







本文,是摘录的学习笔记,书读一遍,需要招录一些核心的知识点,或者较难理解的知识点,下次在看的时候,就不需要子啊去翻书找了,总结之后,下次在看的时候,总是挑着关键点,效率也就高了。
- 本文主要摘录自《Tensorflow:实战Google深度学习框架》。
神经网络的优化算法,主要是两种反向传播算法(back propagation)和梯度下降算法(gradient decent)。这两种方法最终的目的都是调整网络中的参数信息。
- 梯度下降法主要是用于优化单个参数的取值,也就是说,每次对某个参数求偏导,根据求导信息,和学习率每次更新这一个参数的数值。
- 反向传播算法给出了一个高效的方式在所有参数上使用梯度下降算法,从而使神经网络模型在训练数据上的损失函数尽可能小。
梯度下降算法优化参数取值的过程
假设用θ 表示神经网络中的参数,J(θ )表示在给定的参数取值下,训练数据集上损失函数的大小,那么整个优化过程可以抽象为寻找一个参数θ ,使得J(θ )最小。
因为目前没有一个通用的方法可以对任意损失函数直接求解最佳的参数取值,所以在实践中,梯度下降算法是最常用的神经网络优化方法。梯度下降算法会迭代式更新参数θ ,不断沿着梯度的反方向让参数朝着总损失更小的方向更新。

什么时候,J(θ )最小呢,那就是上述函数波谷的位置,什么是梯度下降呢,就是沿着梯度(导数,或者说斜率)下降的方向移动。
假设当前的参数和损失值对应上图小圆点的位置,那么梯度下降算法会将参数向x 轴左侧移动,从而使得小圆点朝着箭头的
方向移动。参数的梯度可以通过求偏导的方式计算,对于参数θ ,其梯度为 J (θ )
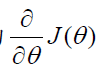
有了梯度,还需要定义一个学习率η(learning rate)来定义每次参数更新的幅度。
学习率,就是参数每个求偏导的过程减少多少,也就是输入参数的移动幅度。公式如下:
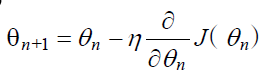
梯度下降算法是如何工作的。假设要通过梯度下降算法来优化参数x,使得损失函数J(x)=x^2
的值尽量小。梯度下降算法的第一步需要随机产生一个参数x 的初始值,然后再通过梯度和学习率来更新参数x 的取值。在这个样例中,参数x 的梯度为
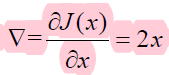
那么使用梯度下降算法每次对参数x 的更新公式为 xn+1= xn −η∇。假设参数的初始值为 5,学习率为 0.3,那么这个优化过程可以总结一下步骤:

偏导数 ∇,也就是图形上的斜率,斜率越大,η∇ 就越大, 也就是说,在坡度越陡的地方,下降的速度是更快的,等快到了最底部的时候,参数的每次移动的幅度是很小的,可以理解为,以更小的幅度试探性的前进。
总结
神经网络的优化过程可以分为两个阶段
- 第一个阶段先通过前向传播算法计算得到预测值,并将预测值和真实值做对比得出两者之间的差距。
- 第二个阶段通过反向传播算法计算损失函数对每一个参数的梯度,再根据梯度和学习率使用梯度下降算法更新每一个参数。
注意点
-
梯度下降算法并不能保证被优化的函数达到全局最优解
如下图所示

当优化到小黑点的位置的时候,梯度一直为0, 那么就参数就不会在继续更新了。这里最优解受到参数 x 落到那个区间的影响,如果落在图像的左边波谷,那么得到的就是最优解,落在右边就是得到的局部最优解。
而且只有当损失函数为凸函数的时候,梯度下降算法才能保证达到全局最优解。 -
梯度下降算法的另一个问题是计算太耗时因为要在全部训练数据上最小化损失,所以损失函数J (θ )是在所有训练数据上的损失和。这样在每一轮迭代中都需要计算在全部训练数据上的损失函数。在海量训练数据下,要计算所有训练数据的损失函数是非常消耗时间的。
-
为了加速训练过程,可以使用随机梯度下降的算法(stochastic gradient descent)。这个算法优化的不是在全部训练数据上的损失函数,而是在每一轮迭代中,随机优化某一条训练数据上的损失函数。这样每一轮参数更新的速度就大大加快了。因为随机梯度下降算法每次优化的只是某一条数据上的损失函数,所以它的问题也非常明显:在某一条数据上损失函数更小并不代表在全部数据上损失函数更小,于是使用随机梯度下降优化得到的神经网络甚至可能无法达到局部最优。
-
为了综合梯度下降算法和随机梯度下降算法的优缺点,在实际应用中一般采用这两个算法的折中——每次计算一小部分训练数据的损失函数。这一小部分数据被称之为一个batch。通过矩阵运算,每次在一个batch 上优化神经网络的参数并不会比单个数据慢太多。另一方面,每次使用一个batch 可以大大减小收敛所需要的迭代次数,同时可以使收敛到的结果更加接近梯度下降的效果。
学习率设置
学习率决定了参数每次更新的幅度。如果幅度过大,那么可能导致参数在极优值的两侧来回移动。当学习率过小时,虽然能保证收敛性,但是这会大大降低优化速度。我们会需要更多轮的迭代才能达到一个比较理想的优化效果。
综上所述,学习率既不能过大,也不能过小。为了解决设定
学习率的问题,TensorFlow 提供了一种更加灵活的学习率设置方法——指数衰减法。
tf.train.exponential_decay 函数实现了指数衰减学习率。通过这个函数,可以先使用较大的学
习率来快速得到一个比较优的解,然后随着迭代的继续逐步减小学习率,使得模型在训练后
期更加稳定。exponential_decay 函数会指数级地减小学习率,它实现了以下代码的功能:
decayed_learning_rate = \
learning_rate * decay_rate ^ (global_step / decay_ steps)
其中decayed_learning_rate 为每一轮优化时使用的学习率,learning_rate 为事先设定的
初始学习率,decay_rate 为衰减系数,decay_steps 为衰减速度。
衰减学习率如下图所示:

声明
本博客是个人学习时的一些笔记摘录和感想,不保证是为原创,内容汇集了网上相关资料和书记内容,在这之中也必有疏漏未加标注者,如有侵权请与博主联系















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









