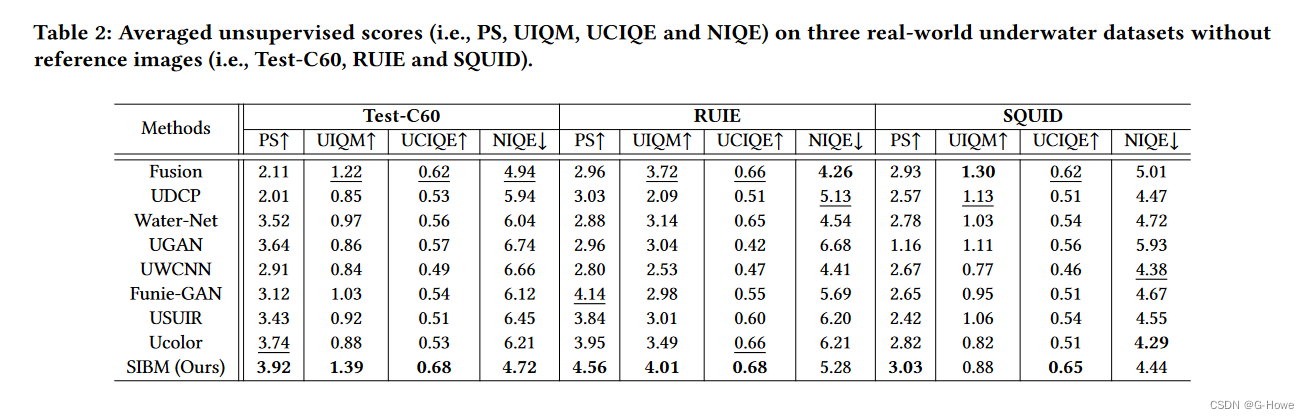
定性比较:


消融实验:
包括模型分支研究、损失函数的成分分析以及不同尺度和梯度策略的评估。
模型分支研究:
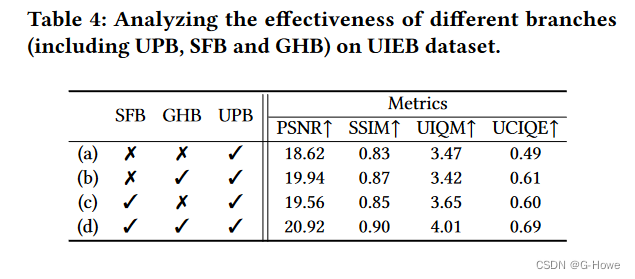
损失函数的成分分析:
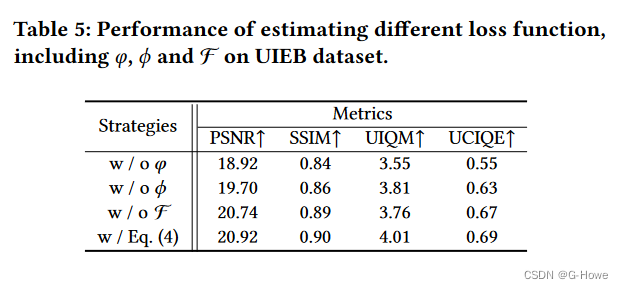
不同尺度和梯度策略的评估:
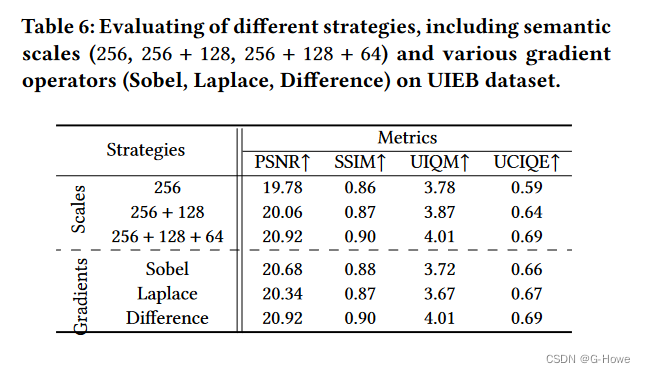















 1867
1867











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









